Posted by Yoshi Yamaguchi, Santiago Díaz, Maud Nalpas, Eiji Kitamura, DevRel team
The Reporting API is an emerging web standard that provides a generic reporting mechanism for issues occurring on the browsers visiting your production website. The reports you receive detail issues such as security violations or soon-to-be-deprecated APIs, from users’ browsers from all over the world.
Collecting reports is often as simple as specifying an endpoint URL in the HTTP header; the browser will automatically start forwarding reports covering the issues you are interested in to those endpoints. However, processing and analyzing these reports is not that simple. For example, you may receive a massive number of reports on your endpoint, and it is possible that not all of them will be helpful in identifying the underlying problem. In such circumstances, distilling and fixing issues can be quite a challenge.
In this blog post, we'll share how the Google security team uses the Reporting API to detect potential issues and identify the actual problems causing them. We'll also introduce an open source solution, so you can easily replicate Google's approach to processing reports and acting on them.
How does the Reporting API work?
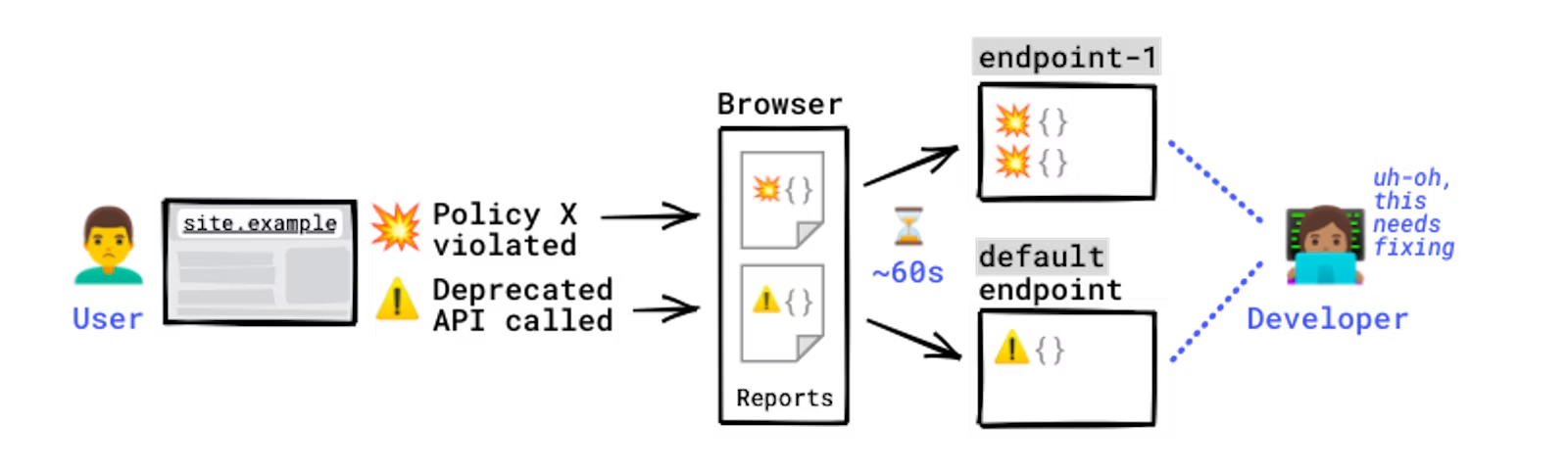
Some errors only occur in production, on users’ browsers to which you have no access. You won't see these errors locally or during development because there could be unexpected conditions real users, real networks, and real devices are in. With the Reporting API, you directly leverage the browser to monitor these errors: the browser catches these errors for you, generates an error report, and sends this report to an endpoint you've specified.
How reports are generated and sent.
Errors you can monitor with the Reporting API include:
For a full list of error types you can monitor, see use cases and report types.
The Reporting API is activated and configured using HTTP response headers: you need to declare the endpoint(s) you want the browser to send reports to, and which error types you want to monitor. The browser then sends reports to your endpoint in POST requests whose payload is a list of reports.
Example setup:
# Example setup to receive CSP violations reports, Document-Policy violations reports, and Deprecation reports
Reporting-Endpoints: main-endpoint="https://reports.example/main", default="https://reports.example/default"
# CSP violations and Document-Policy violations will be sent to `main-endpoint`
Content-Security-Policy: script-src 'self'; object-src 'none'; report-to main-endpoint;
Document-Policy: document-write=?0; report-to=main-endpoint;
# Deprecation reports are generated automatically and don't need an explicit endpoint; they're always sent to the `default` endpoint
Note: Some policies support "report-only" mode. This means the policy sends a report, but doesn't actually enforce the restriction. This can help you gauge if the policy is working effectively.
Chrome users whose browsers generate reports can see them in DevTools in the Application panel:
Example of viewing reports in the Application panel of DevTools.
