By Mark Mandel, Developer Advocate
In the world of distributed systems, hosting and scaling dedicated game servers for online, multiplayer games presents some unique challenges. And while the game development industry has created a myriad of proprietary solutions, Kubernetes has emerged as the de facto open-source, common standard for building complex workloads and distributed systems across multiple clouds and bare metal servers. So today, we’re excited to announce
Agones (Greek for "contest" or "gathering"), a new open-source project that uses Kubernetes to host and scale dedicated game servers.
Currently under development in collaboration with interactive gaming giant
Ubisoft, Agones is designed as a batteries-included, open-source, dedicated game server hosting and scaling project built on top of Kubernetes, with the flexibility you need to tailor it to the needs of your multiplayer game.
The nature of dedicated game servers
It’s no surprise that game server scaling is usually done by proprietary software—most orchestration and scaling systems simply aren’t built for this kind of workload.
Many of the popular fast-paced online multiplayer games such as competitive
FPSs,
MMOs and
MOBAs require a dedicated game server—a full simulation of the game world—for players to connect to as they play within it. This dedicated game server is usually hosted somewhere on the internet to facilitate synchronizing the state of the game between players, but also to be the arbiter of truth for each client playing the game, which also has the benefit of safeguarding against players cheating.
Dedicated game servers are stateful applications that retain the full game simulation in memory. But unlike other stateful applications, such as databases, they have a short lifetime. Rather than running for months or years, a dedicated game server runs for a few minutes or hours.
Dedicated game servers also need a direct connection to a running game server process’ hosting IP and port, rather than relying on load balancers. These fast-paced games are extremely sensitive to latency, which a load balancer only adds more of. Also, because all the players connected to a single game server share the in-memory game simulation state at the same time, it’s just easier to connect them to the same machine.
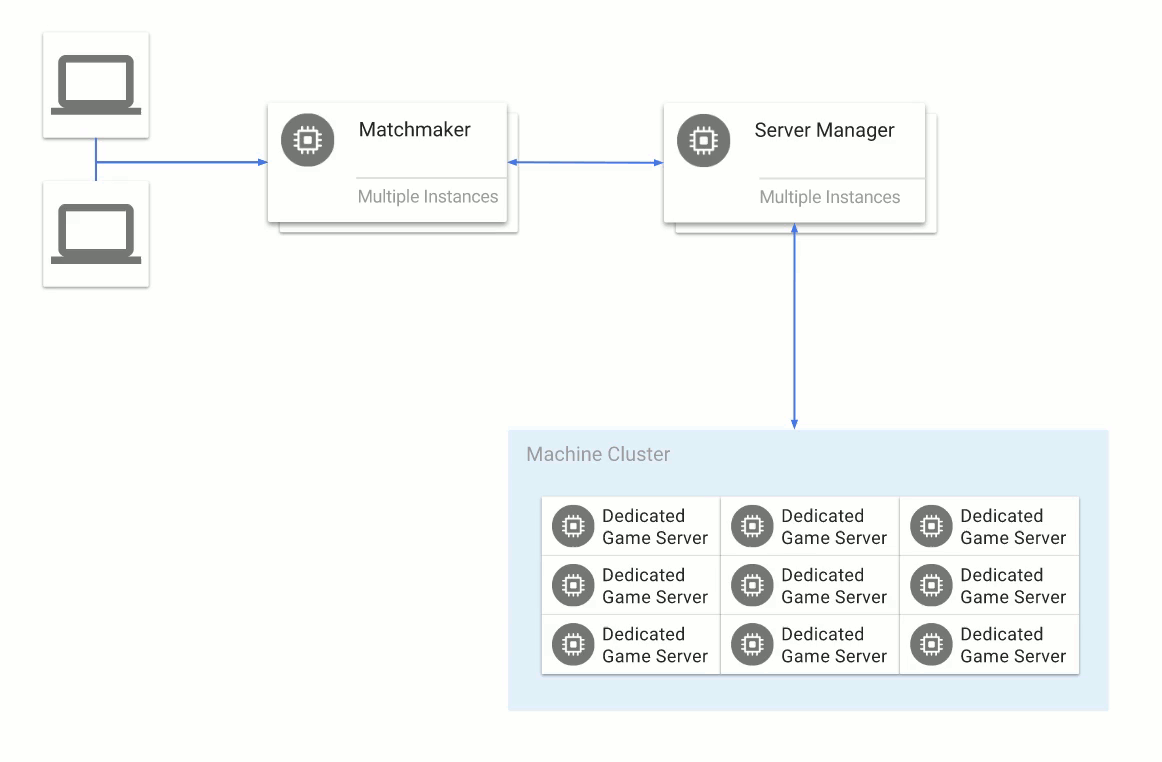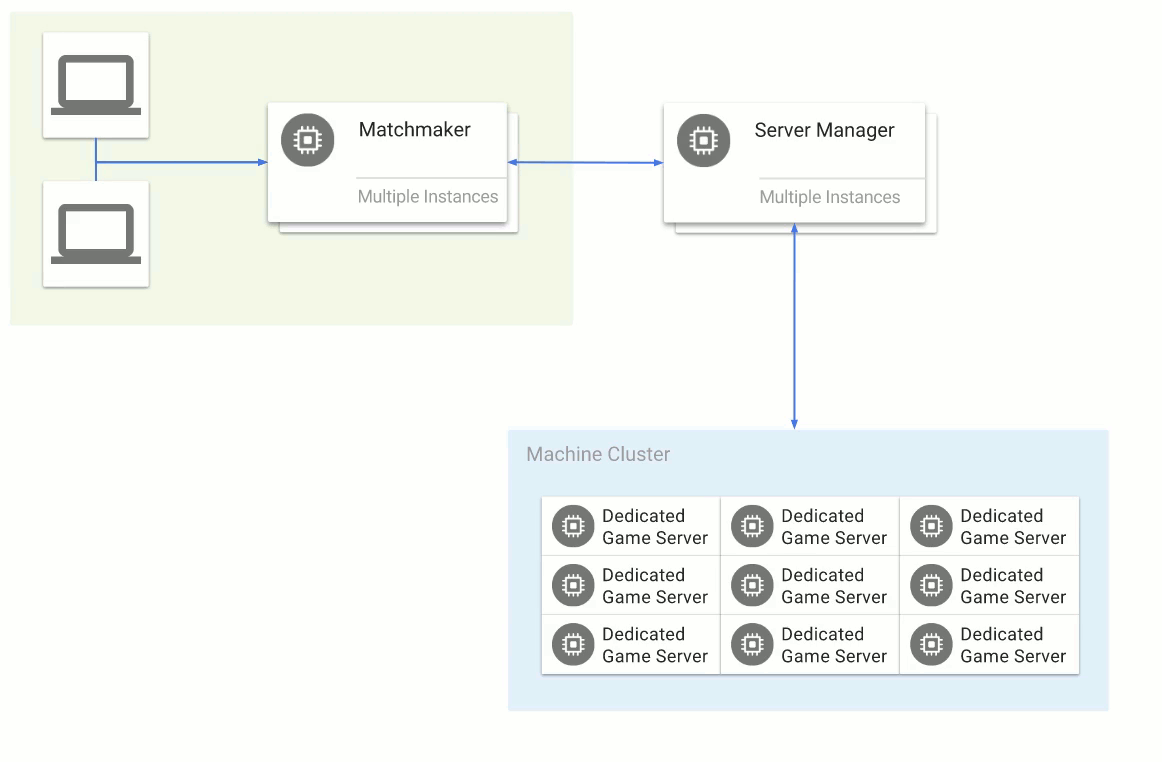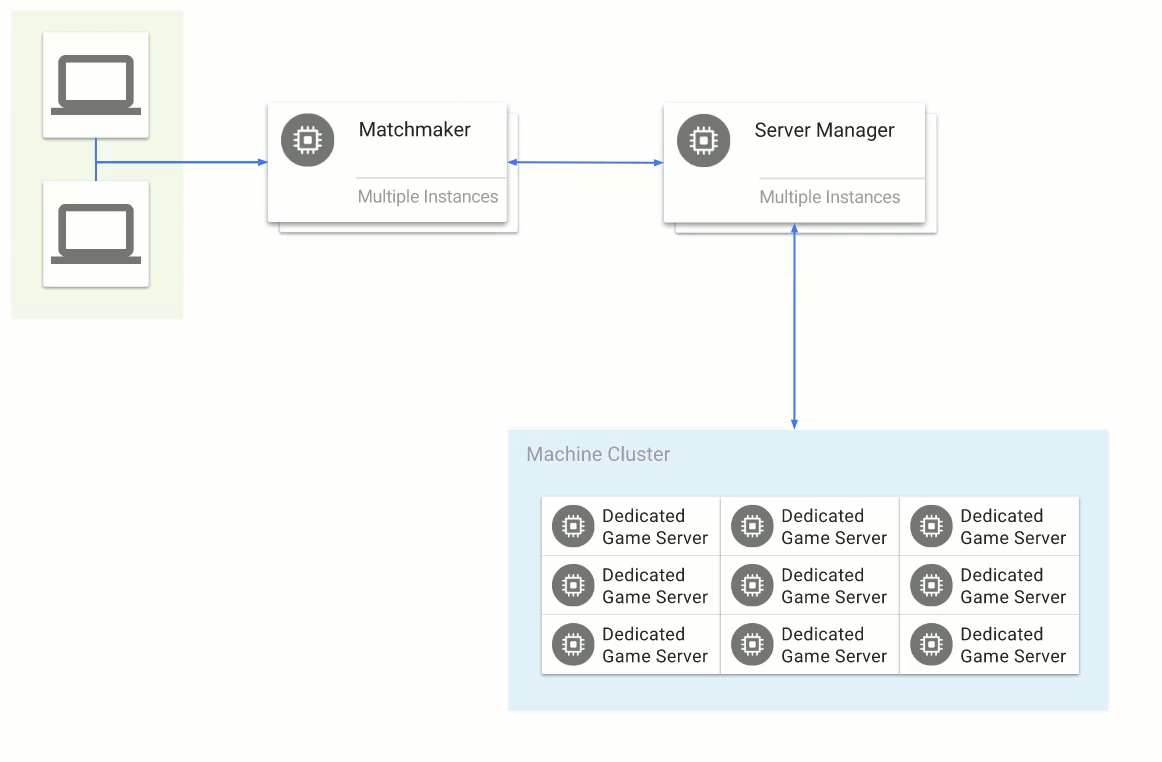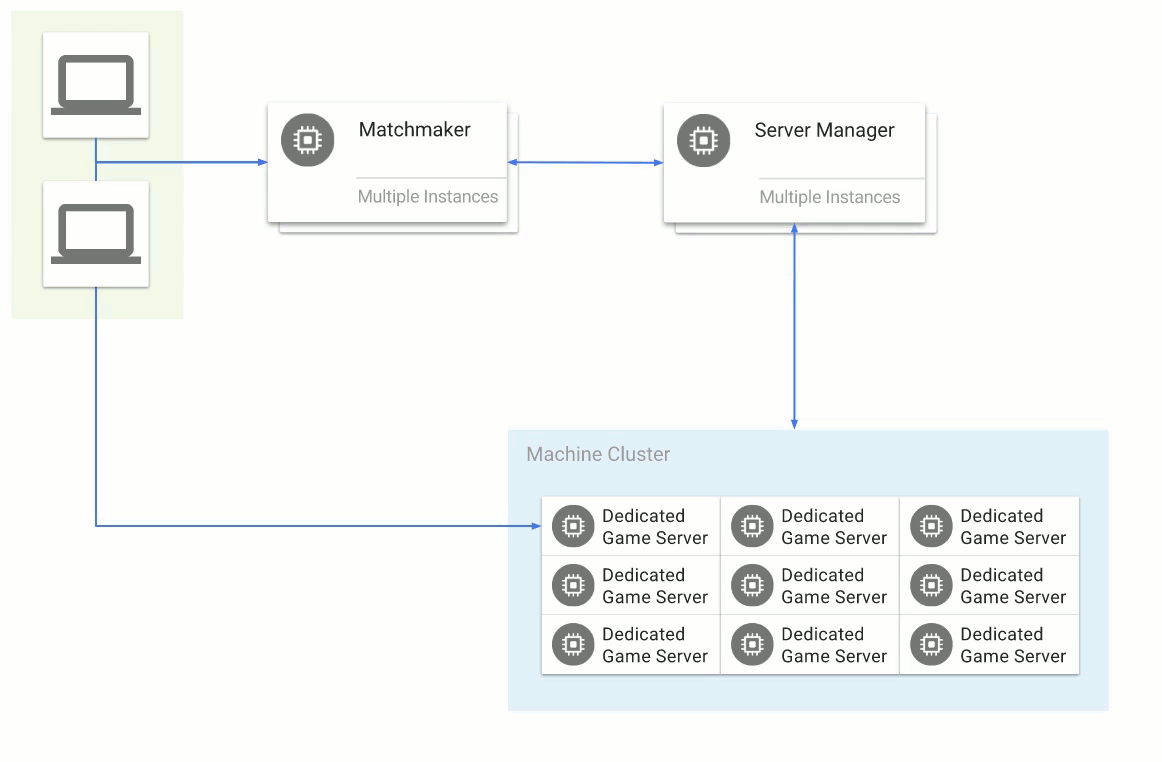
Here’s an example of a typical dedicated game server setup:
- Players connect to some kind of matchmaker service, which groups them (often by skill level) to play a match.
- Once players are matched for a game session, the matchmaker tells a game server manager to provide a dedicated game server process on a cluster of machines.
- The game server manager creates a new instance of a dedicated game server process that runs on one of the machines in the cluster.
