Dave Kleidermacher, Jesse Seed, Brandon Barbello, Sherif Hanna, Eugene Liderman, Android, Pixel, and Silicon Security Teams Every day, billions of people around the world trust Google products to enrich their lives and provide helpful features – across mobile devices, smart home devices, health and fitness devices, and more. We keep more people safe online than anyone else in the world, with products that are secure by default, private by design and that put you in control. As our advancements in knowledge and computing grow to deliver more help across contexts, locations and languages, our unwavering commitment to protecting your information remains.
That’s why Pixel phones are designed from the ground up to help protect you and your sensitive data while keeping you in control. We’re taking our industry-leading approach to security and privacy to the next level with Google Pixel 7 and Pixel 7 Pro, our most secure and private phones yet, which were recently recognized as the highest rated for security when tested among other smartphones by a third-party global research firm.1
Pixel phones also get better every few months with Feature Drops that provide the latest product updates, tips and tricks from Google. And Pixel 7 and Pixel 7 Pro users will receive at least five years of security updates2, so your Pixel gets even more secure over time.
Your protection, built into Pixel
Your digital life and most sensitive information lives on your phone: financial information, passwords, personal data, photos – you name it. With Google Tensor G2 and our custom Titan M2 security chip, Pixel 7 and Pixel 7 Pro have multiple layers of hardware security to help keep you and your personal information safe. We take a comprehensive, end-to-end approach to security with verifiable protections at each layer - the network, application, operating system and multiple layers on the silicon itself. If you use Pixel for your business, this approach helps protect your company data, too.
Google Tensor G2 is Pixel’s newest powerful processor custom built with Google AI, and makes Pixel 7 faster, more efficient and secure3. Every aspect of Tensor G2 was designed to improve Pixel's performance and efficiency for great battery life, amazing photos and videos.
Tensor’s built-in security core works with our Titan M2 security chip to keep your personal information, PINs and passwords safe. Titan family chips are also used to protect Google Cloud data centers and Chromebooks, so the same hardware that protects Google servers also secures your sensitive information stored on Pixel.
And, in a first for Google, Titan M2 hardware has now been certified under Common Criteria PP0084: the international gold standard for hardware security components also used for identity, SIM cards, and bankcard security chips.4 This means that the Titan M2 hardware meets the same rigorous protection guidelines trusted by banks, carriers, and governments.
To achieve the certification we went through rigorous third party lab testing by SGS Brightsight, a leading international security lab, and received certification against CC PP0084 with AVA_VAN.5 for the Titan M2 hardware and cryptography library from the Netherlands scheme for Certification in the Area of IT Security (NSCIB). Of all those numbers and acronyms the part we’re most proud of is that Titan hardware passed the highest level of vulnerability assessment (AVA_VAN.5) - the truest measure of resilience to advanced, methodical attacks.
This process took us more than three years to complete. The certification not only requires chip hardware to resist invasive penetration testing, but also mandates audits of the chip design and manufacturing process itself. The benefit for consumers? The now certified Titan M2 chip makes your phone even more resilient to sophisticated attacks.5
Private by design
Evolving our security and privacy standards to our fast-paced world requires new approaches as well. Earlier this year at I/O, we introduced Protected Computing, a toolkit of technologies that transforms how, when, and where personal data is processed to protect your privacy and security. Our approach focuses on:
- Minimizing your data footprint, by shrinking the amount of personally identifiable data altogether
- De-identifying data, with a range of anonymization techniques so it’s not linked to you
- Restricting data access using technologies like end-to-end encryption and secure enclaves.
