Alex Gough, Engineer, Chrome Platform Security TeamChrome 90 for Windows adopts Hardware-enforced Stack Protection, a mitigation technology to make the exploitation of security bugs more difficult for attackers. This is supported by Windows 20H1 (December Update) or later, running on processors with Control-flow Enforcement Technology (CET) such as Intel 11th Gen or AMD Zen 3 CPUs. With this mitigation the processor maintains a new, protected, stack of valid return addresses (a shadow stack). This improves security by making exploits more difficult to write. However, it may affect stability if software that loads itself into Chrome is not compatible with the mitigation. Below we describe some exploitation techniques that are mitigated by stack protection, discuss its limitations and what we will do next to approach them. Finally, we provide some quick tips for other software authors as they enable /cetcompat for their Windows applications.
Stack Protection
Imagine a simple use-after-free (UAF) bug where an attacker can induce a program to call a pointer of their choosing. Here the attacker controls an object which occupies space formerly used by another object, which the program erroneously continues to use. The attacker sets a field in this region that is used as a function call to the address of code the attacker would like to execute. Years ago an attacker could simply write their shellcode to a known location, then, in their overwrite, set the instruction pointer to this shellcode. In time, Data Execution Prevention was added to prevent stacks or heaps from being executable.
In response, attackers invented Return Oriented Programming (ROP). Here, attackers take advantage of the process’s own code, as that must be executable. With control of the stack (either to write values there, or by changing the stack pointer) and control of the instruction pointer, an attacker can use the `ret` instruction to jump to a different, useful, piece of code.
During an exploit attempt, the instruction pointer is changed so that instead of its normal destination, a small fragment of code, called an ROP gadget, is invoked instead. These gadgets are selected so that they do something useful (such as prepare a register for a function call) then call return.
These tiny fragments need not be a complete function in the normal program, and could even be found part-way through a legitimate instruction. By lining up the right set of “return” addresses, a chain of these gadgets can be called, with each gadget’s `ret` switching to the next gadget. With some patience, or the right tooling, an attacker can piece together the arguments to a function call, then really call the function.
Chrome has a multi-process architecture -- a main browser process acts as the logged-in user, and spawns restricted renderer and utility processes to host website code. This isolation reduces the severity of a bug in a renderer as its process cannot do much by itself. Attackers will then attempt to use another sandbox escape bug to run code in the browser, which lets them act as the logged-in user. As libraries are mapped at the same address in different processes by Windows, any bug that allows an attacker to read memory is enough for them to examine Chrome’s binary and any loaded libraries for ROP gadgets. This makes preventing ROP chains in the browser process especially useful as a mitigation.
Enter stack-protection. Along with the existing stack, the cpu maintains a shadow stack. This stack cannot be directly manipulated by normal program code and only stores return addresses. The CALL instruction is modified to push a return address (the instruction after the CALL) to both the normal stack, and the shadow stack. The RET (return) instruction still takes its return address from the normal stack, but now verifies that it is the same as the one stored in the shadow stack region. If it is, then the program is left alone and it continues to work as it always did. If the addresses do not match then an exception is raised which is intercepted by the operating system (not by Chrome). The operating system has an opportunity to modify the shadow region and allow the program to continue, but in most cases an address mismatch is the result of a program error so the program is immediately terminated.
