ML development and deployment today suffer from fragmented and siloed infrastructure that can differ by framework, hardware, and use case. Such fragmentation restrains developer velocity and imposes barriers to model portability, efficiency, and productionization.
Today, we’re taking a significant step towards eliminating these barriers by making the OpenXLA Project, including the XLA, StableHLO, and IREE repositories, available for use and contribution.
OpenXLA is an open source ML compiler ecosystem co-developed by AI/ML industry leaders including Alibaba, Amazon Web Services, AMD, Apple, Arm, Cerebras, Google, Graphcore, Hugging Face, Intel, Meta, and NVIDIA. It enables developers to compile and optimize models from all leading ML frameworks for efficient training and serving on a wide variety of hardware. Developers using OpenXLA will see significant improvements in training time, throughput, serving latency, and, ultimately, time-to-market and compute costs.
Start accelerating your workloads with OpenXLA on GitHub.
The Challenges with ML Infrastructure Today
Development teams across numerous industries are using ML to tackle complex real-world challenges, such as prediction and prevention of disease, personalized learning experiences, and black hole physics.
As model parameter counts grow exponentially and compute for deep learning models doubles every six months, developers seek maximum performance and utilization of their infrastructure. Teams are leveraging a wider array of hardware from power-efficient ML ASICs in the datacenter to edge processors that can deliver more responsive AI experiences. These hardware devices have bespoke software libraries with unique algorithms and primitives.
However, without a common compiler to bridge these diverse hardware devices to the multiple frameworks in use today (e.g. TensorFlow, PyTorch), significant effort is required to run ML efficiently; developers must manually optimize model operations for each hardware target. This means using bespoke software libraries or writing device-specific code, which requires domain expertise. The result is isolated, non-generalizable paths across frameworks and hardware that are costly to maintain, promote vendor lock-in, and slow progress for ML developers.
Our Solution and Goals
The OpenXLA Project provides a state-of-the-art ML compiler that can scale amidst the complexity of ML infrastructure. Its core pillars are performance, scalability, portability, flexibility, and extensibility for users. With OpenXLA, we aspire to realize the real-world potential of AI by accelerating its development and delivery.Our goals are to:
- Make it easy for developers to compile and optimize any model in their preferred framework, for a wide range of hardware through (1) a unified compiler API that any framework can target (2) pluggable device-specific back-ends and optimizations.
- Deliver industry-leading performance for current and emerging models that (1) scales across multiple hosts and accelerators (2) satisfies the constraints of edge deployments (3) generalizes to novel model architectures of the future.
- Build a layered and extensible ML compiler platform that provides developers with (1) MLIR-based components that are reconfigurable for their unique use cases (2) plug-in points for hardware-specific customization of the compilation flow.
A Community of AI/ML Leaders
The challenges we face in ML infrastructure today are immense and no single organization can effectively resolve them alone. The OpenXLA community brings together developers and industry leaders operating at different levels of the AI stack, from frameworks to compilers, runtimes, and silicon, and is thus well suited to address the fragmentation we see across the ML landscape.As an open source project, we’re guided by the following set of principles:
- Equal footing: Individuals contribute on equal footing regardless of their affiliation. Technical leaders are those who contribute the most time and energy.
- Culture of respect: All members are expected to uphold project values and code of conduct, regardless of their position in the community.
- Scalable, efficient governance: Small groups make consensus-based decisions, with clear but rarely-used paths for escalation.
- Transparency: All decisions and rationale should be legible to the public community.
