 Posted by
Posted by 
Thousands of developers across the globe are harnessing the power of the Gemini 1.5 Pro and Gemini 1.5 Flash models to infuse advanced generative AI features into their applications. Android developers are no exception, and with the upcoming launch of the stable version of VertexAI in Firebase in a few weeks (available in Beta since Google I/O), it's the perfect time to explore how your app can benefit from it. We just published a codelab to help you get started.
Let's deep dive into some advanced capabilities of the Gemini API that go beyond simple text prompting and discover the exciting use cases they can unlock in your Android app.
Shaping AI behavior with system instructions
System instructions serve as a "preamble" that you incorporate before the user prompt. This enables shaping the model's behavior to align with your specific requirements and scenarios. You set the instructions when you initialize the model, and then those instructions persist through all interactions with the model, across multiple user and model turns.
For example, you can use system instructions to:
- Define a persona or role for a chatbot (e.g, “explain like I am 5”)
- Specify the response to the output format (e.g., Markdown, YAML, etc.)
- Set the output style and tone (e.g, verbosity, formality, etc…)
- Define the goals or rules for the task (e.g, “return a code snippet without further explanation”)
- Provide additional context for the prompt (e.g., a knowledge cutoff date)
To use system instructions in your Android app, pass it as parameter when you initialize the model:
val generativeModel = Firebase.vertexAI.generativeModel( modelName = "gemini-1.5-flash", ... systemInstruction = content { text("You are a knowledgeable tutor. Answer the questions using the socratic tutoring method.") } )
You can learn more about system instruction in the Vertex AI in Firebase documentation.
You can also easily test your prompt with different system instructions in Vertex AI Studio, Google Cloud console tool for rapidly prototyping and testing prompts with Gemini models.
When you are ready to go to production it is recommended to target a specific version of the model (e.g. gemini-1.5-flash-002). But as new model versions are released and previous ones are deprecated, it is advised to use Firebase Remote Config to be able to update the version of the Gemini model without releasing a new version of your app.
Beyond chatbots: leveraging generative AI for advanced use cases
While chatbots are a popular application of generative AI, the capabilities of the Gemini API go beyond conversational interfaces and you can integrate multimodal GenAI-enabled features into various aspects of your Android app.
Many tasks that previously required human intervention (such as analyzing text, image or video content, synthesizing data into a human readable format, engaging in a creative process to generate new content, etc… ) can be potentially automated using GenAI.
Gemini JSON support
Android apps don’t interface well with natural language outputs. Conversely, JSON is ubiquitous in Android development, and provides a more structured way for Android apps to consume input. However, ensuring proper key/value formatting when working with generative models can be challenging.
With the general availability of Vertex AI in Firebase, implemented solutions to streamline JSON generation with proper key/value formatting:
Response MIME type identifier
If you have tried generating JSON with a generative AI model, it's likely you have found yourself with unwanted extra text that makes the JSON parsing more challenging.
e.g:
Sure, here is your JSON: ``` { "someKey”: “someValue", ... } ```
When using Gemini 1.5 Pro or Gemini 1.5 Flash, in the generation configuration, you can explicitly specify the model’s response mime/type as application/json and instruct the model to generate well-structured JSON output.
val generativeModel = Firebase.vertexAI.generativeModel( modelName = "gemini-1.5-flash", … generationConfig = generationConfig { responseMimeType = "application/json" } )
Review the API reference for more details.
Soon, the Android SDK for Vertex AI in Firebase will enable you to define the JSON schema expected in the response.
Multimodal capabilities
Both Gemini 1.5 Flash and Gemini 1.5 Pro are multimodal models. It means that they can process input from multiple formats, including text, images, audio, video. In addition, they both have long context windows, capable of handling up to 1 million tokens for Gemini 1.5 Flash and 2 million tokens for Gemini 1.5 Pro.
These features open doors to innovative functionalities that were previously inaccessible such as automatically generate descriptive captions for images, identify topics in a conversation and generate chapters from an audio file or describe the scenes and actions in a video file.
You can pass an image to the model as shown in this example:
val contentResolver = applicationContext.contentResolver contentResolver.openInputStream(imageUri).use { stream -> stream?.let { val bitmap = BitmapFactory.decodeStream(stream) // Provide a prompt that includes the image specified above and text val prompt = content { image(bitmap) text("How many people are on this picture?") } } val response = generativeModel.generateContent(prompt) }
You can also pass a video to the model:
val contentResolver = applicationContext.contentResolver contentResolver.openInputStream(videoUri).use { stream -> stream?.let { val bytes = stream.readBytes() // Provide a prompt that includes the video specified above and text val prompt = content { blob("video/mp4", bytes) text("What is in the video?") } val fullResponse = generativeModel.generateContent(prompt) } }
You can learn more about multimodal prompting in the VertexAI for Firebase documentation.
Note: This method enables you to pass files up to 20 MB. For larger files, use Cloud Storage for Firebase and include the file’s URL in your multimodal request. Read the documentation for more information.
Function calling: Extending the model's capabilities
Function calling enables you to extend the capabilities to generative models. For example you can enable the model to retrieve information in your SQL database and feed it back to the context of the prompt. You can also let the model trigger actions by calling the functions in your app source code. In essence, function calls bridge the gap between the Gemini models and your Kotlin code.
Take the example of a food delivery application that is interested in implementing a conversational interface with the Gemini 1.5 Flash. Assume that this application has a getFoodOrder(cuisine: String) function that returns the list orders from the user for a specific type of cuisine:
fun getFoodOrder(cuisine: String) : JSONObject { // implementation… }
Note that the function, to be usable to by the model, needs to return the response in the form of a JSONObject.
To make the response available to Gemini 1.5 Flash, create a definition of your function that the model will be able to understand using defineFunction:
val getOrderListFunction = defineFunction( name = "getOrderList", description = "Get the list of food orders from the user for a define type of cuisine.", Schema.str(name = "cuisineType", description = "the type of cuisine for the order") ) { cuisineType -> getFoodOrder(cuisineType) }
Then, when you instantiate the model, share this function definition with the model using the tools parameter:
val generativeModel = Firebase.vertexAI.generativeModel( modelName = "gemini-1.5-flash", ... tools = listOf(Tool(listOf(getExchangeRate))) )
Finally, when you get a response from the model, check in the response if the model is actually requesting to execute the function:
// Send the message to the generative model var response = chat.sendMessage(prompt) // Check if the model responded with a function call response.functionCall?.let { functionCall -> // Try to retrieve the stored lambda from the model's tools and // throw an exception if the returned function was not declared val matchedFunction = generativeModel.tools?.flatMap { it.functionDeclarations } ?.first { it.name == functionCall.name } ?: throw InvalidStateException("Function not found: ${functionCall.name}") // Call the lambda retrieved above val apiResponse: JSONObject = matchedFunction.execute(functionCall) // Send the API response back to the generative model // so that it generates a text response that can be displayed to the user response = chat.sendMessage( content(role = "function") { part(FunctionResponsePart(functionCall.name, apiResponse)) } ) } // If the model responds with text, show it in the UI response.text?.let { modelResponse -> println(modelResponse) }
To summarize, you’ll provide the functions (or tools to the model) at initialization:

