Editor’s note: Today marks the first installment in a seven-part video and blog series from Google Developer Advocate Sandeep Dinesh on how to get the most out of your Kubernetes environment. Today he tackles the theory and practicalities of keeping your container images as small as possible.
Docker makes building containers a breeze. Just put a standard Dockerfile into your folder, run the docker ‘build’ command, and shazam! Your container image is built!
The downside of this simplicity is that it’s easy to build huge containers full of things you don’t need—including potential security holes.
In this episode of “Kubernetes Best Practices,” let’s explore how to create production-ready container images using Alpine Linux and the Docker builder pattern, and then run some benchmarks that can determine how these containers perform inside your Kubernetes cluster.
The process for creating containers images is different depending on whether you are using an interpreted language or a compiled language. Let’s dive in!
Containerizing interpreted languages
Interpreted languages, such as Ruby, Python, Node.js, PHP and others send source code through an interpreter that runs the code. This gives you the benefit of skipping the compilation step, but has the downside of requiring you to ship the interpreter along with the code.
Luckily, most of these languages offer pre-built Docker containers that include a lightweight environment that allows you to run much smaller containers.
Let’s take a Node.js application and containerize it. First, let’s use the “node:onbuild” Docker image as the base. The “onbuild” version of a Docker container pre-packages everything you need to run so you don’t need to perform a lot of configuration to get things working. This means the Dockerfile is very simple (only two lines!). But you pay the price in terms of disk size— almost 700MB!
FROM node:onbuild
EXPOSE 8080
Luckily, there is an official Alpine image for Node.js (as well as other popular languages) that has everything you need. Unlike the default “node” Docker image, “node:alpine” removes many files and programs, leaving only enough to run your app.
The Alpine Linux-based Dockerfile is a bit more complicated to create as you have to run a few commands that the onbuild image otherwise does for you.
FROM node:alpine
WORKDIR /app
COPY package.json /app/package.json
RUN npm install --production
COPY server.js /app/server.js
EXPOSE 8080
CMD npm start
Containerizing compiled languages
Compiled languages such as Go, C, C++, Rust, Haskell and others create binaries that can run without many external dependencies. This means you can build the binary ahead of time and ship it into production without having to ship the tools to create the binary such as the compiler.
With Docker’s support for multi-step builds, you can easily ship just the binary and a minimal amount of scaffolding. Let’s learn how.
Let’s take a Go application and containerize it using this pattern. First, let’s use the “golang:onbuild” Docker image as the base. As before, the Dockerfile is only two lines, but again you pay the price in terms of disk size—over 700MB!
FROM golang:onbuild
EXPOSE 8080
Again, creating the Dockerfile with an Alpine base image is a bit more complicated as you have to run a few commands that the onbuild image did for you.
FROM golang:alpine
WORKDIR /app
ADD . /app
RUN cd /app && go build -o goapp
EXPOSE 8080
ENTRYPOINT ./goappBut again, the resulting image is much smaller, weighing in at only 256MB!

Let’s use a multi-step build to take the binary created by the golang:alpine container and package it by itself.
FROM golang:alpine AS build-env
WORKDIR /app
ADD . /app
RUN cd /app && go build -o goapp
FROM alpine
RUN apk update && \
apk add ca-certificates && \
update-ca-certificates && \
rm -rf /var/cache/apk/*
WORKDIR /app
COPY --from=build-env /app/goapp /app
EXPOSE 8080
ENTRYPOINT ./goappWould you look at that! This container is only 12MB in size!

Note: If you want to save even more space, you could statically compile your app and use the “scratch” container. Using “scratch” as a base container means you are literally starting from scratch with no base layer at all. However, I recommend using Alpine as your base image rather than “scratch” because the few extra MBs in the Alpine image make it much easier to use standard tools and install dependencies.
