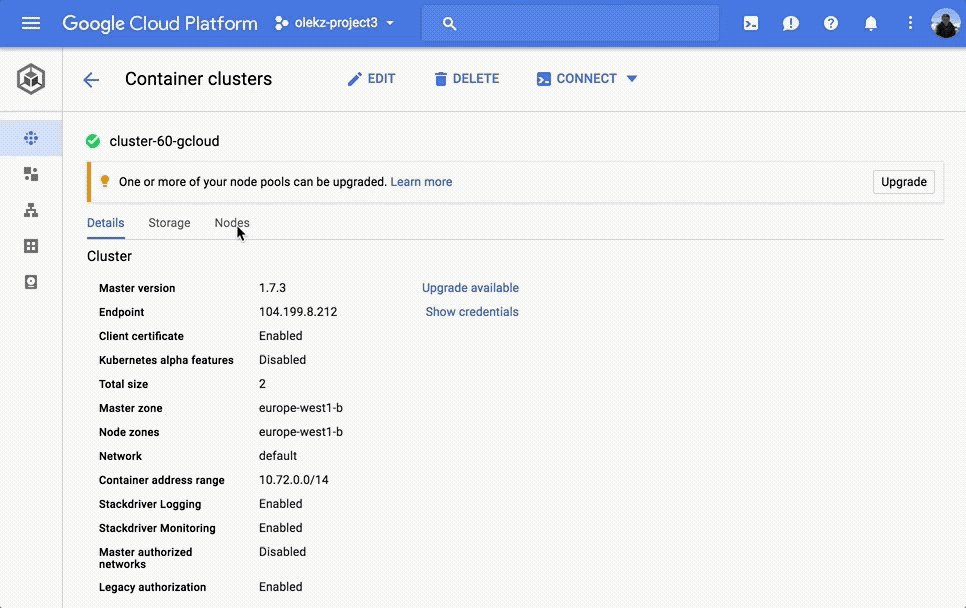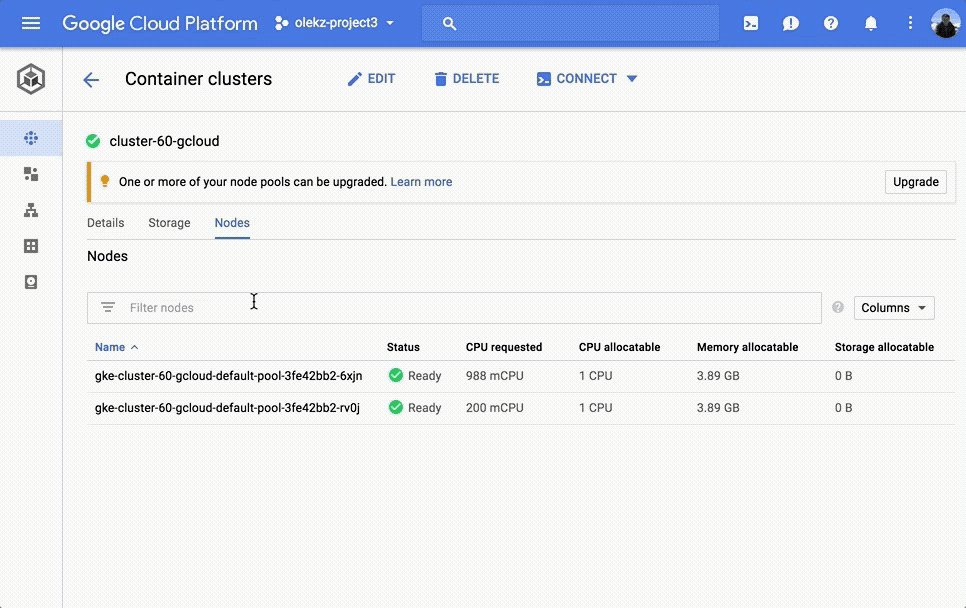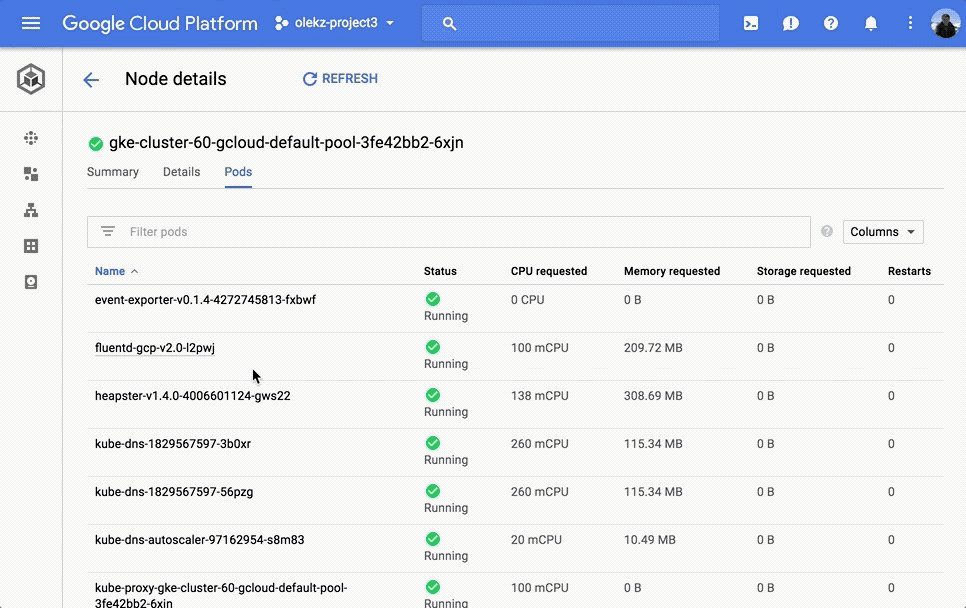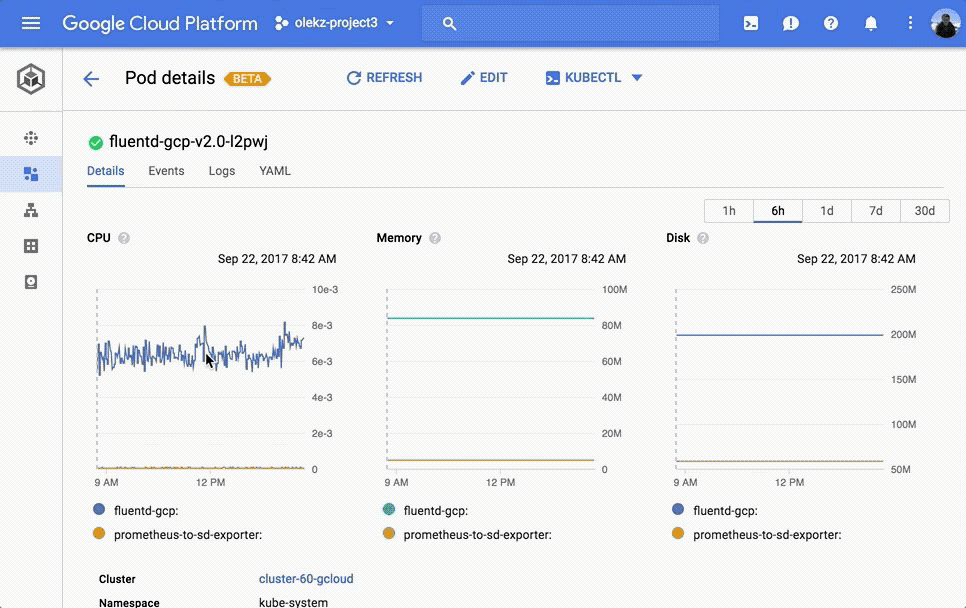
Securing applications in the cloud is critical for a variety of reasons: restricting access to trusted sources, protecting user data and limiting your application's bandwidth usage in the face of a DoS attack. The App Engine firewall lets you control access to your App Engine app through a set of rules, and is now generally available, ready to secure access to your production applications. Simply set up an application, provide a list of IP ranges to deny or allow, and App Engine does the rest.
With this release, you can now use the IPv4 and IPv6 address filtering capability in the App Engine firewall to enforce more comprehensive security policies rather than requiring developers to modify their application.
We have received lots of great feedback from our customers and partners about the security provided by the App Engine firewall, including Reblaze and Cloudflare:
"Thanks to the newly released App Engine firewall, Reblaze can now prevent even the most resourceful hacker from bypassing our gateways and accessing our customers’ App Engine applications directly. This new feature enables our customers to take advantage of Reblaze's comprehensive web security (including DDoS protection, WAF/IPS, bot mitigation, full remote management, etc.) on App Engine."
— Tzury Bar Yochay, CTO of Reblaze Technologies
"With the App Engine firewall, our customers can lock down their application to only accept traffic from Cloudflare IPs. Because Cloudflare uses a reverse-proxy server, this integration further prevents direct access to an application’s origin servers and allows Cloudflare to filter and block malicious activity."
— Travis Perkins, Head of Alliances at Cloudflare
Simple and effective
Getting started with the App Engine firewall is easy. You can set up rules in the Google Cloud Platform Console, via REST requests in the App Engine Admin API, or with our gcloud CLI.
For example, let's say you have an application that's being attacked by several addresses on a rogue network. First, get the IP addresses from your application’s request logs. Then, add a deny rule for the rogue network to the firewall. Make sure the default rule is set to allow so that other users can still access the application.

And that's it! No need to modify and redeploy the application; access is now restricted to your whitelisted IP addresses. The IP addresses that match a deny rule will receive an HTTP 403 request before the request reaches your app, which means that your app won't spin up additional instances or be charged for handling the request.
Verify rules for any IP
Some applications may have complex rulesets, making it hard to determine whether an IP will be allowed or denied. In the Cloud Console, the Test IP tab allows you to enter an IP and see if your firewall will allow or deny the request.

Here, we want to make sure an internal developer IP is allowed. However, when we test the IP, we can see that the "rogue net" blocking rule takes precedence.



We'd like to thank all you beta users who gave us feedback, and encourage anyone with questions, concerns or suggestions to reach out to us by reporting a public issue, posting in the App Engine forum, or messaging us on the App Engine slack channel.