Many elements of Protected Computing can be found on the new Pixel 7:
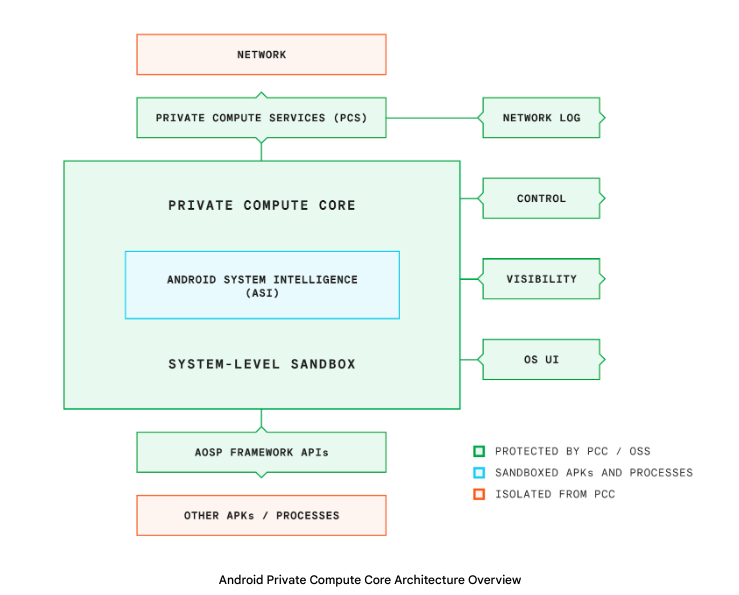
On Android, Private Compute Core keeps your information and AI-driven personalizations private with on-device processing. Data from features like Now Playing, Live Caption and Smart Reply in Messages are all processed on device and are never sent to Google to maintain your privacy. And even your device backups to the cloud are end-to-end encrypted using Titan in the cloud.6
With Google Tensor G2, Pixel’s advanced privacy protection also now covers audio data from events like cough and snore detection on Pixel 7.7 Audio data from cough and snore detection is never stored by or sent to Google to maintain your privacy.
On Pixel 7, Tensor G2 helps safeguard your system with the Android Virtualization Framework, unlocking improved security protections like enabling system update integrity checking to occur on-the-fly, reducing boot time after an update.
Extra protection when you’re online
Helping to keep you safe when you use your phone to browse the web and use apps is also critical. This is where a Virtual Private Network (VPN) comes in. A VPN helps protect your online activity from anyone who might try to access it by encrypting your network traffic to turn it into an unreadable format, and masking your original IP address. Typically, if you want a VPN on your phone, you need to get one from a third party.
To ensure more people have access to enhanced security, later this year, Pixel 7 and Pixel 7 Pro owners will be able to use VPN by Google One, at no extra cost.8 VPN by Google One is verifiably private, and will allow you to tap into Google’s world-class security for peace of mind when you connect online. With VPN by Google One, Pixel helps protect your online activity at a network level. Think of it like an extra layer of protection for your online security.
VPN by Google One creates a high-performance secure connection to the web so your browsing and app data is sent and received via an encrypted pathway. A few simple taps will activate the VPN to help keep your network traffic private from internet providers and hackers, giving you peace of mind when using cellular data, home Wi-Fi, and especially when connected to public networks, like a café or airport Wi-Fi. No need to worry about online intruders, hackers, or unsecure networks.
Unlike traditional VPN services, VPN by Google One uses Protected Computing to technically make it impossible for anyone at a network level, even VPN by Google One, to link your online traffic with your account or identity. VPN by Google One will be available at no extra cost as long as your phone continues to receive security updates. See here to learn more about VPN by Google One.
More protection and privacy with Android 13
Pixel 7 and Pixel 7 Pro have built-in anti-phishing protections from Android that scan for potential threats from phone calls, text messages and emails, and more anti-phishing protections enabled out-of-the-box than smartphones from leading competitors.9 In fact, Messages alone protects consumers against 1.5 billion spam messages per month.
Android also resets permissions for apps you haven’t used for an extended time. In a typical month, Android automatically resets more than 3 billion permissions affecting more than 1 billion installed apps. Similarly, if you use clipboard on Android 13, your history is automatically deleted after a period of time. This blocks apps running in the foreground from seeing old information that you previously copied.