Where to build and store your containers
In order to build and store the images, I highly recommend the combination of Google Container Builder and Google Container Registry. Container Builder is very fast and automatically pushes images to Container Registry. Most developers should easily get everything done in the free tier, and Container Registry is the same price as raw Google Cloud Storage (cheap!).
Platforms like Google Kubernetes Engine can securely pull images from Google Container Registry without any additional configuration, making things easy for you!
In addition, Container Registry gives you vulnerability scanning tools and IAM support out of the box. These tools can make it easier for you to secure and lock down your containers.
Evaluating performance of smaller containers
People claim that small containers’ big advantage is reduced time—both time-to-build and time-to-pull. Let’s test this, using containers created with onbuild, and ones created with Alpine in a multistage process!
TL;DR: No significant difference for powerful computers or Container Builder, but significant difference for smaller computers and shared systems (like many CI/CD systems). Small Images are always better in terms of absolute performance.
Building images on a large machine
For the first test, I am going to build using a pretty beefy laptop. I’m using our office WiFi, so the download speeds are pretty fast!
 |
Build:
Go Onbuild: 35 Seconds
Go Multistage: 23 SecondsThe next test is to push the containers to a remote registry. For this test, I used Container Registry to store the images.
Push:
Go Onbuild: 15 Seconds
Go Multistage: 14 SecondsFinally, I want to test how long it takes to pull the image from the registry to my local machine.
Pull:
Go Onbuild: 26 Seconds
Go Multistage: 6 SecondsYou can also build the containers in the cloud using Container Builder, which has the added benefit of automatically storing them in Container Registry.
Build + Push:
Go Onbuild: 25 Seconds
Go Multistage: 20 SecondsBuilding images on small machines
So is there an advantage for using smaller containers? If you have a powerful laptop with a fast internet connection and/or Container Builder, not really. However, the story changes if you’re using less powerful machines. To simulate this, I used a modest Google Compute Engine f1-micro VM to build, push and pull these images, and the results are staggering!
Pull:
Go Onbuild: 52 seconds
Go Multistage: 6 secondsGo Onbuild: 54 seconds
Go Multistage: 28 seconds
Push:
Go Onbuild: 48 Seconds
Go Multistage: 16 seconds
Pulling on Kubernetes
While you might not care about the time it takes to build and push the container, you should really care about the time it takes to pull the container. When it comes to Kubernetes, this is probably the most important metric for your production cluster.
For example, let’s say you have a three-node cluster, and one of the node crashes. If you are using a managed system like Kubernetes Engine, the system automatically spins up a new node to take its place.
However, this new node will be completely fresh, and will have to pull all your containers before it can start working. The longer it takes to pull the containers, the longer your cluster isn’t performing as well as it should!
This can occur when you increase your cluster size (for example, using Kubernetes Engine Autoscaling), or upgrade your nodes to a new version of Kubernetes (stay tuned for a future episode on this).
We can see that the pull performance of multiple containers from multiple deployments can really add up here, and using small containers can potentially shave minutes from your deployment times!
Security and vulnerabilities
Aside from performance, there are significant security benefits from using smaller containers. Small containers usually have a smaller attack surface as compared to containers that use large base images.
