Posted by Santiago Aboy Solanes - Software Engineer
Posted by Santiago Aboy Solanes - Software Engineer

The Android Runtime (ART) executes Dalvik bytecode produced from apps and system services written in the Java or Kotlin languages. We constantly improve ART to generate smaller and more performant code. Improving ART makes the system and user-experience better as a whole, as it is the common denominator in Android apps. In this blog post we will talk about optimizations that reduce code size without impacting performance.
Code size is one of the key metrics we look at, since smaller generated files are better for memory (both RAM and storage). With the new release of ART, we estimate saving users about 50-100MB per device. This could be just the thing you need to be able to update your favorite app, or download a new one. Since ART has been updateable from Android 12, these optimizations reach 1B+ devices for whom we are saving 47-95 petabytes (47-95 millions of GB!) globally!
All the improvements mentioned in this blog post are open source. They are available through the ART mainline update so you don’t even need a full OS update to reap the benefits. We can have our upside-down cake and eat it too!
Optimizing compiler 101
ART compiles applications from the DEX format to native code using the on-device dex2oat tool. The first step is to parse the DEX code and generate an Intermediate Representation (IR). Using the IR, dex2oat performs a number of code optimizations. The last step of the pipeline is a code generation phase where dex2oat converts the IR into native code (for example, AArch64 assembly).
The optimization pipeline has phases that execute in order that each concentrate on a particular set of optimizations. For example, Constant Folding is an optimization that tries to replace instructions with constant values like folding the addition operation 2 + 3 into a 5.
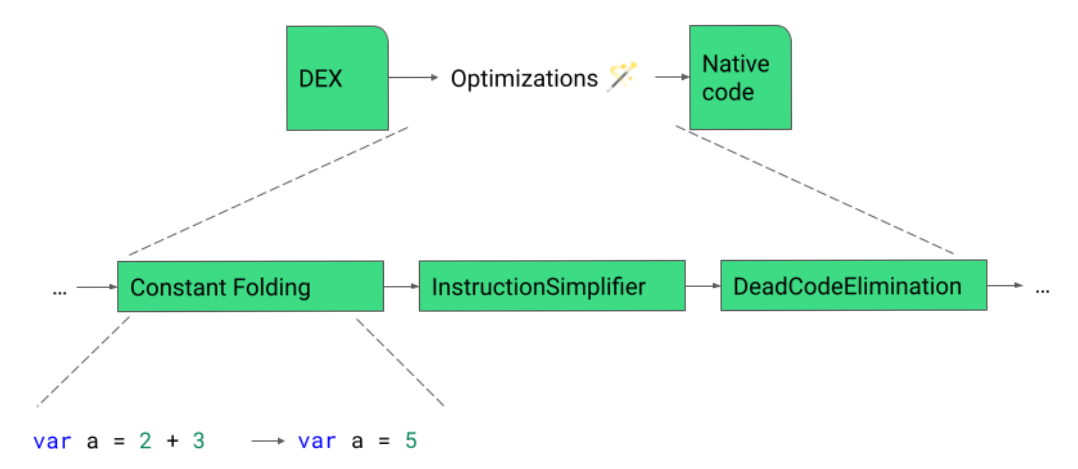
The IR can be printed and visualized, but is very verbose compared to Kotlin language code. For the purposes of this blog post, we will show what the optimizations do using Kotlin language code, but know that they are happening to IR code.
Code size improvements
For all code size optimizations, we tested our optimizations on over half a million APKs present in the Google Play Store and aggregated the results.
Eliminating write barriers
We have a new optimization pass that we named Write Barrier Elimination. Write barriers track modified objects since the last time they were examined by the Garbage Collector (GC) so that the GC can revisit them. For example, if we have:
 Previously, we would emit a write barrier for each object modification but we only need a single write barrier because: 1) the mark will be set in o itself (and not in the inner objects), and 2) a garbage collection can't have interacted with the thread between those sets.