- The game server manager determines the IP address and the port that the dedicated game server process is running on, and passes that back to the matchmaker service.
- The matchmaker service passes the IP and port back to the players’ clients.
- The players connect directly to the dedicated game server process and play the multiplayer game against one another.
Building Agones on Kubernetes and open-source
Agones replaces the bespoke cluster management and game server scaling solution we discussed above, with a Kubernetes cluster that includes a custom
Kubernetes Controller and matching
GameServer Custom Resource Definitions.
With Agones, Kubernetes gets native abilities to create, run, manage and scale dedicated game server processes within Kubernetes clusters using standard Kubernetes tooling and APIs. This model also allows any matchmaker to interact directly with Agones via the Kubernetes API to provision a dedicated a game server.
Building Agones on top of Kubernetes has lots of other advantages too: it allows you to run your game workloads wherever it makes the most sense, for example, on game developers’ machines via platforms like
minikube, in-studio clusters for group development, on-premises machines and on hybrid-cloud or full-cloud environments, including
Google Kubernetes Engine.
Kubernetes also simplifies operations. Multiplayer games are never just dedicated game servers—there are always supporting services, account management, inventory, marketplaces etc. Having Kubernetes as a single platform that can run both your supporting services as well as your dedicated game servers drastically reduces the required operational knowledge and complexity for the supporting development team.
Finally, the people behind Agones aren’t just one group of people building a game server platform in isolation. Agones, and the developers that use it, leverages the work of hundreds of Kubernetes contributors and the diverse ecosystem of tools that have been built around the Kubernetes platform.
Founding contributor to the Agones project, Ubisoft brought their deep knowledge and expertise in running top-tier,
AAA multiplayer games for a global audience.
“Our goal is to continually find new ways to provide the highest-quality, most seamless services to our players so that they can focus on their games. Agones helps by providing us with the flexibility to run dedicated game servers in optimal datacenters, and by giving our teams more control over the resources they need. This collaboration makes it possible to combine Google Cloud’s expertise in deploying Kubernetes at scale with our deep knowledge of game development pipelines and technologies.”
— Carl Dionne, Development Director, Online Technology Group, Ubisoft.
Getting started with Agones
Since Agones is built with Kubernetes’ native extensions, you can use all the standard Kubernetes tooling to interact with it, including
kubectl and the Kubernetes API.