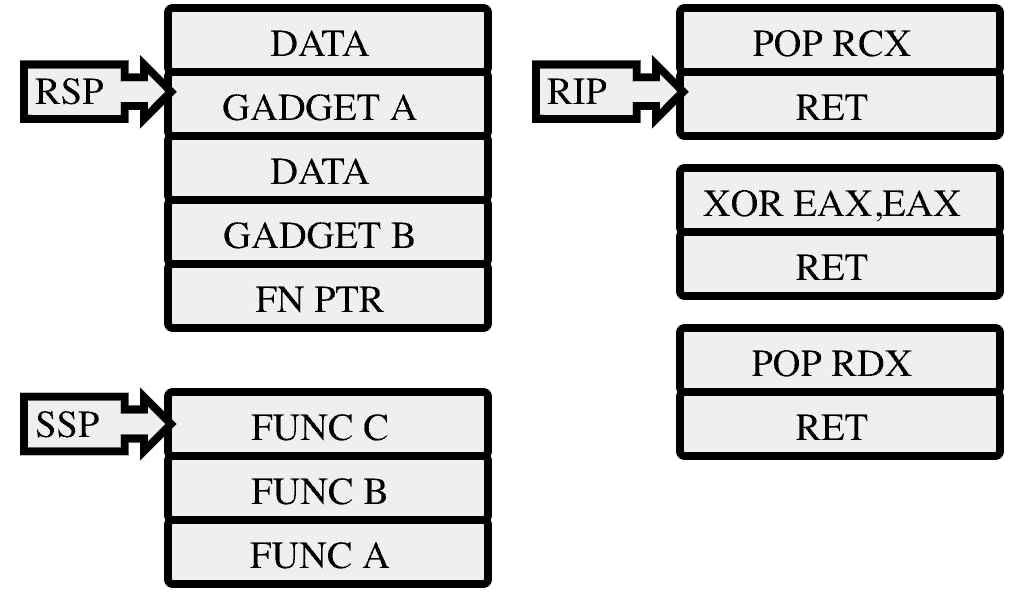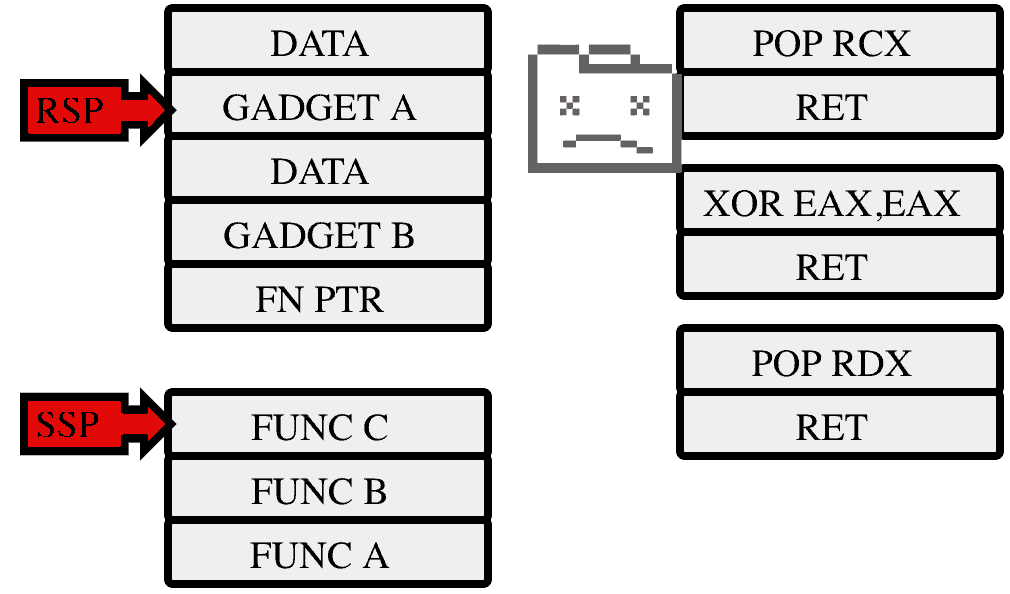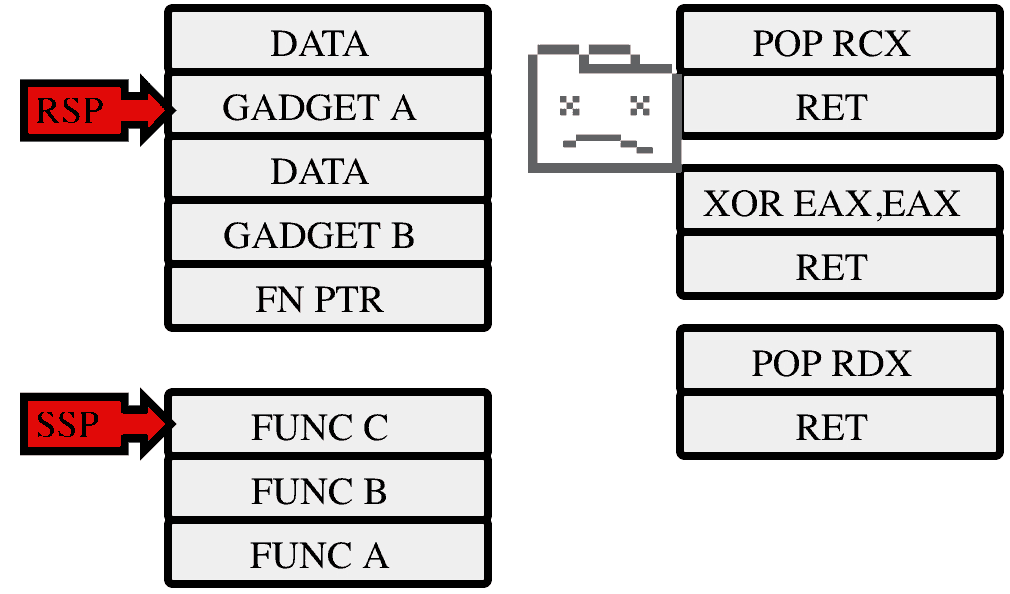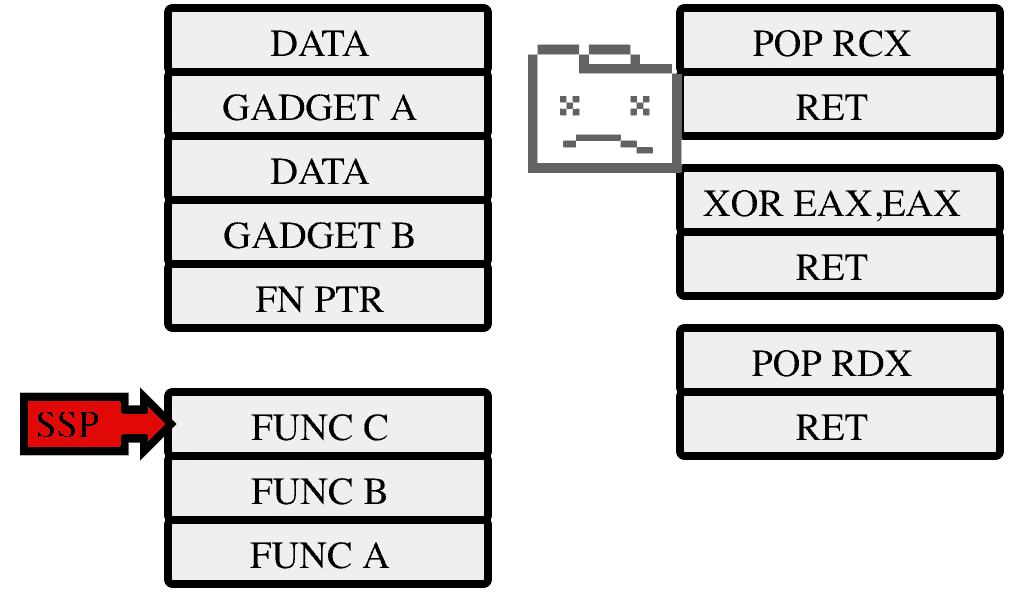
In our example above, the attacker will be able to make their initial jump into a ROP gadget, but on trying to return to their next gadget they will be stopped.
Some software may be incompatible with this mechanism, especially some older security software that injects into a process and hooks operating system functions by overwriting the prelude with `rax = &hook; push rax; ret`.
Limitations
Chrome does not yet support every direction of control flow enforcement. Stack protection enforces the reverse-edge of the call graph but does not constrain the forward-edge. It will still be possible to make indirect jumps around existing code as stack protection is only validated when a return instruction is encountered, and call targets are not validated. On Windows a technology called Control Flow Guard (CFG) can be used to verify the target of an indirect function call before it is attempted. This prevents calling into the middle of a function, significantly reducing the scope of useful instructions for attackers to use. Another approach is provided by Intel’s CET which includes an ENDBRANCH instruction to prevent jumps into arbitrary code locations. Memory tagging tools such as MTE can be used to make it more difficult to modify pointers to valid code sequences (and makes UAFs more difficult in general). We are working to introduce CFG to Chrome for Windows, and will add other techniques over time.
By itself, stack protection can be bypassed in some contexts. For instance, stack protection does not prevent an attacker tricking a program into calling an existing function by entirely replacing an object containing a function pointer. This approach does not involve ROP as the function call happens instead of the expected call, and returns to the address it was originally called from, so must be allowed. However, the called function must be useful to an attacker, and most functions will not be. An example of an attack using this method is to craft a call to add the `--no-sandbox` argument to Chrome’s command line. This results in future renderers being launched without normal protections. Over time we will identify and remove such useful tools.
In the renderer, for performance reasons, our javascript and wasm engines may use memory that is both writable and executable at the same time. This allows an attacker to modify code that v8 is already going to execute, saving them the trouble of constructing a ROP chain. This explains why it was not our first priority to make v8 CET compatible, and why stack-protection is not yet enabled in the renderer.
Finally, stack protection doesn’t stop the bugs in the first place. Everything we have discussed above is a mitigation that makes it more difficult to execute arbitrary code. If a programming error allows arbitrary writes then it is very unlikely that we can prevent this being used to run arbitrary code. Attackers will adapt and find new ways to turn memory safety errors into code execution.