Previously, we would emit a write barrier for each object modification but we only need a single write barrier because: 1) the mark will be set in o itself (and not in the inner objects), and 2) a garbage collection can't have interacted with the thread between those sets.If an instruction may trigger a GC (for example, Invokes and SuspendChecks), we wouldn't be able to eliminate write barriers. In the following example, we can't guarantee a GC won't need to examine or modify the tracking information between the modifications:
 Implementing this new pass contributes to 0.8% code size reduction.
Implementing this new pass contributes to 0.8% code size reduction.
Implicit suspend checks
Let's assume we have several threads running. Suspend checks are safepoints (represented by the houses in the image below) where we can pause the thread execution. Safepoints are used for many reasons, the most important of them being Garbage Collection. When a safepoint call is issued, the threads must go into a safepoint and are blocked until they are released.
The previous implementation was an explicit boolean check. We would load the value, test it, and branch into the safepoint if needed.
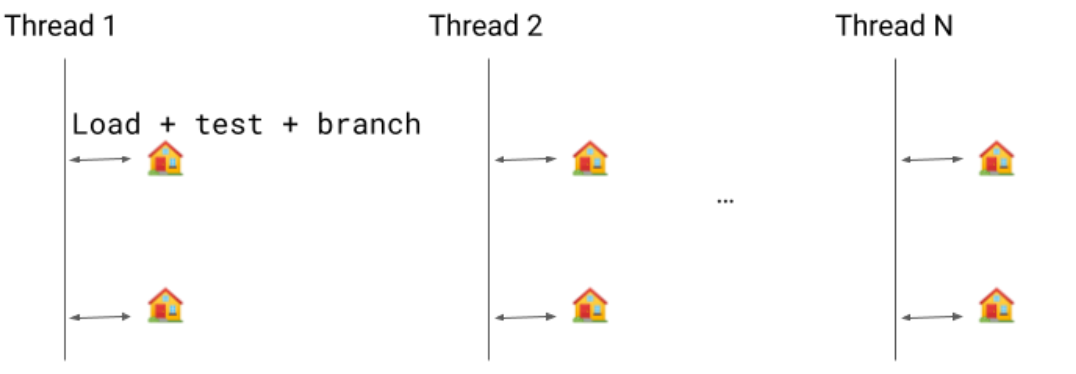
Implicit suspend checks is an optimization that eliminates the need for the test and branch instructions. Instead, we only have one load: if the thread needs to suspend, that load will trap and the signal handler will redirect the code to a suspend check handler as if the method made a call.
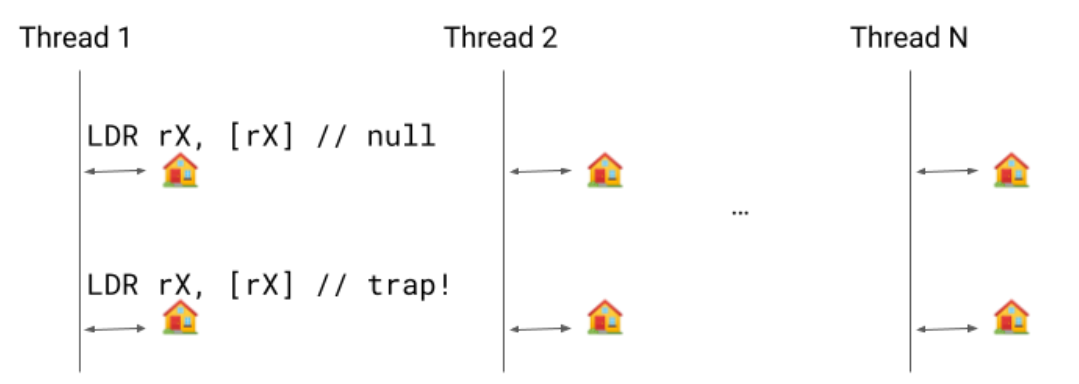
Going into a bit more detail, a reserved register rX is pre-loaded with an address within the thread where we have a pointer pointing to itself. As long as we don't need to do a suspend check, we keep that self-pointing pointer. When we need to do a suspend check, we clear the pointer and once it becomes visible to the thread the first LDR rX, [rX] will load null and the second will segfault.
The suspend request is essentially asking the thread to suspend some time soon, so the minor delay of having to wait for the second load is okay.
This optimization reduces code size by 1.8%.
Coalescing returns
It is common for compiled methods to have an entry frame. If they have it, those methods have to deconstruct it when they return, which is also known as an exit frame. If a method has several return instructions, it will generate several exit frames, one per return instruction.
By coalescing the return instructions into one, we are able to have one return point and are able to remove the extra exit frames. This is especially useful for switch cases with multiple return statements.

