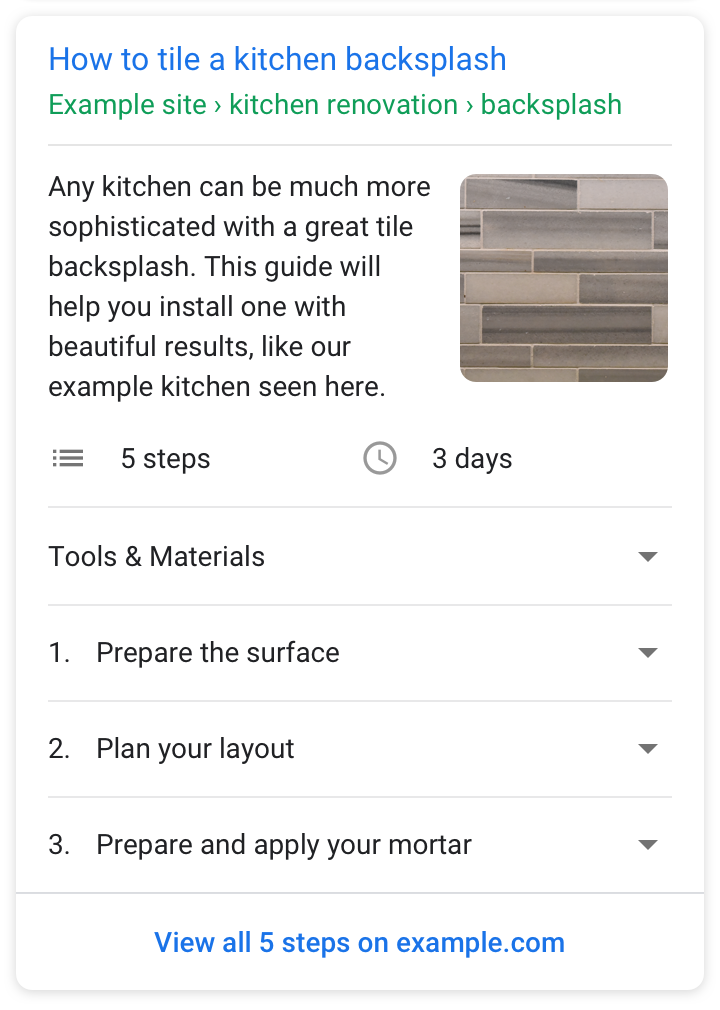
For 25 years, the Robots Exclusion Protocol (REP) was only a de-facto standard. This had frustrating implications sometimes. On one hand, for webmasters, it meant uncertainty in corner cases, like when their text editor included BOM characters in their robots.txt files. On the other hand, for crawler and tool developers, it also brought uncertainty; for example, how should they deal with robots.txt files that are hundreds of megabytes large?

Today, we announced that we're spearheading the effort to make the REP an internet standard. While this is an important step, it means extra work for developers who parse robots.txt files.
We're here to help: we open sourced the C++ library that our production systems use for parsing and matching rules in robots.txt files. This library has been around for 20 years and it contains pieces of code that were written in the 90's. Since then, the library evolved; we learned a lot about how webmasters write robots.txt files and corner cases that we had to cover for, and added what we learned over the years also to the internet draft when it made sense.
We also included a testing tool in the open source package to help you test a few rules. Once built, the usage is very straightforward:
If you want to check out the library, head over to our GitHub repository for the robots.txt parser. We'd love to see what you can build using it! If you built something using the library, drop us a comment on Twitter, and if you have comments or questions about the library, find us on GitHub.
Posted by Edu Pereda, Lode Vandevenne, and Gary, Search Open Sourcing team

Today, we announced that we're spearheading the effort to make the REP an internet standard. While this is an important step, it means extra work for developers who parse robots.txt files.
We're here to help: we open sourced the C++ library that our production systems use for parsing and matching rules in robots.txt files. This library has been around for 20 years and it contains pieces of code that were written in the 90's. Since then, the library evolved; we learned a lot about how webmasters write robots.txt files and corner cases that we had to cover for, and added what we learned over the years also to the internet draft when it made sense.
We also included a testing tool in the open source package to help you test a few rules. Once built, the usage is very straightforward:
robots_main <robots.txt content> <user_agent> <url>If you want to check out the library, head over to our GitHub repository for the robots.txt parser. We'd love to see what you can build using it! If you built something using the library, drop us a comment on Twitter, and if you have comments or questions about the library, find us on GitHub.
Posted by Edu Pereda, Lode Vandevenne, and Gary, Search Open Sourcing team