Debugging Tips
You can see if Hardware-enforced Stack Protection is enabled for a process using the Windows Task Manager. Open task manager, open the Details Tab, Right Click on a heading, Select Columns & Check the Hardware-enforced Stack Protection box. The process display will then indicate if a process is opted-in to this mitigation. ‘Compatible Modules Only’ indicates that any dll marked as /cetcompat at build time will raise an exception if a return address is invalid.
You can see which Chrome processes are opted-out of CET by consulting the Mitigations field of chrome://sandbox and clicking ‘+’. All processes are included unless the mitigation CET_USER_SHADOW_STACKS_ALWAYS_OFF is present in the expanded details view.
If you are developing software, or debugging a problem in Chrome the shadow stack can be helpful as it includes only return addresses, and these cannot be corrupted by rogue writes elsewhere in the process. To see these registers use the `r` command in windbg with the mask option:
0:159> rM 8002
rax=00000000c000060a rbx=000000fa5bbfeff0 rcx=0000000000000030
rdx=0000000000000000 rsi=00007ffba4118924 rdi=000000fa5bbff1a0
rip=00007ffc1847b4a1 rsp=000000fa5bbfc0a0 rbp=000000fa5bbfc0a0
r8=000000fa5bbfc098 r9=0000000000000000 r10=0000000000000000
r11=0000000000000246 r12=000000fa5bbfe230 r13=000002c3450b5830
r14=000002c3450b7850 r15=000000fa5bbfc260
iopl=0 nv up ei pl zr na po nc
ssp=000000fa5c3fef10 cetumsr=0000000000000001
`ssp` points to the shadow stack region, `cetumsr` indicates if cet is enabled for the process.
You can then see the call stack within the shadow region using `dps @ssp`. Values are not overwritten so you can also see where you came from by looking a bit deeper: `dps @ssp-20`.