You can generate various violations and see how they are received on a server in the reporting endpoint demo:
Example violation reports
The Reporting API is supported by Chrome, and partially by Safari as of March 2024. For details, see the browser support table.
Google's approach
Google benefits from being able to uplift security at scale. Web platform mitigations like Content Security Policy, Trusted Types, Fetch Metadata, and the Cross-Origin Opener Policy help us engineer away entire classes of vulnerabilities across hundreds of Google products and thousands of individual services, as described in this blogpost.
One of the engineering challenges of deploying security policies at scale is identifying code locations that are incompatible with new restrictions and that would break if those restrictions were enforced. There is a common 4-step process to solve this problem:
- Roll out policies in report-only mode (CSP report-only mode example). This instructs browsers to execute client-side code as usual, but gather information on any events where the policy would be violated if it were enforced. This information is packaged in violation reports that are sent to a reporting endpoint.
- The violation reports must be triaged to link them to locations in code that are incompatible with the policy. For example, some code bases may be incompatible with security policies because they use a dangerous API or use patterns that mix user data and code.
- The identified code locations are refactored to make them compatible, for example by using safe versions of dangerous APIs or changing the way user input is mixed with code. These refactorings uplift the security posture of the code base by helping reduce the usage of dangerous coding patterns.
- When all code locations have been identified and refactored, the policy can be removed from report-only mode and fully enforced. Note that in a typical roll out, we iterate steps 1 through 3 to ensure that we have triaged all violation reports.
With the Reporting API, we have the ability to run this cycle using a unified reporting endpoint and a single schema for several security features. This allows us to gather reports for a variety of features across different browsers, code paths, and types of users in a centralized way.
Note: A violation report is generated when an entity is attempting an action that one of your policies forbids. For example, you've set CSP on one of your pages, but the page is trying to load a script that's not allowed by your CSP. Most reports generated via the Reporting API are violation reports, but not all — other types include deprecation reports and crash reports. For details, see Use cases and report types.
Unfortunately, it is common for noise to creep into streams of violation reports, which can make finding incompatible code locations difficult. For example, many browser extensions, malware, antivirus software, and devtools users inject third-party code into the DOM or use forbidden APIs. If the injected code is incompatible with the policy, this can lead to violation reports that cannot be linked to our code base and are therefore not actionable. This makes triaging reports difficult and makes it hard to be confident that all code locations have been addressed before enforcing new policies.
Over the years, Google has developed a number of techniques to collect, digest, and summarize violation reports into root causes. Here is a summary of the most useful techniques we believe developers can use to filter out noise in reported violations:
Focus on root causes
It is often the case that a piece of code that is incompatible with the policy executes several times throughout the lifetime of a browser tab. Each time this happens, a new violation report is created and queued to be sent to the reporting endpoint. This can quickly lead to a large volume of individual reports, many of which contain redundant information. Because of this, grouping violation reports into clusters enables developers to abstract away individual violations and think in terms of root causes. Root causes are simpler to understand and can speed up the process of identifying useful refactorings.
Let's take a look at an example to understand how violations may be grouped. For instance, a report-only CSP that forbids the use of inline JavaScript event handlers is deployed. Violation reports are created on every instance of those handlers and have the following fields set:
- The
blockedURL field is set to inline, which describes the type of violation.
- The
scriptSample field is set to the first few bytes of the contents of the event handler in the field.
- The
documentURL field is set to the URL of the current browser tab.
Most of the time, these three fields uniquely identify the inline handlers in a given URL, even if the values of other fields differ. This is common when there are tokens, timestamps, or other random values across page loads. Depending on your application or framework, the values of these fields can differ in subtle ways, so being able to do fuzzy matches on reporting values can go a long way in grouping violations into actionable clusters. In some cases, we can group violations whose URL fields have known prefixes, for example all violations with URLs that start with chrome-extension, moz-extension, or safari-extension can be grouped together to set root causes in browser extensions aside from those in our codebase with a high degree of confidence.
Developing your own grouping strategies helps you stay focused on root causes and can significantly reduce the number of violation reports you need to triage. In general, it should always be possible to select fields that uniquely identify interesting types of violations and use those fields to prioritize the most important root causes.
Leverage ambient information
Another way of distinguishing non-actionable from actionable violation reports is ambient information. This is data that is contained in requests to our reporting endpoint, but that is not included in the violation reports themselves. Ambient information can hint at sources of noise in a client's set up that can help with triage:
- User Agent or User Agent client hints: User agents are a great tell-tale sign of non-actionable violations. For example, crawlers, bots, and some mobile applications use custom user agents whose behavior differs from well-supported browser engines and that can trigger unique violations. In other cases, some violations may only trigger in a specific browser or be caused by changes in nightly builds or newer versions of browsers. Without user agent information, these violations would be significantly more difficult to investigate.