Coalescing returns reduces code size by 1%.
Other optimization improvements
We improved a lot of our existing optimization passes. For this blog post, we will group them up in the same section, but they are independent of each other. All the optimizations in the following section contribute to a 5.7% code size reduction.
Code Sinking
Code sinking is an optimization pass that pushes down instructions to uncommon branches like paths that end with a throw. This is done to reduce wasted cycles on instructions that are likely not going to be used.
We improved code sinking in graphs with try catches: we now allow sinking code as long as we don't sink it inside of a different try than the one it started in (or inside of any try if it wasn't in one to begin with).

In the first example, we can sink the Object creation since it will only be used in the if(flag) path and not the other and it is within the same try. With this change, at runtime it will only be run if flag is true. Without getting into too much technical detail, what we can sink is the actual object creation, but loading the Object class still remains before the if. This is hard to show with Kotlin code, as the same Kotlin line turns into several instructions at the ART compiler level.
In the second example, we cannot sink the code as we would be moving an instance creation (which may throw) inside of another try.
Code Sinking is mostly a runtime performance optimization, but it can help reduce the register pressure. By moving instructions closer to their uses, we can use fewer registers in some cases. Using fewer registers means fewer move instructions, which ends up helping code size.
Loop optimization
Loop optimization helps eliminate loops at compile time. In the following example, the loop in foo will multiply a by 10, 10 times. This is the same as multiplying by 100. We enabled loop optimization to work in graphs with try catches.

In foo, we can optimize the loop since the try catch is unrelated.
In bar or baz, however, we don't optimize it. It is not trivial to know the path the loop will take if we have a try in the loop, or if the loop as a whole is inside of a try.
Dead code elimination – Remove unneeded try blocks
We improved our dead code elimination phase by implementing an optimization that removes try blocks that don't contain throwing instructions. We are also able to remove some catch blocks, as long as no live try blocks point to it.
In the following example, we inline bar into foo. After that, we know that the division cannot throw. Later optimization passes can leverage this and improve the code.
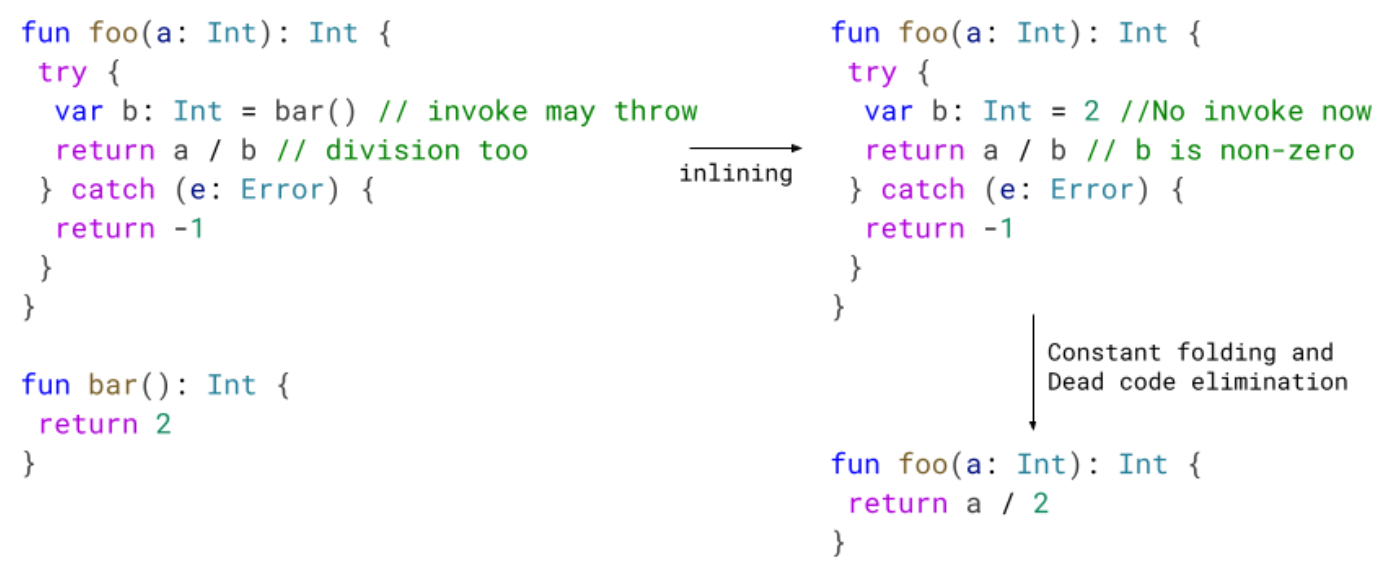
Just removing the dead code from the try catch is good enough, but even better is the fact that in some cases we allow other optimizations to take place. If you recall, we don't do loop optimization when the loop has a try, or it's inside of one. By eliminating this redundant try/catch, we can loop optimize producing smaller and faster code.