If a process is not compatible with Hardware-enforced Stack Protection, the system event log (Application Log) will include brief error reports (Id:1001). You can filter those related to cetcompat using the following powershell snippet:-
Get-WinEvent -MaxEvents 128 -FilterHashtable @{ LogName='Application'; Id='1001' } `
| Where-Object {$_.Message -match 'chrome.exe'} `
| Select-Object -First 8 `
| fl
These will include the following parameters:-
P1: application.exe
P2: application version
P3: application build ts
P4: faulting module .dll
P5: faulting module version
P6: faulting module build ts
P7: faulting offset in P4 from base_address
P8: exception code (c0000409)
P9: subcode (00...000030)
If Chrome is misbehaving and you think it might be because of cetcompat, it is possible to disable it using Image File Execution Options - we do not recommend this except for a limited period of testing. If you find you have to do this, please raise an issue on https://crbug.com so that we can investigate the failure.
Further Reading
Summary
/cetcompat is enabled for most processes for Chrome M90 on Windows. Enabling Hardware-enforced Stack Protection will layer with existing and future measures to make exploitation more difficult and so more expensive for an attacker, ultimately protecting the people who use Chrome every day.


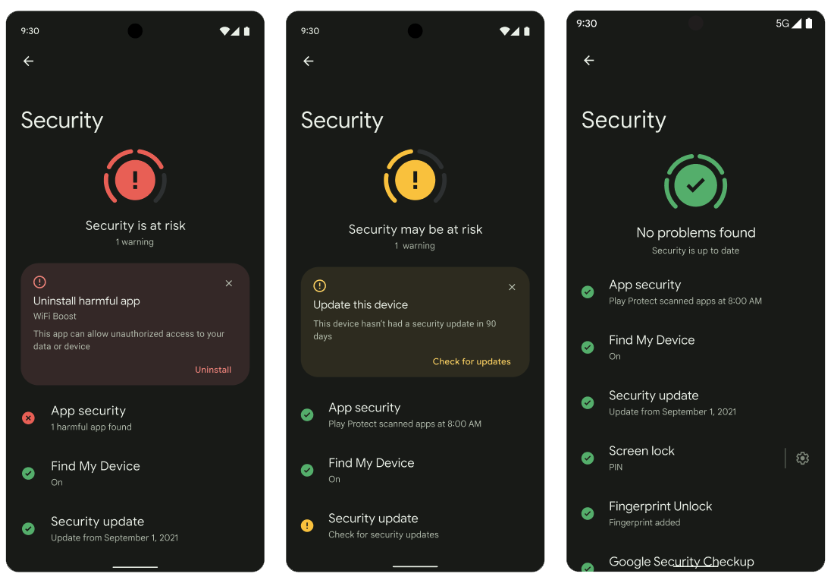





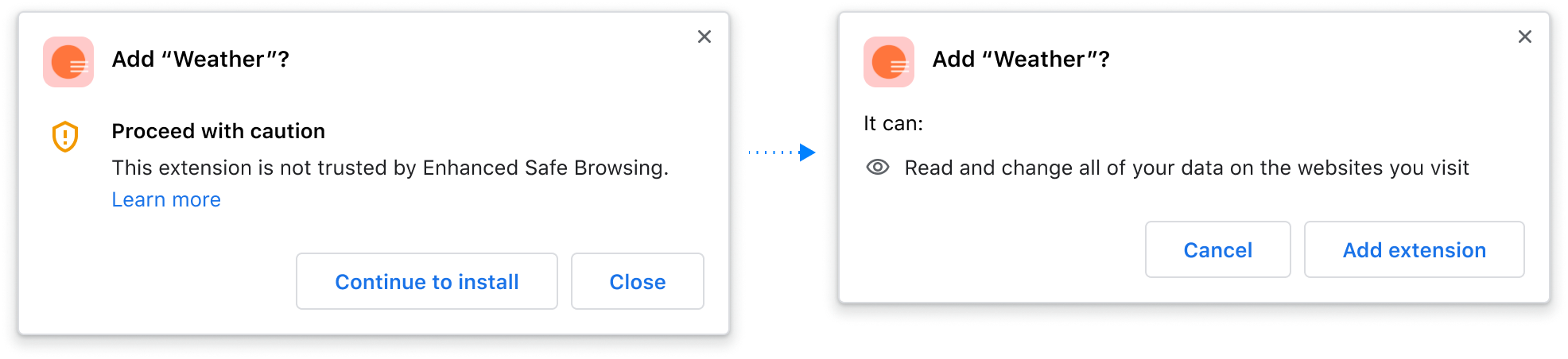
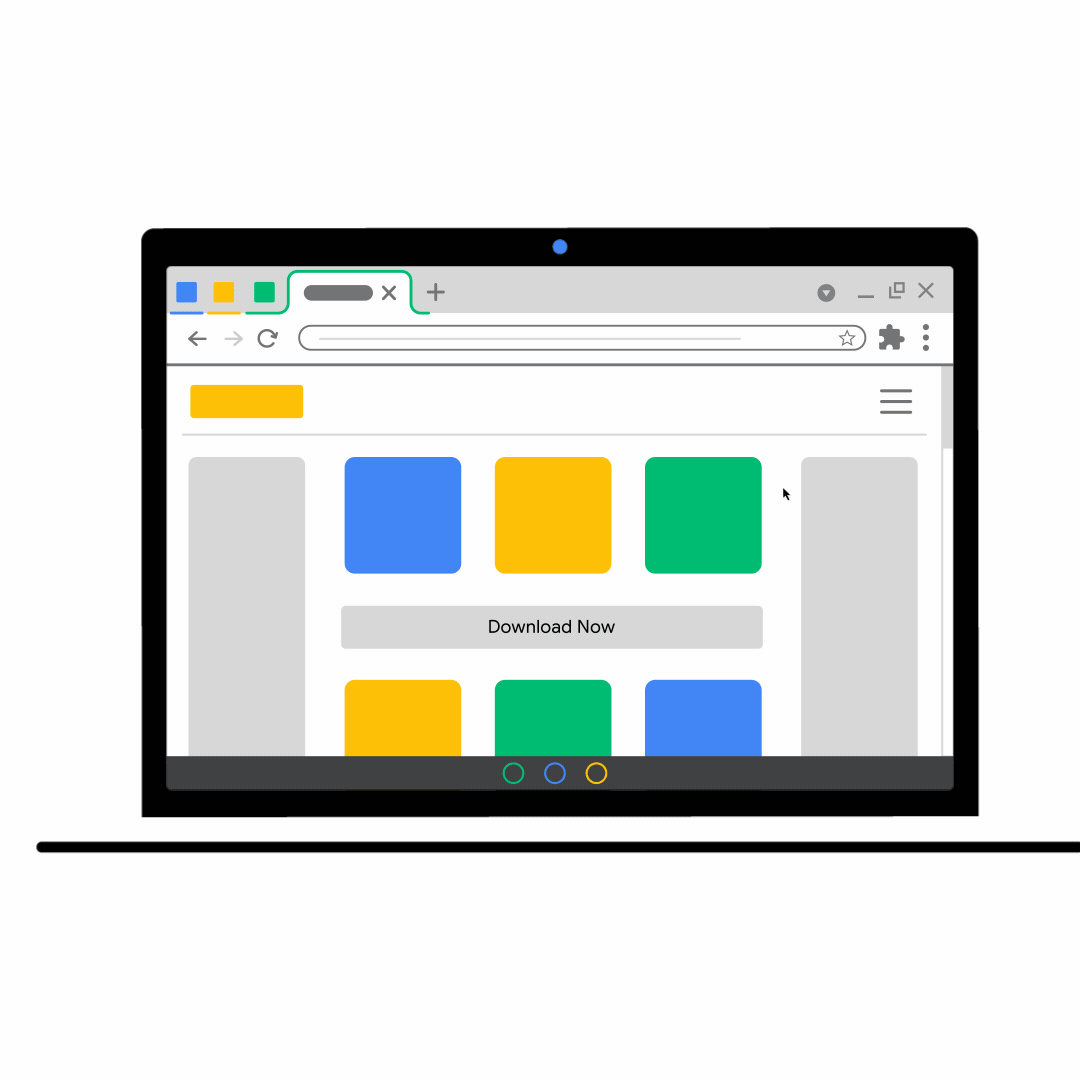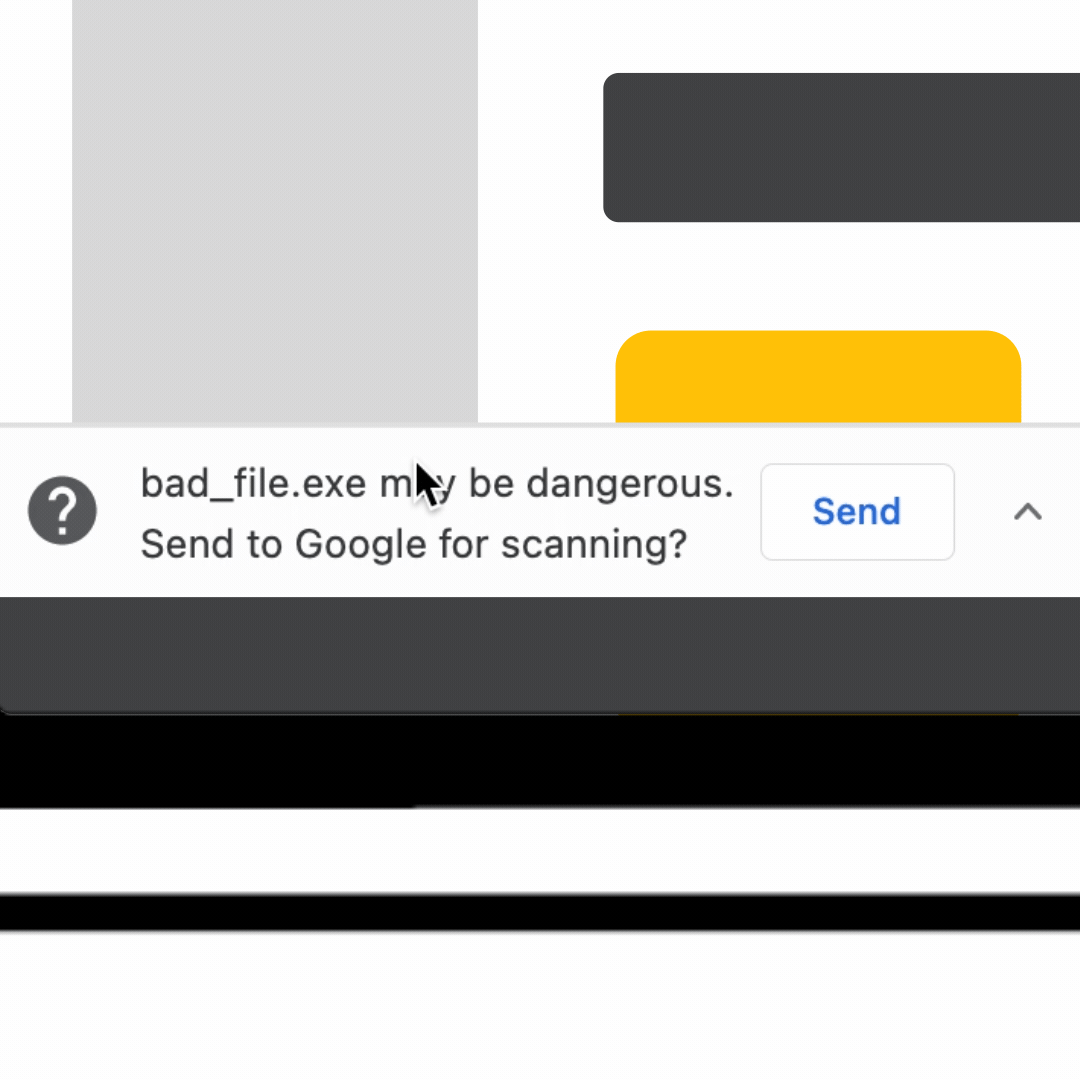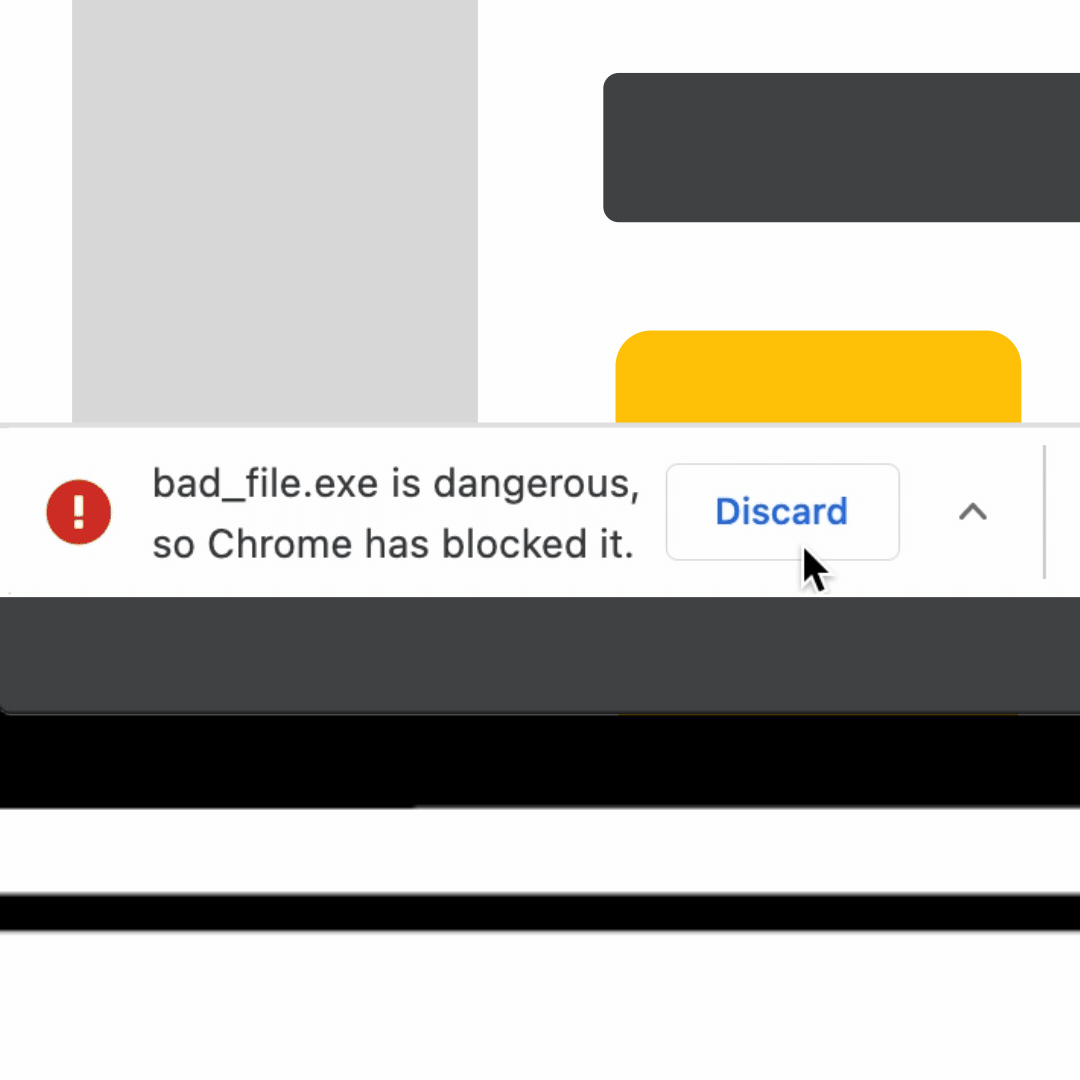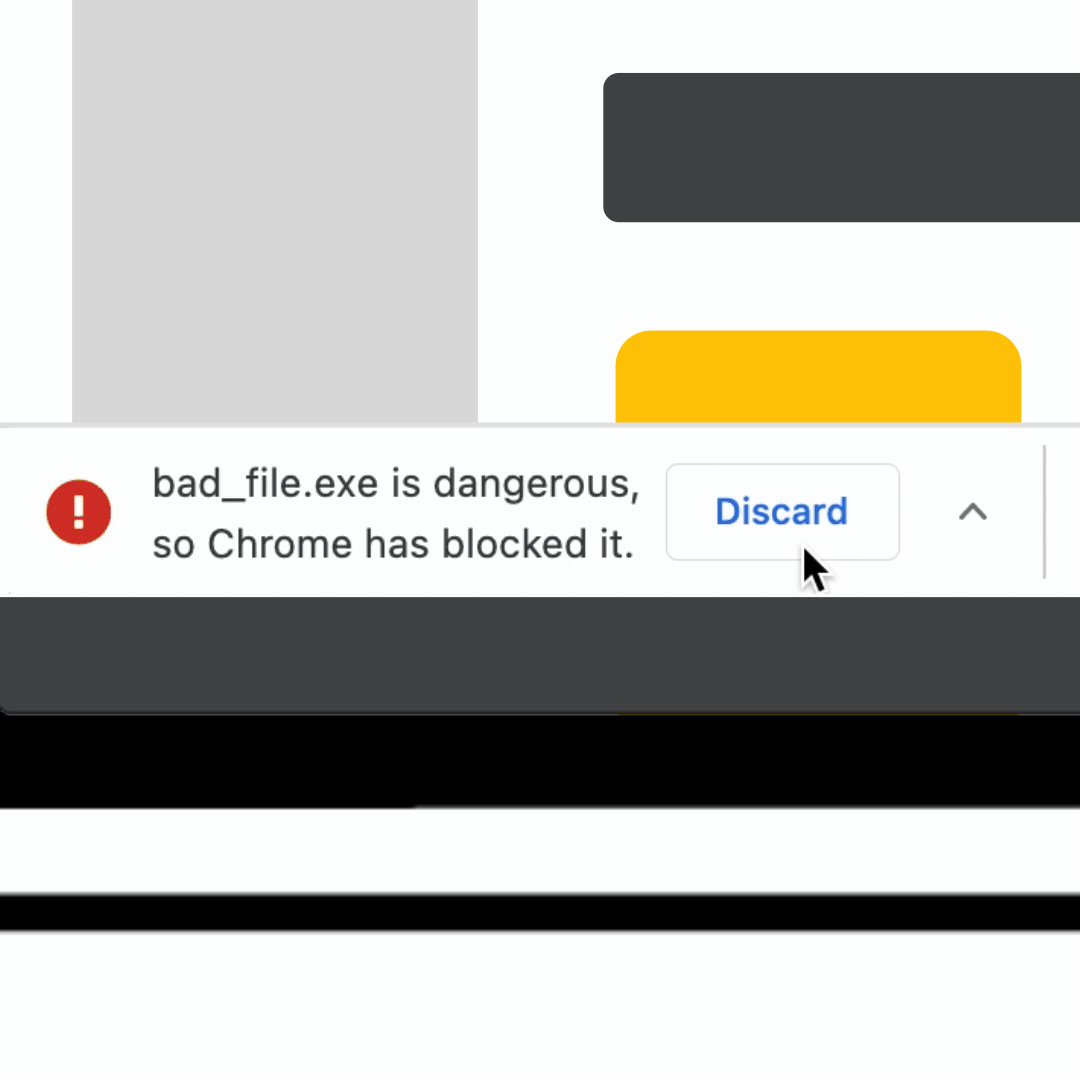 When you download a file, Chrome performs a first level check with Google Safe Browsing using metadata about the downloaded file, such as the digest of the contents and the source of the file, to determine whether it’s potentially suspicious. For any downloads that Safe Browsing deems risky, but not clearly unsafe, Enhanced Safe Browsing users will be presented with a warning and the ability to send the file to be scanned for a more in depth analysis (pictured above).
When you download a file, Chrome performs a first level check with Google Safe Browsing using metadata about the downloaded file, such as the digest of the contents and the source of the file, to determine whether it’s potentially suspicious. For any downloads that Safe Browsing deems risky, but not clearly unsafe, Enhanced Safe Browsing users will be presented with a warning and the ability to send the file to be scanned for a more in depth analysis (pictured above).



