By Jennifer Lin, Director of Product Management, GCP Security and Privacy
They say security is a process, not a destination, and that certainly rang true as we prepared for today’s CEO Security Forum in New York, where we’re making more than 20 security announcements across the Google Cloud portfolio.
When it comes to
Google Cloud Platform (GCP), our goal is to continuously improve on the strong foundation that we’ve built over the years, and help you build out a secure, scalable environment. Here’s an overview of our GCP-related news. Stay tuned over the coming days for deeper dives into some of these new products.
1. Keep sensitive data private with VPC Service Controls Alpha
If your organization is looking to take advantage of the fully managed GCP technologies for big data analytics, data processing and storage, but has hesitated to put sensitive data in the cloud outside your secured network, our new
VPC Service Controls provide an additional layer of protection to help keep your data private.
Currently in alpha, VPC Service Controls create a security perimeter around data stored in API-based GCP services such as Google Cloud Storage, BigQuery and Bigtable. This helps mitigate data exfiltration risks stemming from stolen identities, IAM policy misconfigurations, malicious insiders and compromised virtual machines.
With this managed service, enterprises can configure private communication between cloud resources and hybrid VPC networks using Cloud VPN or Cloud Dedicated Interconnect. By expanding perimeter security from on-premise networks to data stored in GCP services, enterprises can feel confident about storing their data in the cloud and accessing it from an on-prem environment or cloud-based VMs.
VPC Service Controls also take security a step further with context-aware access control for your cloud resources using the Access Context Manager feature. Enterprises can create granular access control policies in Access Context Manager based on attributes like user location and IP address. These policies help ensure the appropriate security controls are in place when granting access to cloud resources from the internet.
Google Cloud is the first cloud provider to offer virtual security perimeters for API-based services with simplicity, speed and flexibility that far exceed what most organizations can achieve in a physical, on-premises environment.
Get started by
signing up for the upcoming VPC Service Controls beta.
2. Get insight into data and application risk with Cloud Security Command Center Alpha
As organizations entrust more applications to the cloud, it can be tough to understand the extent of your cloud assets and the risks against them. The new
Cloud Security Command Center (Cloud SCC), currently in alpha, lets you view and monitor an inventory of your cloud assets, scan storage systems for sensitive data, detect common web vulnerabilities and review access rights to your critical resources—all from a single, centralized dashboard.
Cloud SCC provides deep views into the security status and health of GCP services such as App Engine, Compute Engine, Cloud Storage, and Cloud Datastore. It integrates with the DLP API to help identify sensitive information, and with Google Cloud Security Scanner to uncover vulnerabilities such as cross-site-scripting (XSS) and Flash injection. Use it to manage access control policies, receive alerts about unexpected changes through an integration with Forseti, the open-source GCP security toolkit, and detect threats and suspicious activity with Google anomaly detection as well as security partners such as Cloudflare, CrowdStrike, Dome9, Palo Alto Networks, Qualys and RedLock.
Get started by
signing up for the Cloud SCC alpha program.
3. Expand Your visibility with Access Transparency
Trust is paramount when choosing a cloud provider. We want to be as open and transparent as possible, allowing customers to see what happens to their data. Now, with Access Transparency, we’ll provide you with an audit log of authorized administrative accesses by Google Support and Engineering, as well as justifications for those accesses, for many GCP services, and we’ll be adding more throughout the year. With Access Transparency, we can continue to maintain high performance and reliability for your environment while remaining accountable to the trust you place in our service.
Access Transparency logs are generated in near-real time, and appear in your Stackdriver Logging console in the same way that your Cloud Audit Logs do, with the same protections you would expect from audit-grade logs. You can export Access Transparency logs into BigQuery or Cloud Storage for storage and archiving, or via PubSub into your existing audit pipeline or SIEM tooling for further investigation and review.
The combination of Google Cloud Audit Logs and Access Transparency logs gives you a more comprehensive view into administrative activity in your GCP environment.
To learn more about Access Transparency, visit the
product page, where you can find out more and sign up for the beta program.
4. Avoid Denial of Service with Cloud Armor
If you run internet-facing services or apps, you have a tough job: quickly and responsively serving traffic to your end users, while simultaneously protecting against malicious attacks trying to take your services down. Here at Google, we’re no stranger to this phenomenon, and so today, we’re announcing Cloud Armor, a Distributed Denial of Service (DDoS) and application defense service that’s based on the same technologies and global infrastructure that we use to protect services like Search, Gmail and YouTube.
Global HTTP(S) Load Balancing provides
built-in defense against Infrastructure DDoS attacks. No additional configuration, other than to configure load balancing, is required to activate this DDoS defense. Cloud Armor works with Cloud HTTP(S) Load Balancing, provides IPv4 and IPv6 whitelisting/blacklisting, defends against application-aware attacks such as cross-site scripting (XSS) and SQL injection (SQLi), and delivers geography-based access control.