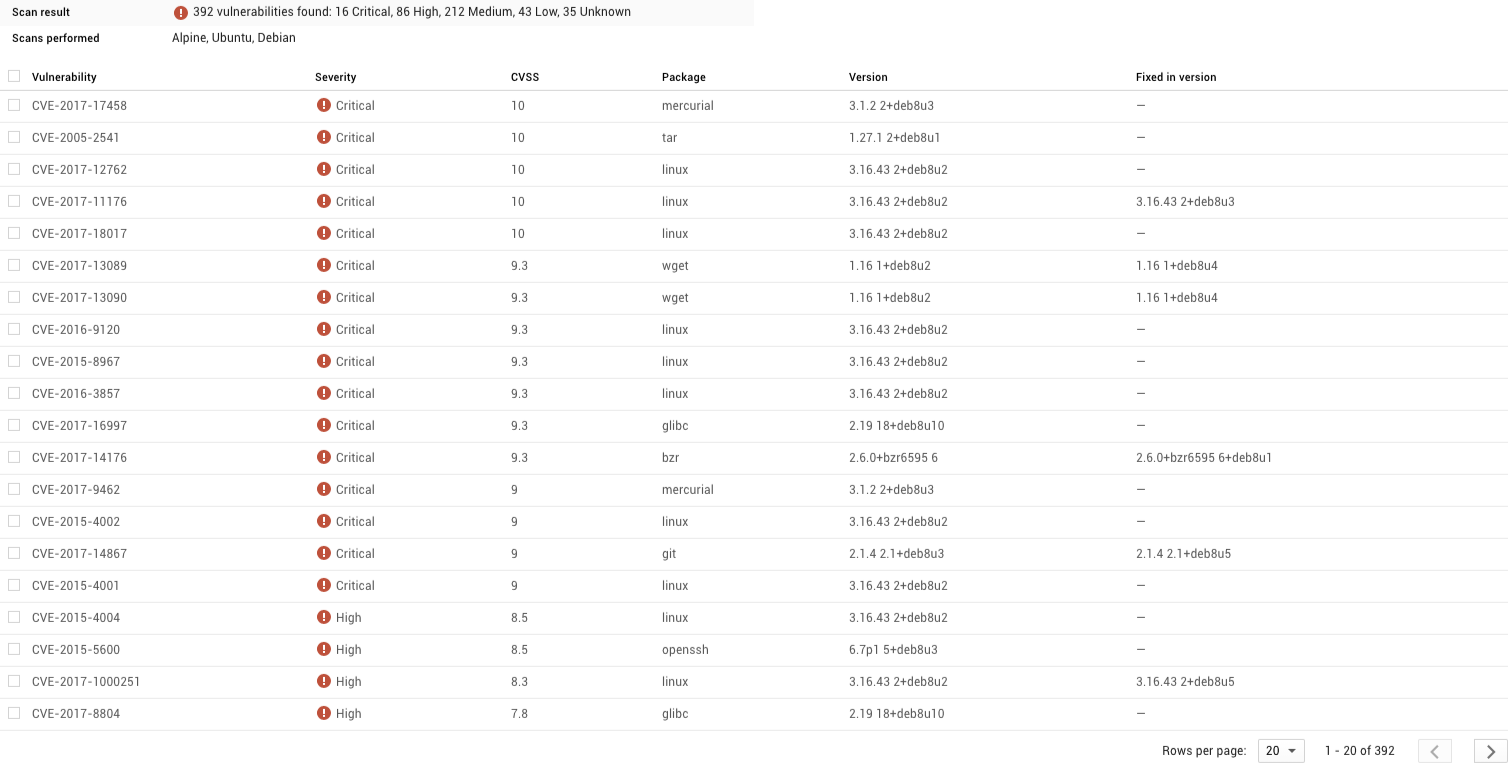
I built the Go “onbuild” and “multistage” containers a few months ago, so they probably contain some vulnerabilities that have since been discovered. Using Container Registry’s built-in Vulnerability Scanning, it’s easy to scan your containers for known vulnerabilities. Let’s see what we find.

Let’s drill down and see which issues the larger container has.
Conclusion
The performance and security advantages of using small containers speak for themselves. Using a small base image and the “builder pattern” can make it easier to build small images, and there are many other techniques for individual stacks and programming languages to minimize container size as well. Whatever you do, you can be sure that your efforts to keep your containers small are well worth it!Check in next week when we’ll talk about using Kubernetes namespaces to isolate clusters from one another. And don’t forget to subscribe to our YouTube channel and Twitter for the latest updates.
If you haven’t tried GCP and our various container services before, you can quickly get started with our $300 free credits.