Creating a GameServer
Authoring a dedicated game server to be deployed on Kubernetes is similar to developing a more traditional Kubernetes workload. For example, the dedicated game server is simply built into a container image like so:
Dockerfile
FROM debian:stretch
RUN useradd -m server
COPY ./bin/game-server /home/server/game-server
RUN chown -R server /home/server && \
chmod o+x /home/server/game-server
USER server
ENTRYPOINT ["/home/server/game-server"]
By installing Agones into Kubernetes, you can add a
GameServer resource to Kubernetes, with all the configuration options that also exist for a Kubernetes Pod.
gameserver.yaml
apiVersion: "stable.agon.io/v1alpha1"
kind: GameServer
metadata:
name: my-game-server
spec:
containerPort: 7654
# Pod template
template:
spec:
containers:
- name: my-game-server-container
image: gcr.io/agon-images/my-game-server:0.1
You can then apply it through the
kubectl command or through the Kubernetes API:
$ kubectl apply -f gamesever.yaml
gameserver "my-game-server" created
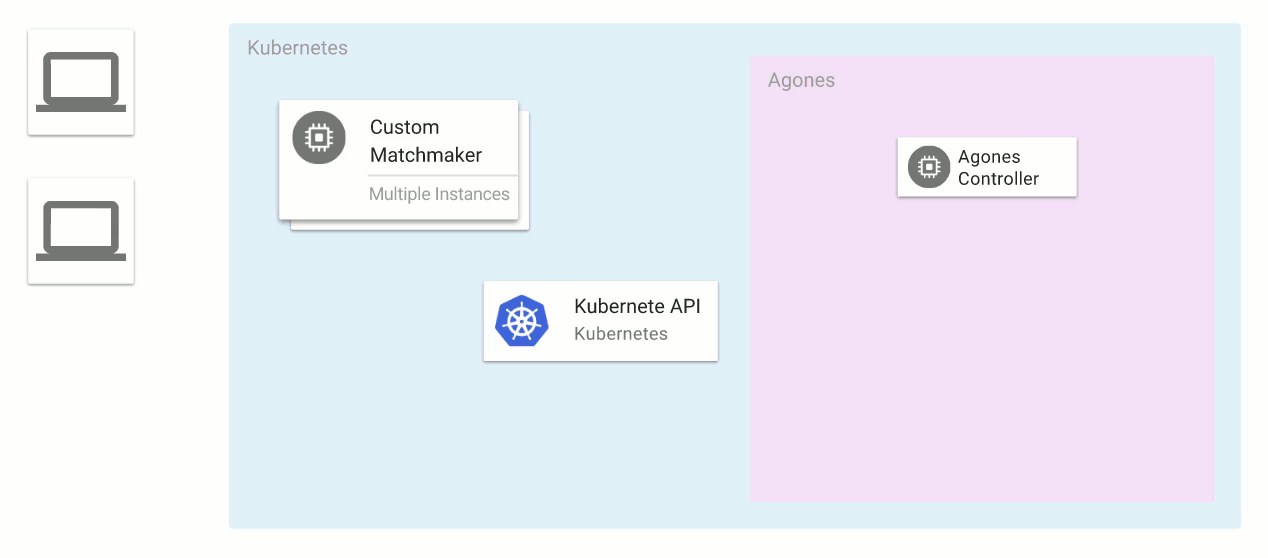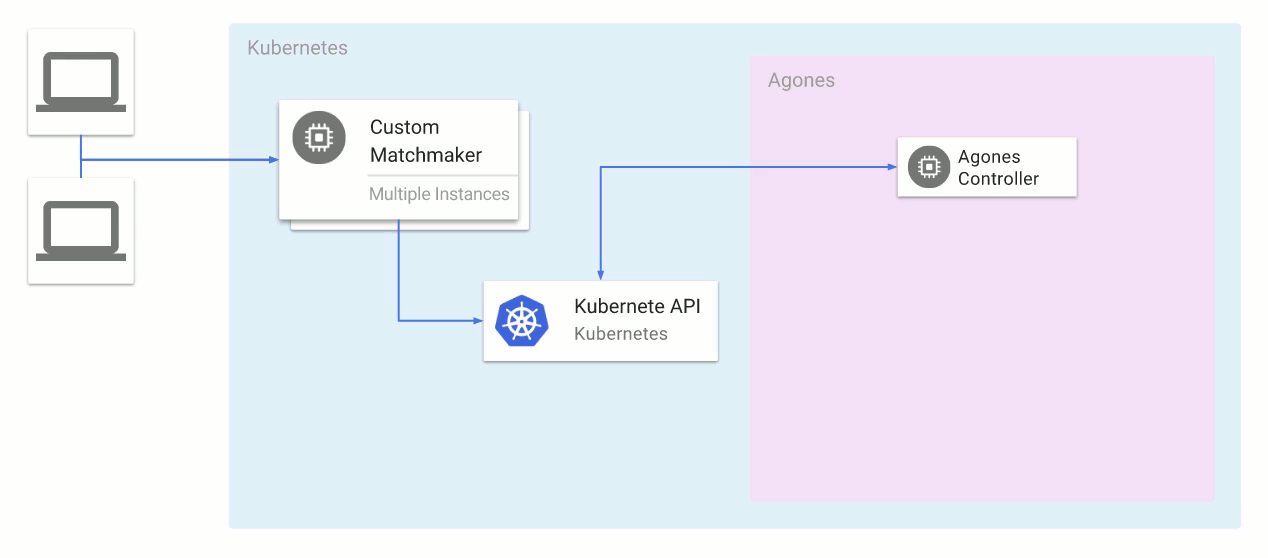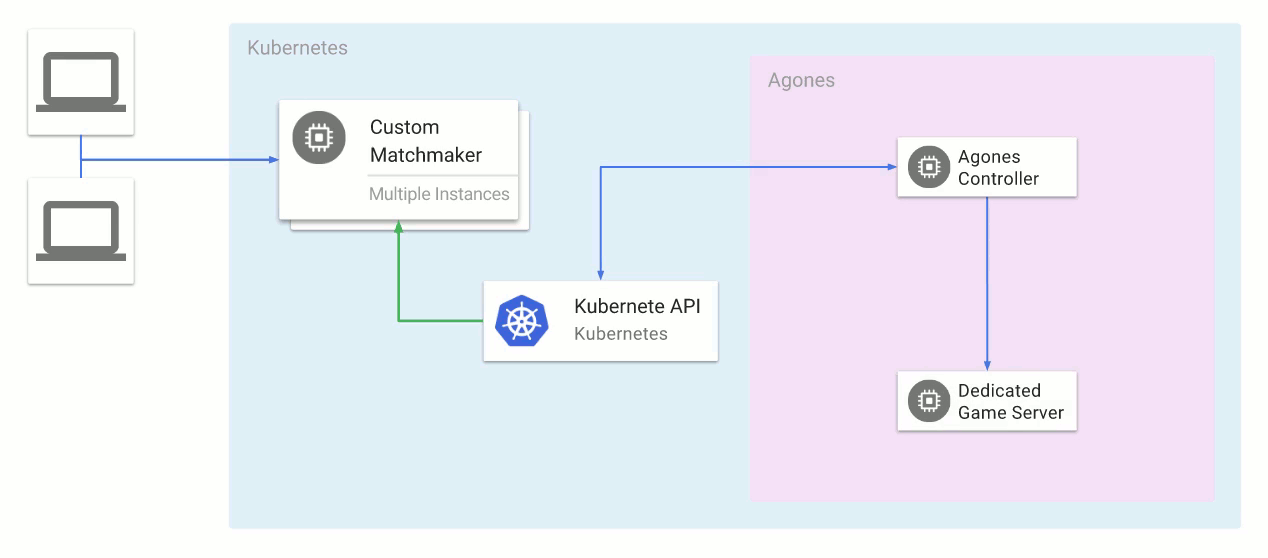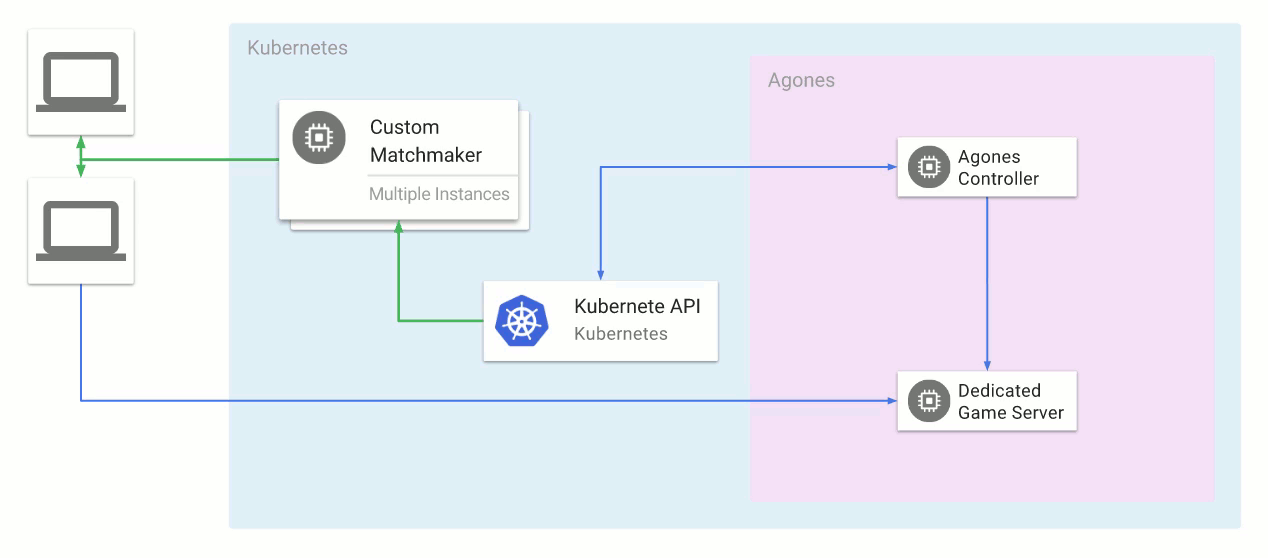
