[Editor’s note: Smash.gg is an esports platform used by players and organizers worldwide, running nearly 2,000 events per month with 60,000+ competitors, and recently hosted brackets for EVO 2017, the world’s largest fighting game tournament. This is its first post in a multi-part series about migrating to Google Cloud Platform (GCP) — what got them interested in GCP, why they migrated to it, and a few of the benefits they’ve seen as a result. Stay tuned for future posts that will cover more technical details about migrating specific services.]
Players in online tournaments running on smash.gg need to be able to interact in real time. Both entrants must confirm that they are present, set up the game, and reach a consensus on the results of the match. They also need a simple chat service to resolve any issues with joining or reporting the match, to talk to one another and to tournament moderators.
We built our initial implementation of online match reporting with an off-the-shelf chat service and UI interactions that weren’t truly real-time. When the chat service failed in a live tournament, it became clear that we needed a better solution. We looked into building our own using a websocket-based approach, and a few services like PubNub and Firebase. Ultimately, we decided to launch with Firebase because it’s widely used, is backed by Google, and is incredibly well-priced.
 |
| Two players checking into, setting up, and reporting an online match using the Firebase Realtime Database for real-time interactions. |
We got our start with Firebase in May, 2016. Our first release used the Firebase Realtime Database as a kind of real-time cache to keep match data in sync between both entrants. When matches were updated or reported on our backend, we also wrote the updated match data to Firebase. We use React and Flux so we made a wrapper component to listen to Firebase and dispatch updated match data to our Flux stores. Implementing a chat service with Firebase was similarly easy. Using Firechat as inspiration, it took us about a day to build the initial implementation and another day to make it production-ready.
Compared with rolling our own solution, Firebase was an obvious choice given the ease of development and time/financial cost savings. Ultimately, it reduced the load on our servers, simplified our reporting flow, and made the match experience truly real-time. Later that year, we started using Firebase Cloud Messaging (FCM) to send browser push notifications using Cloud Functions triggers as Firebase data changed (e.g., to notify admins of moderator requests). Like the Realtime Database, Cloud Functions was incredibly easy to use and felt magical the first time we used it. Cloud Functions also gave us a window into how well Firebase interacts with Google Cloud Platform (GCP) services like Cloud Pub/Sub and Google BigQuery.
Migrating to GCP
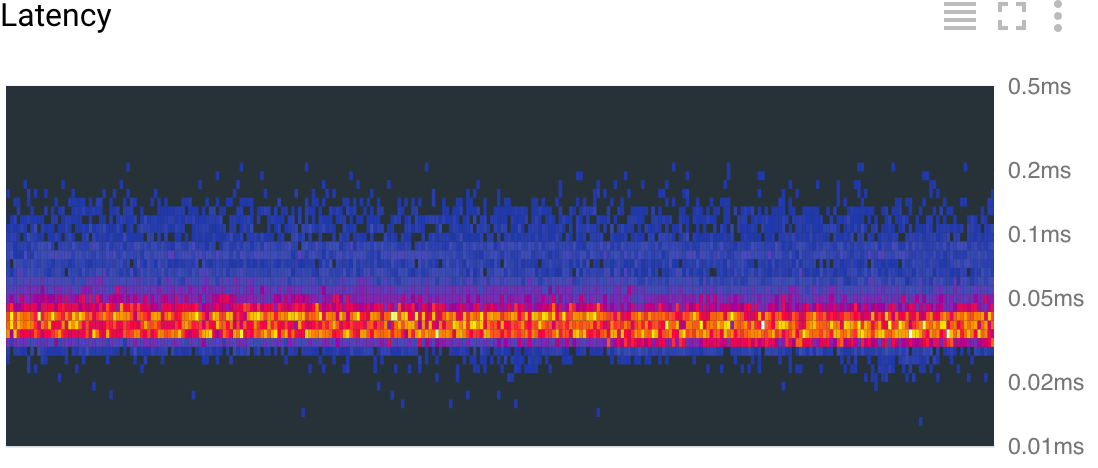
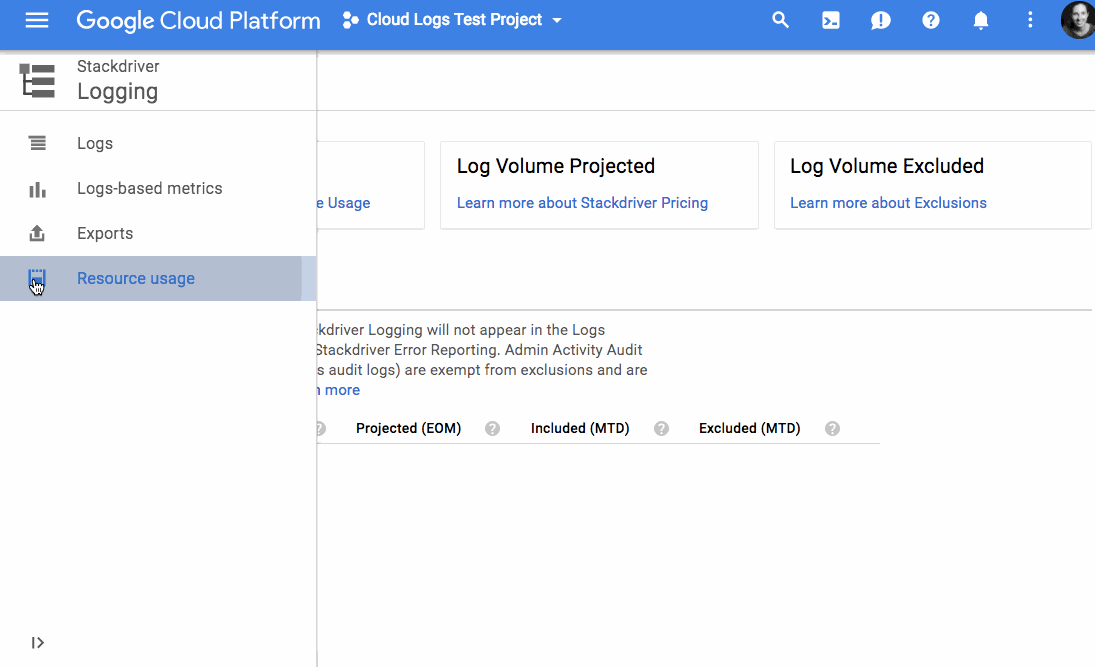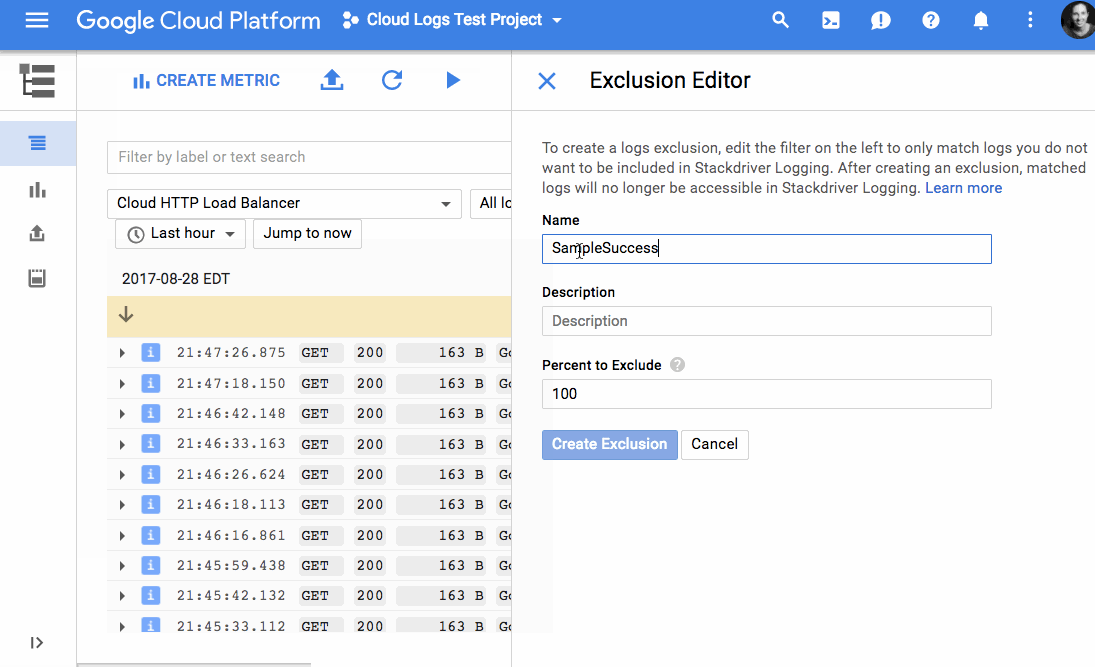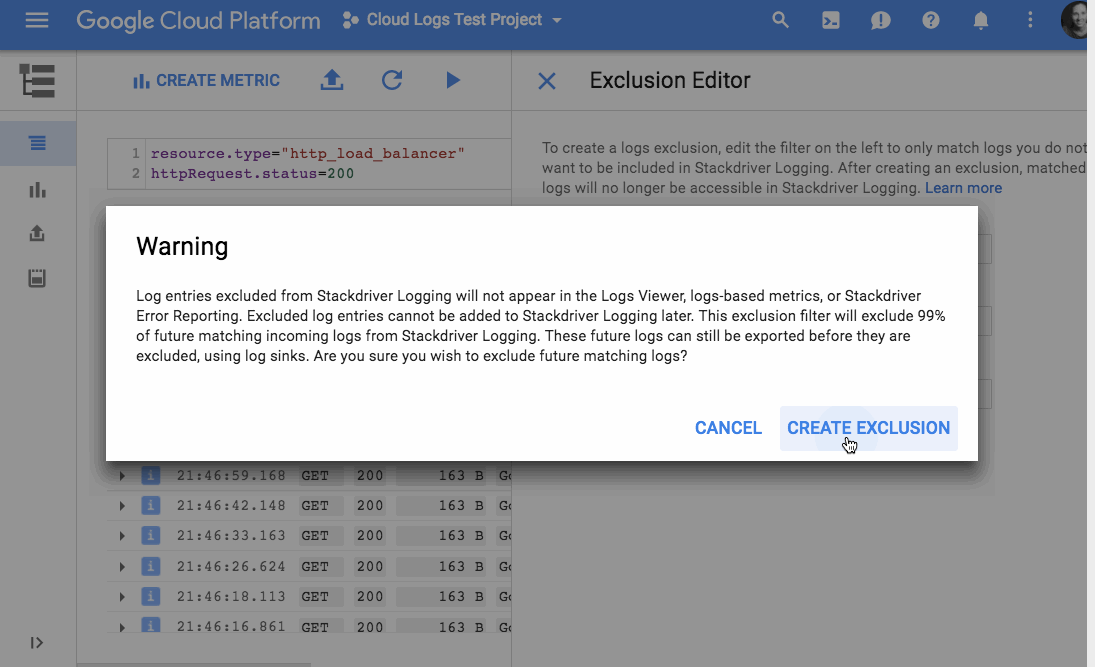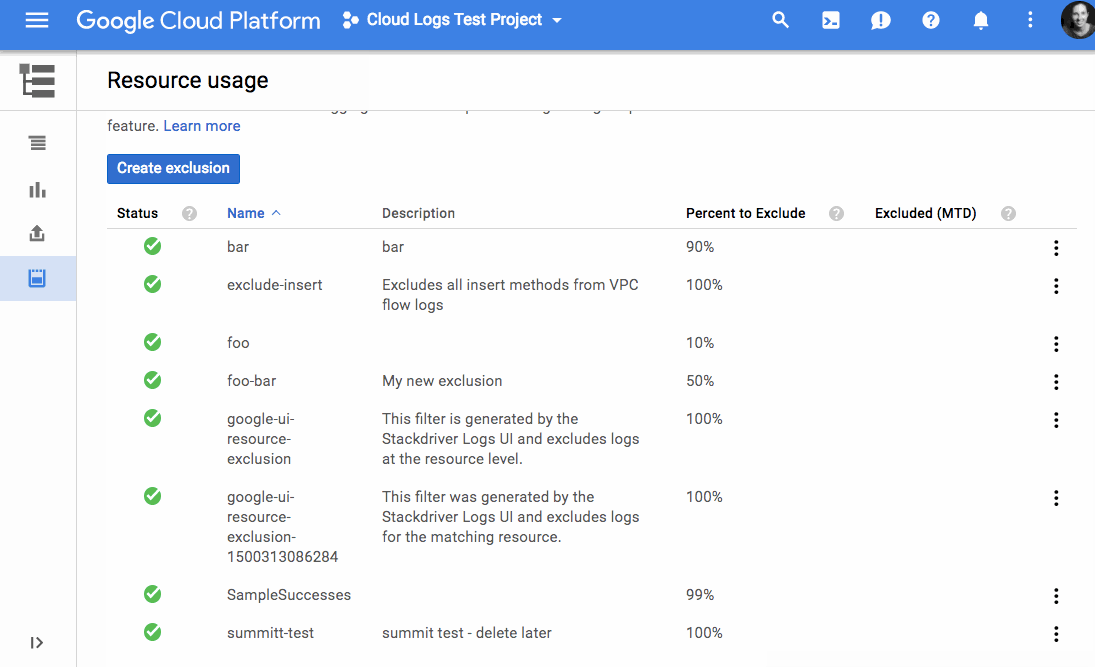
In March of 2017 we attended Google Cloud Next '17 for the Cloud Functions launch. There, we saw that other GCP products had a similar focus on improving the developer experience and lowering development costs. Current products like Pub/Sub, Stackdriver Trace and Logging, and Google Cloud Datastore solved some of our immediate needs. Out of the box, these services