A sophisticated rules language and global enforcement engine underpin Cloud Armor, enabling you to create custom defenses, with any combination of Layer 3 to Layer 7 parameters, against multivector attacks (combination of two or more attack types). Cloud Armor gives you visibility into your blocked and allowed traffic by sending information to Stackdriver Logging about each incoming request and the action taken on that request by the Cloud Armor rule.
Learn more by visiting the
Cloud Armor product page.
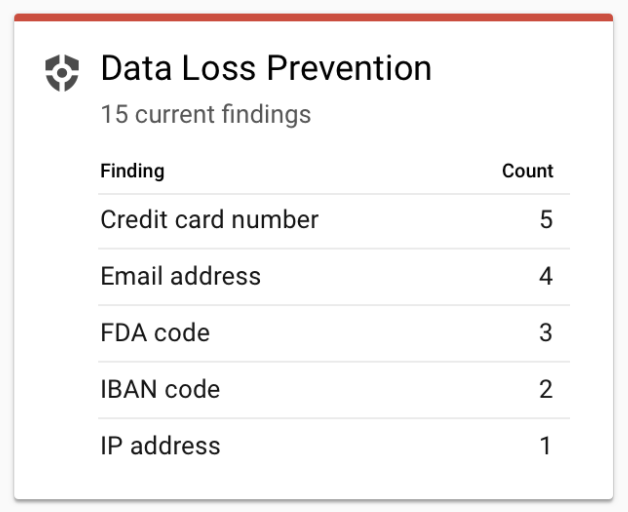
5. Discover, classify and redact sensitive data with the DLP API
Sensitive information is a fact of life. The question is—how do you identify it and help ensure it’s protected? Enter the Cloud Data Loss Prevention (DLP) API, a managed service that lets you discover, classify and redact sensitive information stored in your organization’s digital assets.
First announced last year, the DLP API is now generally available. And because the DLP API is, well, an API, you can use it on virtually any data source or business application, whether it’s on GCP services like Cloud Storage or BigQuery, a third-party cloud, or in your on-premises data center. Furthermore, you can use the DLP API to detect (and, just as importantly, redact) sensitive information in real-time, as well as in batch-mode against static datasets.
Our goal is to make the DLP API an extensible part of your security arsenal. Since it was first announced, we’ve added several new detectors, including one to identify service account credentials, as well as the ability to build your own detectors based on custom dictionaries, patterns and context rules.
Learn more by visiting the
DLP API product page.
6. Provide simple, secure access for any user to cloud applications from any device with Cloud Identity
Last summer we
announced Cloud Identity, a built-in service that allows organizations to easily manage users and groups who need access to GCP resources. Our new, standalone Cloud Identity product is a full Identity as a Service (IDaaS) solution that adds premium features such as enterprise security, application management and device management to provide enterprises with simple, secure access for any user to cloud applications from any device.
Cloud Identity enables and accelerates the use of cloud-centric applications and services, while offering capabilities to meet customer organizations where they are with their on-premise IAM systems and apps.
Learn more by visiting the
Cloud Identity product page.
7. Extending the benefits of GCP security to U.S. federal, state and local government customers through FedRamp authorization
While Google Cloud goes to great lengths to document the security capabilities of our infrastructure and platforms, third-party validation always helps. We’re pleased to announce that GCP, and Google’s underlying common infrastructure, have received the FedRAMP Rev. 4 Provisional Authorization to Operate (P-ATO) at the Moderate Impact level from the FedRAMP Joint Authorization Board (JAB). GCP’s certification encompasses data centers in many countries, so customers can take advantage of this certification from multiple Google Cloud regions.
Agencies and federal contractors can request access to our FedRAMP package by submitting a
FedRAMP Package Access Request Form.
8. Take advantage of new security partnerships
In addition to today’s security announcements, we’ve also been working with several security
companies to offer additional solutions that complement GCP’s capabilities. You can read about these partnerships in more detail in our
partnerships blog post.
Today we’re announcing new GCP partner solutions, including:
- Dome9 has developed a compliance test suite for the Payment Card Industry Data Security Standard (PCI DSS) in the Dome9 Compliance Engine.
- Rackspace Managed Security provides businesses with fully managed security on top of GCP.
- RedLock’s Cloud 360 Platform is a cloud threat defense security and compliance solution that provides additional visibility and control for Google Cloud environments.
As always, we’re thrilled to be able to share with you the fruits of our experience running and protecting some of the world’s most popular web applications. And we’re honored that you’ve chosen to make GCP your home in the cloud. For more on today’s security announcements read our posts on the
Google Cloud blog, the
G Suite blog and the
Connected Workspaces blog.