Dead code elimination – SimplifyAlwaysThrows
During the dead code elimination phase, we have an optimization we call SimplifyAlwaysThrows. If we detect that an invoke will always throw, we can safely discard whatever code we have after that method call since it will never be executed.
We also updated SimplifyAlwaysThrows to work in graphs with try catches, as long as the invoke itself is not inside of a try. If it is inside of a try, we might jump to a catch block, and it gets harder to figure out the exact path that will be executed.

We also improved:
- Detection when an invoke will always throw by looking at their parameters. On the left, we will mark divide(1, 0) as always throwing even when the generic method doesn't always throw.
- SimplifyAlwaysThrows to work on all invokes. Previously we had restrictions for example don't do it for invokes leading to an if, but we could remove all of the restrictions.

Load Store Elimination – Working with try catch blocks
Load store elimination (LSE) is an optimization pass that removes redundant loads and stores.
We improved this pass to work with try catches in the graph. In foo, we can see that we can do LSE normally if the stores/loads are not directly interacting with the try. In bar, we can see an example where we either go through the normal path and don't throw, in which case we return 1; or we throw, catch it and return 2. Since the value is known for every path, we can remove the redundant load.

Load Store Elimination – Working with release/acquire operations
We improved our load store elimination pass to work in graphs with release/acquire operations. These are volatile loads, stores, and monitor operations. To clarify, this means that we allow LSE to work in graphs that have those operations, but we don't remove said operations.
In the example, i and j are regular ints, and vi is a volatile int. In foo, we can skip loading the values since there's not a release/acquire operation between the sets and the loads. In bar, the volatile operation happens between them so we can't eliminate the normal loads. Note that it doesn't matter that the volatile load result is not used—we cannot eliminate the acquire operation.

This optimization works similarly with volatile stores and monitor operations (which are synchronized blocks in Kotlin).
New inliner heuristic
Our inliner pass has a wide range of heuristics. Sometimes we decide not to inline a method because it is too big, or sometimes to force inlining of a method because it is too small (for example, empty methods like Object initialization).
We implemented a new inliner heuristic: Don't inline invokes leading to a throw. If we know we are going to throw we will skip inlining those methods, as throwing itself is costly enough that inlining that code path is not worth it.
We had three families of methods that we are skipping to inline:
- Calculating and printing debug information before a throw.
- Inlining the error constructor itself.
- Finally blocks are duplicated in our optimizing compiler. We have one for the normal case (i.e. the try doesn't throw), and one for the exceptional case. We do this because in the exceptional case we have to: catch, execute the finally block, and rethrow. The methods in the exceptional case will now not be inlined, but the ones in the normal case will.

Constant folding
Constant folding is the optimization pass that changes operations into constants if possible. We implemented an optimization that propagates variables known to be constant when used in if guards. Having more constants in the graph allows us to perform more optimizations later.
In foo, we know that a has the value 2 in the if guard. We can propagate that information and deduce that b must be 4. In a similar vein, in bar we know that cond must be true in the if case and false in the else case (simplifying the graphs).

Putting it all together
If we take into account all code size optimizations in this blog post we achieved a 9.3% code size reduction!
To put things into perspective, an average phone can have 500MB-1GB in optimized code (The actual number can be higher or lower, depending on how many apps you have installed, and which particular apps you installed), so these optimizations save about 50-100MB per device. Since these optimizations reach 1B+ devices, we are saving 47-95 petabytes globally!
Further reading
If you are interested in the code changes themselves, feel free to take a look. All the improvements mentioned in this blog post are open source. If you want to help Android users worldwide, consider contributing to the Android Open Source Project!
- Write barrier elimination: 1
- Implicit suspend checks: 1
- Coalescing returns: 1
- Code sinking: 1, 2
- Loop optimization: 1
- Dead code elimination: 1, 2, 3, 4
- Load store elimination: 1, 2, 3, 4
- New inlining heuristic: 1
- Constant folding: 1
Java is a trademark or registered trademark of Oracle and/or its affiliates