- Trusted users: Browsers will attach any available cookies to requests made to a reporting endpoint by the Reporting API, if the endpoint is same-site with the document where the violation occurs. Capturing cookies is useful for identifying the type of user that caused a violation. Often, the most actionable violations come from trusted users that are not likely to have invasive extensions or malware, like company employees or website administrators. If you are not able to capture authentication information through your reporting endpoint, consider rolling out report-only policies to trusted users first. Doing so allows you to build a baseline of actionable violations before rolling out your policies to the general public.
- Number of unique users: As a general principle, users of typical features or code paths should generate roughly the same violations. This allows us to flag violations seen by a small number of users as potentially suspicious, since they suggest that a user's particular setup might be at fault, rather than our application code. One way of 'counting users' is to keep note of the number of unique IP addresses that reported a violation. Approximate counting algorithms are simple to use and can help gather this information without tracking specific IP addresses. For example, the HyperLogLog algorithm requires just a few bytes to approximate the number of unique elements in a set with a high degree of confidence.
Map violations to source code (advanced)
Some types of violations have a source_file field or equivalent. This field represents the JavaScript file that triggered the violation and is usually accompanied by a line and column number. These three bits of data are a high-quality signal that can point directly to lines of code that need to be refactored.
Nevertheless, it is often the case that source files fetched by browsers are compiled or minimized and don't map directly to your code base. In this case, we recommend you use JavaScript source maps to map line and column numbers between deployed and authored files. This allows you to translate directly from violation reports to lines of source code, yielding highly actionable report groups and root causes.
Establish your own solution
The Reporting API sends browser-side events, such as security violations, deprecated API calls, and browser interventions, to the specified endpoint on a per-event basis. However, as explained in the previous section, to distill the real issues out of those reports, you need a data processing system on your end.
Fortunately, there are plenty of options in the industry to set up the required architecture, including open source products. The fundamental pieces of the required system are the following:
- API endpoint: A web server that accepts HTTP requests and handles reports in a JSON format
- Storage: A storage server that stores received reports and reports processed by the pipeline
- Data pipeline: A pipeline that filters out noise and extracts and aggregates required metadata into constellations
- Data visualizer: A tool that provides insights on the processed reports
Solutions for each of the components listed above are made available by public cloud platforms, SaaS services, and as open source software. See the Alternative solutions section for details, and the following section outlining a sample application.
Sample application: Reporting API Processor
To help you understand how to receive reports from browsers and how to handle these received reports, we created a small sample application that demonstrates the following processes that are required for distilling web application security issues from reports sent by browsers:
- Report ingestion to the storage
- Noise reduction and data aggregation
- Processed report data visualization
Although this sample is relying on Google Cloud, you can replace each of the components with your preferred technologies. An overview of the sample application is illustrated in the following diagram:
Components described as green boxes are components that you need to implement by yourself. Forwarder is a simple web server that receives reports in the JSON format and converts them to the schema for Bigtable. Beam-collector is a simple Apache Beam pipeline that filters noisy reports, aggregates relevant reports into the shape of constellations, and saves them as CSV files. These two components are the key parts to make better use of reports from the Reporting API.
Try it yourself
Because this is a runnable sample application, you are able to deploy all components to a Google Cloud project and see how it works by yourself. The detailed prerequisites and the instructions to set up the sample system are documented in the README.md file.
Alternative solutions
Aside from the open source solution we shared, there are a number of tools available to assist in your usage of the Reporting API. Some of them include:
- Report-collecting services like report-uri and uriports.
- Application error monitoring platforms like Sentry, Datadog, etc.
Besides pricing, consider the following points when selecting alternatives:
- Are you comfortable sharing any of your application's URLs with a third-party report collector? Even if the browser strips sensitive information from these URLs, sensitive information may get leaked this way. If this sounds too risky for your application, operate your own reporting endpoint.
- Does this collector support all report types you need? For example, not all reporting endpoint solutions support COOP/COEP violation reports.
Summary
In this article, we explained how web developers can collect client-side issues by using the Reporting API, and the challenges of distilling the real problems out of the collected reports. We also introduced how Google solves those challenges by filtering and processing reports, and shared an open source project that you can use to replicate a similar solution. We hope this information will motivate more developers to take advantage of the Reporting API and, in consequence, make their website more secure and sustainable.
Learning resources





.png)




 We opened the Google Visitor Experience in Mountain View that offers new spaces for the community and visitors, including a Google Store.
We opened the Google Visitor Experience in Mountain View that offers new spaces for the community and visitors, including a Google Store.
 The Google Visitor Experience in Mountain View is opening this fall to neighbors, visitors and Googlers.
The Google Visitor Experience in Mountain View is opening this fall to neighbors, visitors and Googlers.