gave us things that we were planning to build to supplement products from our existing service provider. And broadly speaking, GCP products seemed to focus on improving core developer workflows to reduce development and maintenance time. After seeing some demos of the products interacting (e.g., Google Container Engine and App Engine with Stackdriver Trace/Logging, Stackdriver with Pub/Sub and BigQuery), we decided to evaluate a full migration.We started migrating our application in mid May, using the following services: Container Engine, Pub/Sub, Google Cloud SQL, Datastore, BigQuery, and Stackdriver. During the migration, we took the opportunity to re-architect some of our core services and move to Kubernetes. Most of our application was already containerized but had previously been running on a PaaS-like service so Kubernetes was a fairly dramatic shift. While Kubernetes had many benefits (e.g., industry standard, more efficient use of cloud instances, application portability, and immutable infrastructure defined in code), we also lost some top-level application metrics that our previous PaaS service had provided: for instance overall Requests Per Second (RPS), RPS by status, and latency. We were able to easily recreate these graphs from our container logs using log-based metrics and logs export from Stackdriver to BigQuery. You could also do this using other services, but our GCP-only approach was a quick and mostly free way for us to get to parity while experimenting with GCP services.
Request timing and analysis using Stackdriver Trace was another selling point in GCP that we didn’t have with our previous service. However, at the time of our migration, the Trace SDK for PHP (our backend services are in PHP, but I promise it’s nice PHP!) didn’t support asynchronous traces. The Google Cloud SDK for PHP has since added async trace support, but we were able to build async tracing by quickly gluing some GCP services together:
- We built a trace reporter to log out traces as JSON.
- We then sent the traces to a Pub/Sub topic using Stackdriver log exports.
- Finally, we made a Pub/Sub subscriber in Cloud Functions to report the traces using the REST API.
The Google Cloud SDK is certainly a more appropriate solution for tracing in production, but the fact that this combination of services worked well speaks to how easy it is to develop in GCP.
Post-migration results
After running our production environment on GCP for a month, we’ve saved both time and money. Overall costs are ~10% lower without any Committed Use Discounts, with capacity to spare. Stackdriver logging/monitoring, Container Engine, and Kubernetes have made it easier for our engineers to perform DevOps tasks, leveling up our entire team. And being able to search all our logs in one centralized place allows us to easily cross-reference logs from multiple systems, making it possible to track down root causes of issues much faster. This combined with fully-managed, usage-priced services like Datastore and Firebase means development on GCP is easier and more accessible to all of our engineers. We’re really glad we migrated to GCP, and look forward to telling you more about how we did it in future posts. Meanwhile, if you’re a developer who loves competitive play and would like to help us build cool things on top of GCP, we’d love to hear from you. We recently closed our Series A from Spark Capital, Accel, and Horizon Ventures, and we're hiring!