And when appropriate, the model will request to execute the appropriate function and provide the results:
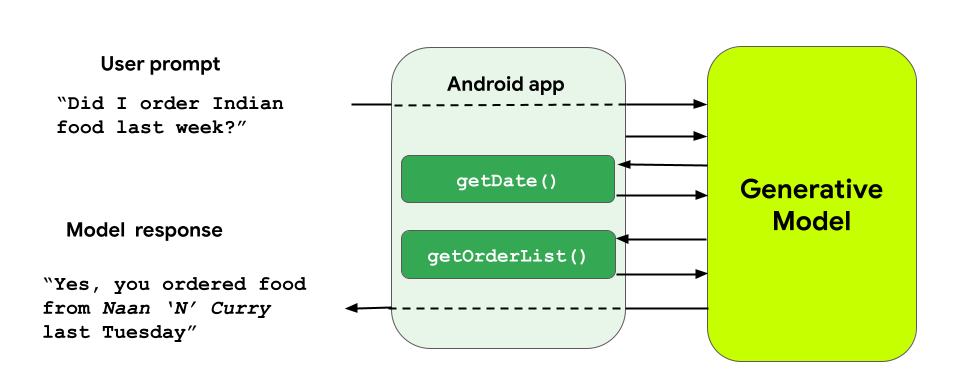
You can read more about function calling in the VertexAI for Firebase documentation.
Unlocking the potential of the Gemini API in your app
The Gemini API offers a treasure trove of advanced features that empower Android developers to craft truly innovative and engaging applications. By going beyond basic text prompts and exploring the capabilities highlighted in this blog post, you can create AI-powered experiences that delight your users and set your app apart in the competitive Android landscape.
Read more about how some Android apps are already starting to leverage the Gemini API.
To learn more about AI on Android, check out other resources we have available during AI on Android Spotlight Week.
Use #AndroidAI hashtag to share your creations or feedback on social media, and join us at the forefront of the AI revolution!
The code snippets in this blog post have the following license:
// Copyright 2024 Google LLC. // SPDX-License-Identifier: Apache-2.0
 Posted by Paul Ruiz – Senior Developer Relations Engineer
Posted by Paul Ruiz – Senior Developer Relations Engineer



 Posted by Kateryna Semenova – Senior Developer Relations Engineer and Mark Sherwood – Senior Product Manager
Posted by Kateryna Semenova – Senior Developer Relations Engineer and Mark Sherwood – Senior Product Manager



 Posted by Terence Zhang – Developer Relations Engineer, and Adrien Couque – Software Engineer
Posted by Terence Zhang – Developer Relations Engineer, and Adrien Couque – Software Engineer


 Posted by Taj Darra – Product Manager
Posted by Taj Darra – Product Manager



 Posted by Joseph Lewis – Technical Writer, Android AI
Posted by Joseph Lewis – Technical Writer, Android AI

 Posted by
Posted by 
.gif)



.png)