You’re in control
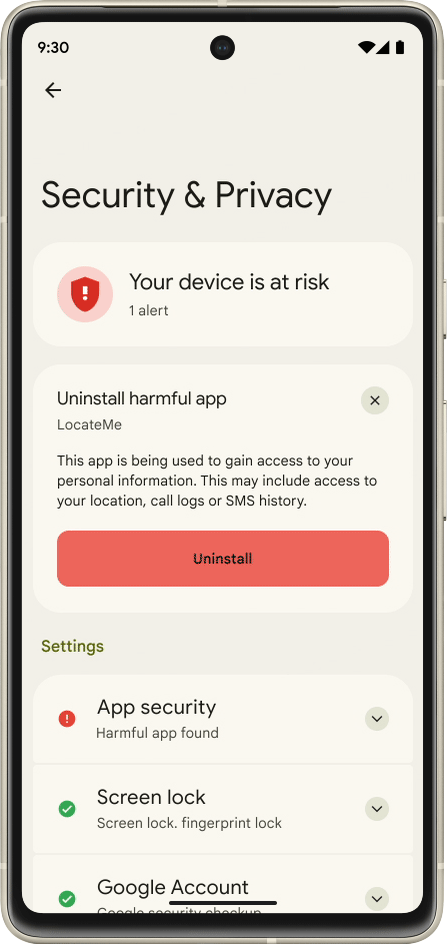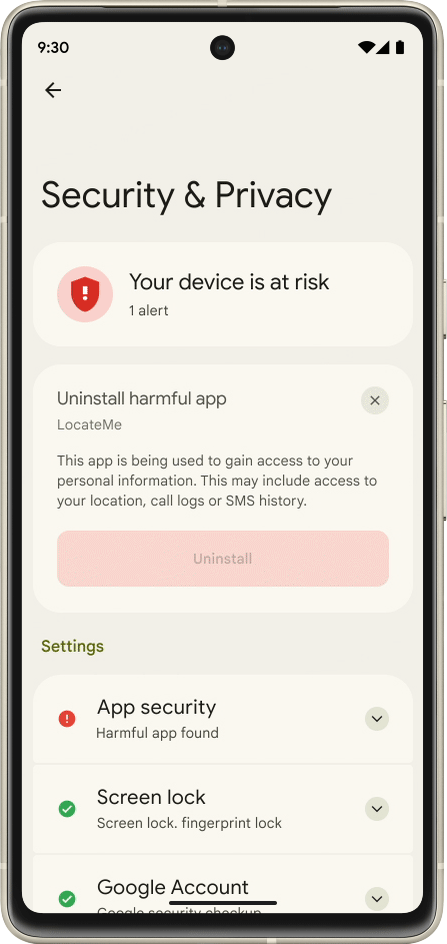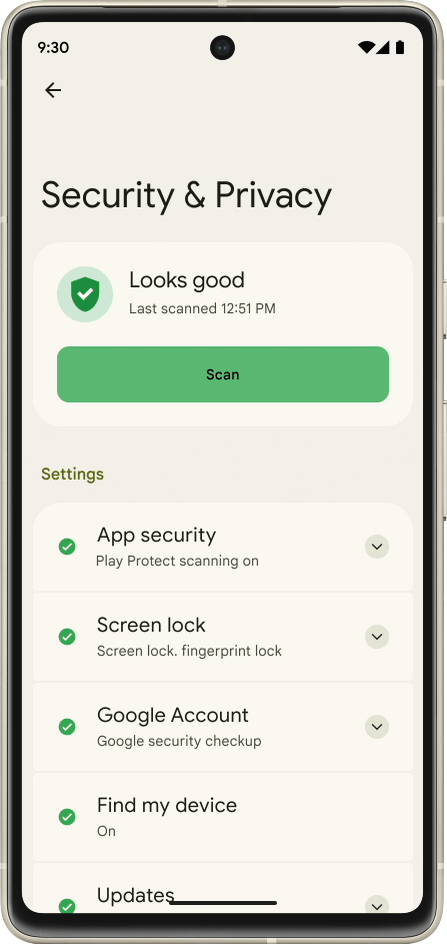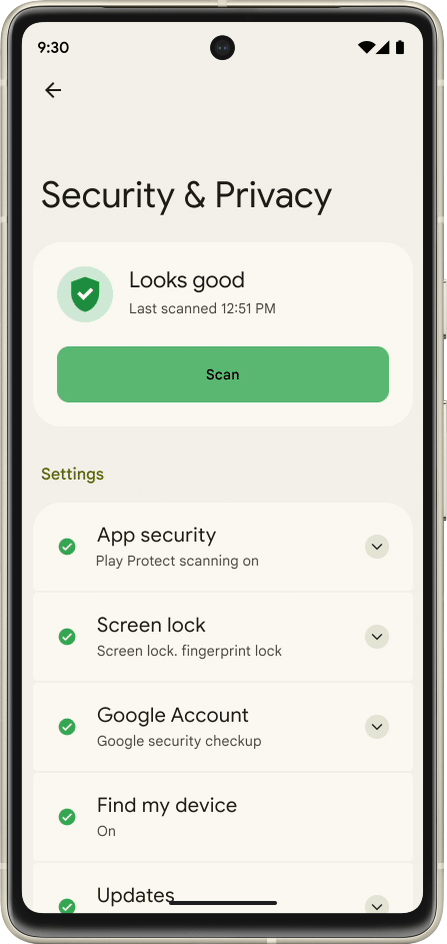
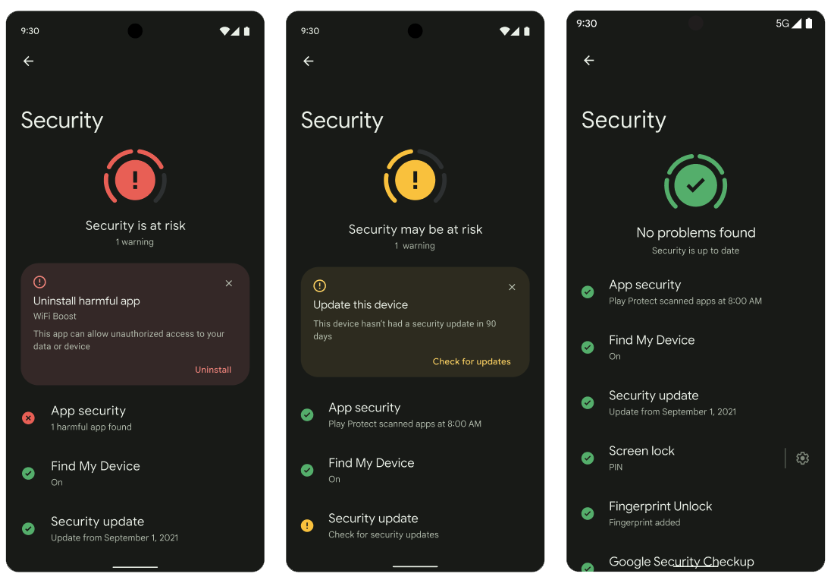
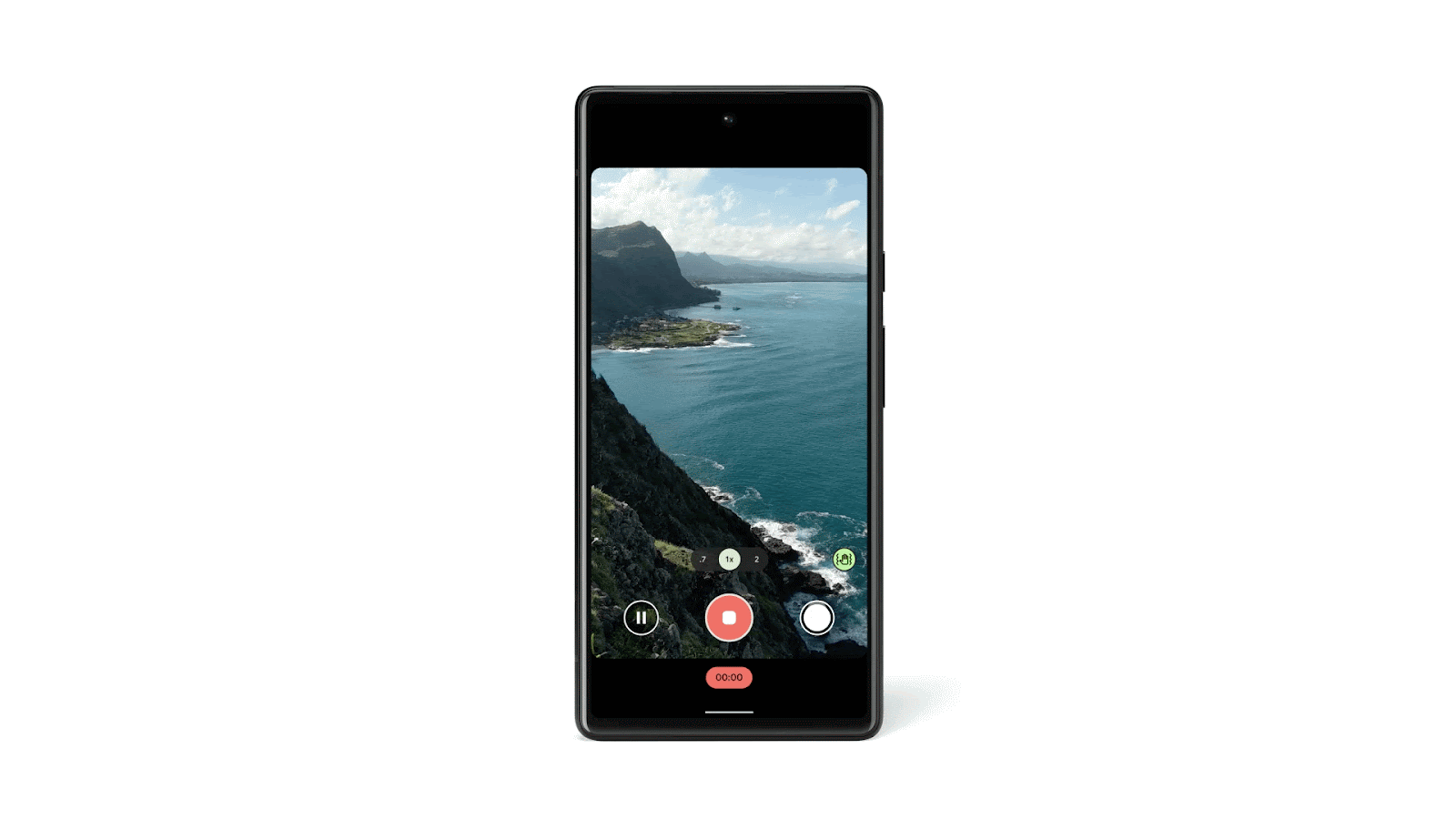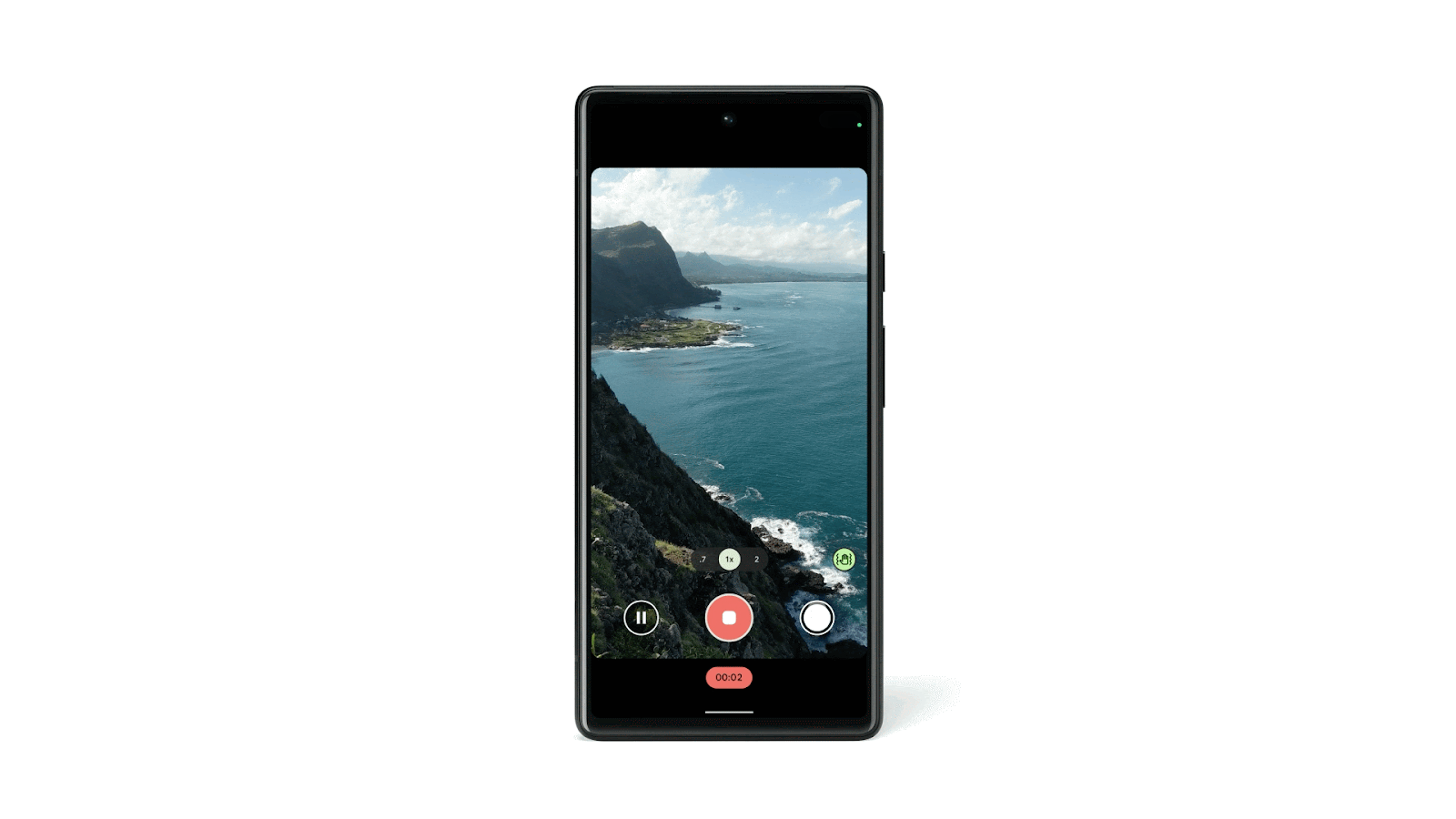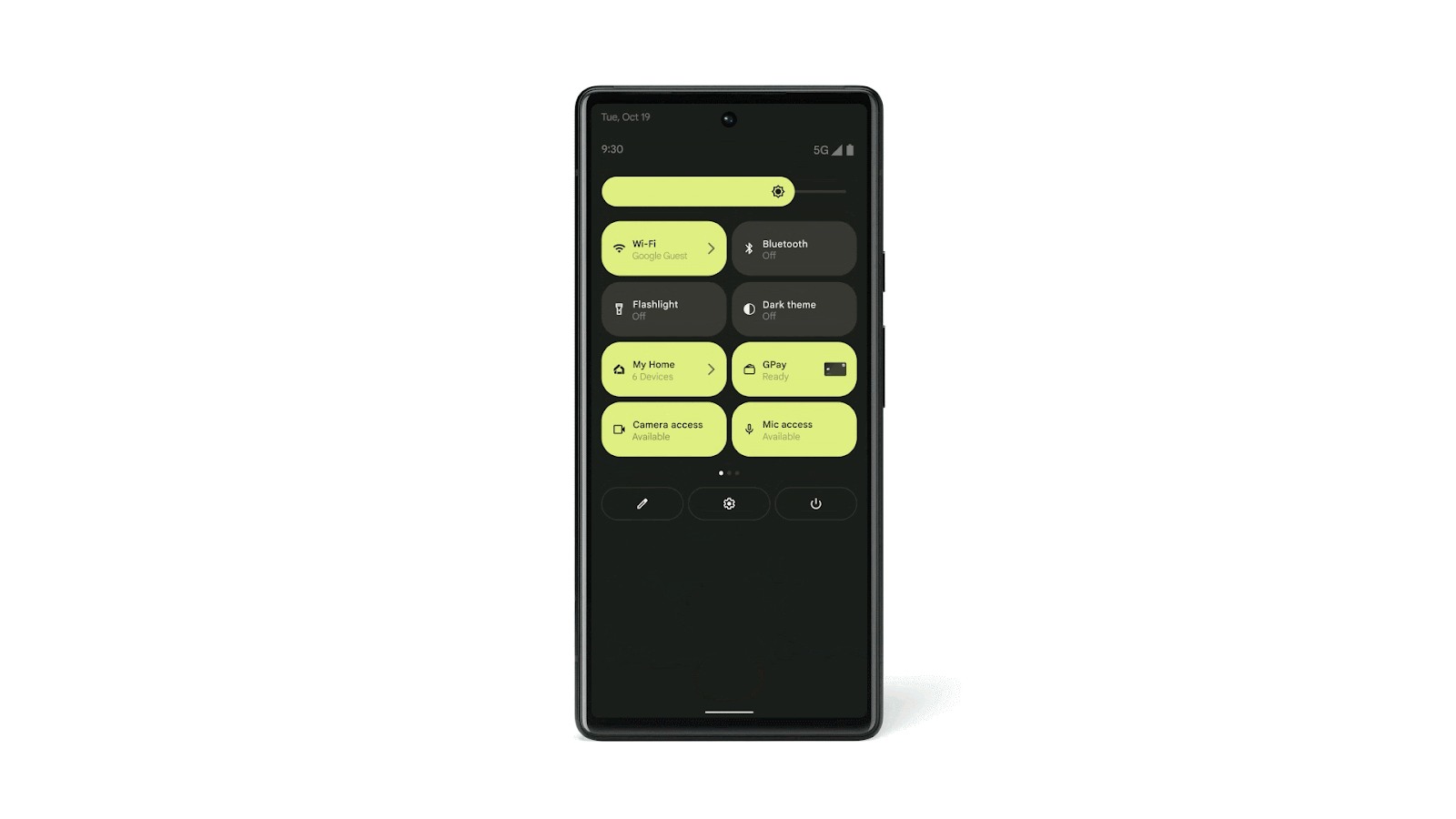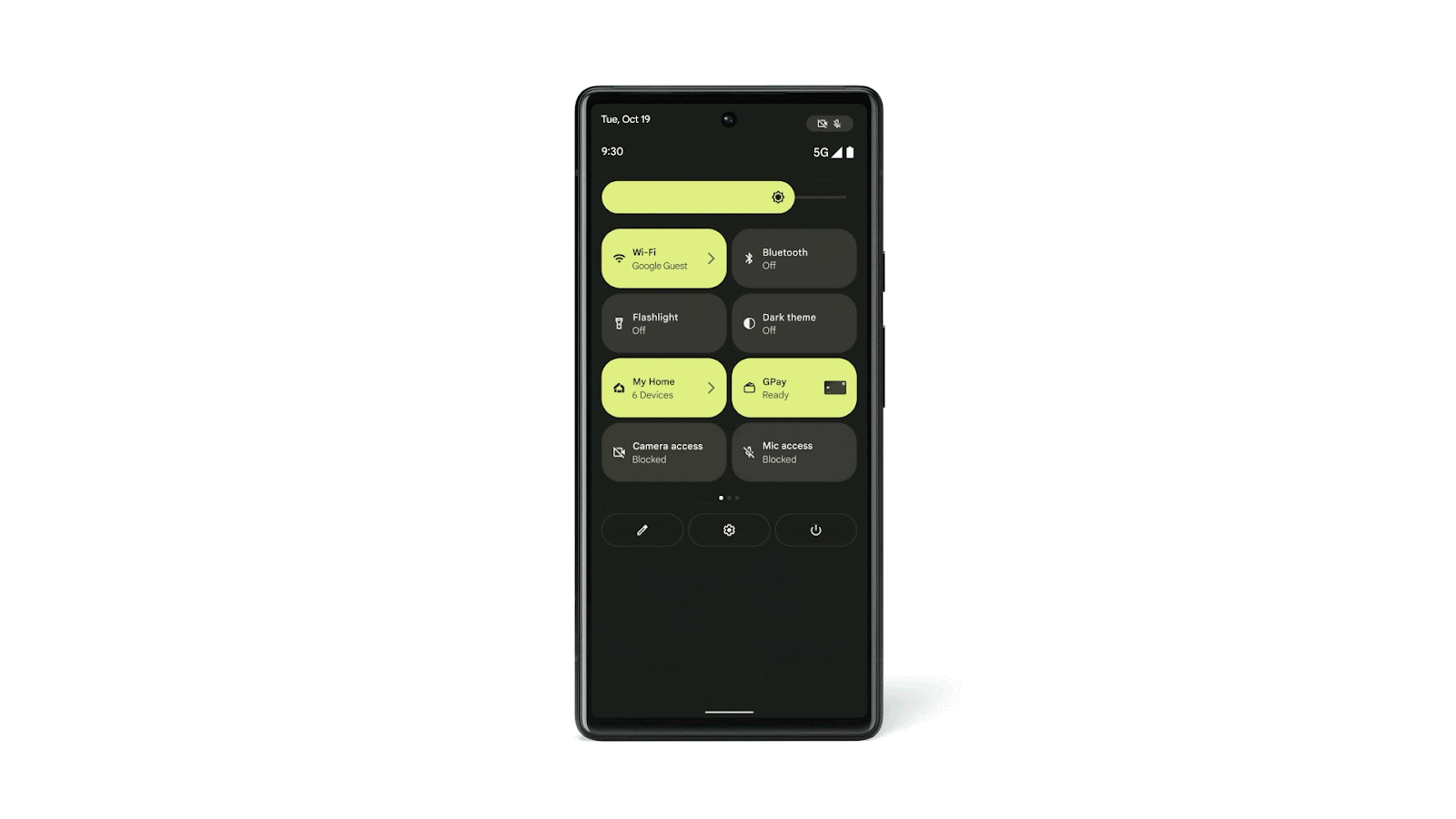