Performance, Scale, and Portability: Leveraging the OpenXLA Ecosystem
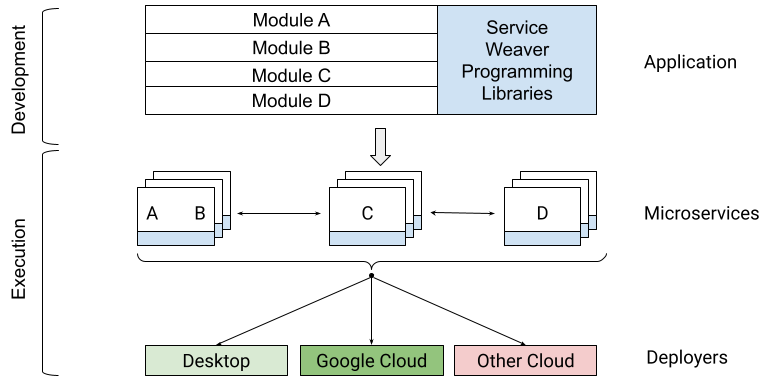
OpenXLA eliminates barriers for ML developers via a modular toolchain that is supported by all leading frameworks through a common compiler interface, leverages standardized model representations that are portable, and provides a domain-specific compiler with powerful target-independent and hardware-specific optimizations. This toolchain includes XLA, StableHLO, and IREE, all of which leverage MLIR: a compiler infrastructure that enables machine learning models to be consistently represented, optimized and executed on hardware. |
| High-level OpenXLA compilation flow and architecture. Depicted optimizations, frameworks and hardware targets represent a select portion of what is available to developers through OpenXLA. |
Spectrum of ML Use Cases
Usage of OpenXLA today spans the gamut of ML use cases. This includes full-scale training of models like DeepMind’s AlphaFold, GPT2 and Swin Transformer on Alibaba Cloud, and multi-modal LLMs for Amazon.com. Users like Waymo leverage OpenXLA for on-vehicle, real-time inference. In addition, OpenXLA is being used to optimize serving of Stable Diffusion on AMD RDNA™ 3-equipped local machines.
Optimal Performance, Out of the Box
OpenXLA makes it easy for developers to speed up model performance without needing to write device-specific code. It features whole-model optimizations including simplification of algebraic expressions, optimization of in-memory data layout, and improved scheduling for reduced peak memory use and communication overhead. Advanced operator fusion and kernel generation help improve device utilization and reduce memory bandwidth requirements.
Scale Workloads With Minimal Effort
Developing efficient parallelization algorithms is time-consuming and requires expertise. With features like GSPMD, developers only need to annotate a subset of critical tensors that the compiler can then use to automatically generate a parallelized computation. This removes much of the work required to partition and efficiently parallelize models across multiple hardware hosts and accelerators.
Portability and Optionality
OpenXLA provides out-of-the-box support for a multitude of hardware devices including AMD and NVIDIA GPUs, x86 CPU and Arm architectures, as well as ML accelerators like Google TPUs, AWS Trainium and Inferentia, Graphcore IPUs, Cerebras Wafer-Scale Engine, and many more. OpenXLA additionally supports TensorFlow, PyTorch, and JAX via StableHLO, a portability layer that serves as OpenXLA's input format.
Flexibility
OpenXLA gives users the flexibility to manually tune hotspots in their models. Extension mechanisms such as Custom-call enable users to write deep learning primitives with CUDA, HIP, SYCL, Triton and other kernel languages so they can take full advantage of hardware features.
StableHLO
StableHLO, a portability layer between ML frameworks and ML compilers, is an operation set for high-level operations (HLO) that supports dynamism, quantization, and sparsity. Furthermore, it can be serialized into MLIR bytecode to provide compatibility guarantees. All major ML frameworks (JAX, PyTorch, TensorFlow) can produce StableHLO. Through 2023, we plan to collaborate closely with the PyTorch team to enable an integration to the recent PyTorch 2.0 release.
We’re excited for developers to get their hands on these features and many more that will significantly accelerate and simplify their ML workflows.
Moving Forward Together
The OpenXLA Project is being built by a collaborative community, and we're excited to help developers extend and use it to address the gaps and opportunities we see in the ML industry today. Get started with OpenXLA today on GitHub and sign up for our mailing list here for product and community announcements. You can follow us on Twitter: @OpenXLAMember Quotes
Here’s what our collaborators are saying about OpenXLA:
Alibaba
“At Alibaba, OpenXLA is leveraged by Elastic GPU Service customers for training and serving of large PyTorch models. We’ve seen significant performance improvements for customers using OpenXLA, notably speed-ups of 72% for GPT2 and 88% for Swin Transformer on NVIDIA GPUs. We're proud to be a founding member of the OpenXLA Project and work with the open-source community to develop an advanced ML compiler that delivers superior performance and user experience for Alibaba Cloud customers.” – Yangqing Jia, VP, AI and Data Analytics, Alibaba