Agones manages starting the game server process defined in the yaml, assigning it a public port, and retrieving the IP and port so that players can connect to it. It also tracks the lifecycle and health of the configured
GameServer through an SDK that's integrated into the game server process code.
You can query Kubernetes to get details about the
GameServer, including its
State, and the IP and port that player game clients can connect to, either through
kubectl or the Kubernetes API:
$ kubectl describe gameserver my-game-server
Name: my-game-server
Namespace: default
Labels:
Annotations:
API Version: stable.agones.dev/v1alpha1
Kind: GameServer
Metadata:
Cluster Name:
Creation Timestamp: 2018-02-09T05:02:18Z
Finalizers:
stable.agones.dev
Generation: 0
Initializers:
Resource Version: 13422
Self Link: /apis/stable.agones.dev/v1alpha1/namespaces/default/gameservers/my-game-server
UID: 6760e87c-0d56-11e8-8f17-0800273d63f2
Spec:
Port Policy: dynamic
Container: my-game-server-container
Container Port: 7654
Health:
Failure Threshold: 3
Initial Delay Seconds: 5
Period Seconds: 5
Host Port: 7884
Protocol: UDP
Template:
Metadata:
Creation Timestamp:
Spec:
Containers:
Image: gcr.io/agones-images/my-game-server:0.1
Name: my-game-server-container
Resources:
Status:
Address: 192.168.99.100
Node Name: agones
Port: 7884
State: Ready
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal PortAllocation 3s gameserver-controller Port allocated
Normal Creating 3s gameserver-controller Pod my-game-server-q98sz created
Normal Starting 3s gameserver-controller Synced
Normal Ready 1s gameserver-controller Address and Port populated
What’s next for Agones
Agones is still in very early stages, but we’re very excited about its future! We’re already working on new features like game server Fleets, planning a v0.2 release and working on a roadmap that includes support for Windows, game server statistic collection and display, node autoscaling and more.
If you would like to try out a v0.1 alpha release of Agones, you can install it directly on a Kubernetes cluster such as GKE or minikube and take it for a spin. We have a great installation guide that will take you through getting setup!
And we would love your help! There are multiple ways to get involved:
Thanks to everyone has been involved in the project so far across Google Cloud Platform and Ubisoft, we're very excited for the future of Agones!