Core to your safety is knowing that you’re in control. You always have control over your settings and devices across all of our products. With Android 13, coming soon through a Feature Drop, Pixel 7 and Pixel 7 Pro will give you additional ways to stay in control of your privacy and what you share with first and third-party apps. With Quick Settings, you can act on security issues as they arise, or review which apps are running in the background and easily stop them. You’ll have a single destination for reviewing your security and privacy settings, risk levels and information, making it easier to manage your safety status.
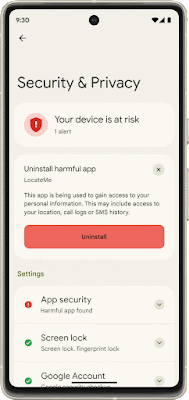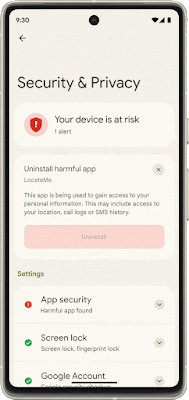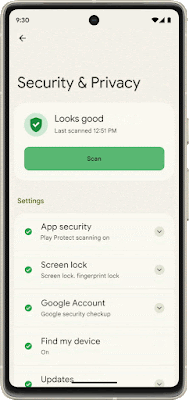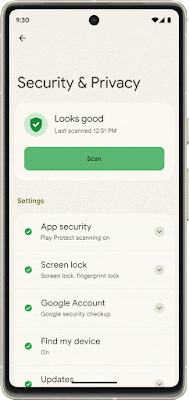
With this new experience, you can review actionable steps to improve your safety status, like revoking a permission or app. This page will also have new action cards to notify you of any safety risks and provide timely recommendations on how to enhance your privacy. And with a single tap, you can grant or remove permissions to data that you don’t want to share with compatible apps. This will be coming soon first to Pixel devices later this year, and other Android phones soon after.
Verifiably secure
As computing extends to more devices and use cases, Google is committed to innovating in security and being transparent about the processes that we take to get there. We are leading the industry in verifiable security by not only having products that are tested against real-world threats (like advanced spam, phishing and malware attacks), but also in publishing the results of penetration tests, security audits, and industry certifications across our Pixel and Nest products.
Another way to verify our security is through our Android and Google Devices Security Reward Program where we reward security researchers who find vulnerabilities across products, including Pixel, Nest and Fitbit. Last year on Android, we awarded nearly $3 million dollars, creating a valuable feedback loop between us and the security research community and, most importantly, helping us keep our users safe.
To learn more about Pixel 7 and Pixel 7 Pro, check out the Google Store.
Notes