What caught your attention this month: Creating the open cloud
- One of the most-read posts this month covered the launch of our Cloud Services Platform, which allows you to build a true hybrid cloud infrastructure. Some of the key components of Cloud Services Platform include the managed Istio service mesh, Google Kubernetes Engine (GKE) On-Prem and GKE Policy Management, Cloud Build for fully managed CI/CD, and several serverless offerings (more on that below). Combined, these technologies can help you gain consistency, security, speed and flexibility of the cloud in your local data center, along with the freedom of workload portability to the environment of your choice.
- Another popular read was a rundown of Google Cloud’s new serverless offerings. These include core serverless compute announcements such as new App Engine runtimes, Cloud Functions general availability and more. It also included serverless containers, so you can run serverless workloads in a fully managed container environment; GKE Serverless add-on to easily run serverless workloads on Kubernetes Engine; and Knative, the open-source project on which that add-on is built. There are even more features included in this post, too, like Cloud Build, Stackdriver monitoring and Cloud Firestore integration with GCP.
Bringing detailed metrics and Kubernetes apps to the forefront
- Another must-read post this month for many of you was Transparent SLIs: See Google Cloud the way your application experiences it, announcing the availability of detailed data insights on GCP services that your workloads use—helping you see like a Google site reliability engineer (SRE). These new service-level indicators (SLIs) go way beyond basic uptime and downtime to delve into response codes, latency and more. You can then separate out metrics by GCP service to see things like API version, location and protocol. The result is that you can filter and sort to get extremely fine-grained information on your software and the GCP services you use, which helps cut resolution times and improve the support experience. Transparent SLIs are available now through the Stackdriver monitoring console. Learn more here about the basics of using SLIs and other SRE tools to measure and manage availability.
- It’s also now faster and easier to find production-ready commercial Kubernetes apps in the GCP Marketplace. These apps are prepackaged and configured to get up and running easily, whether on Kubernetes Engine or other Kubernetes clusters, and run the gamut from security, data analytics and developer tools to storage, machine learning and monitoring.
There was obviously a lot to talk about at the show, and you can get even more detail on what happened at Next ‘18 here.
Building the cloud back-end
- For all of you developing cloud apps with Java, the availability of Jib was an exciting announcement last month. This open-source container image builder, available as Gradle and Maven plugins, cuts out several steps from the Docker build flow. Jib does all the work required to package your app into a container image—you don’t need to write a Dockerfile or even have Docker installed. You end up with faster builds and reproducible container images.
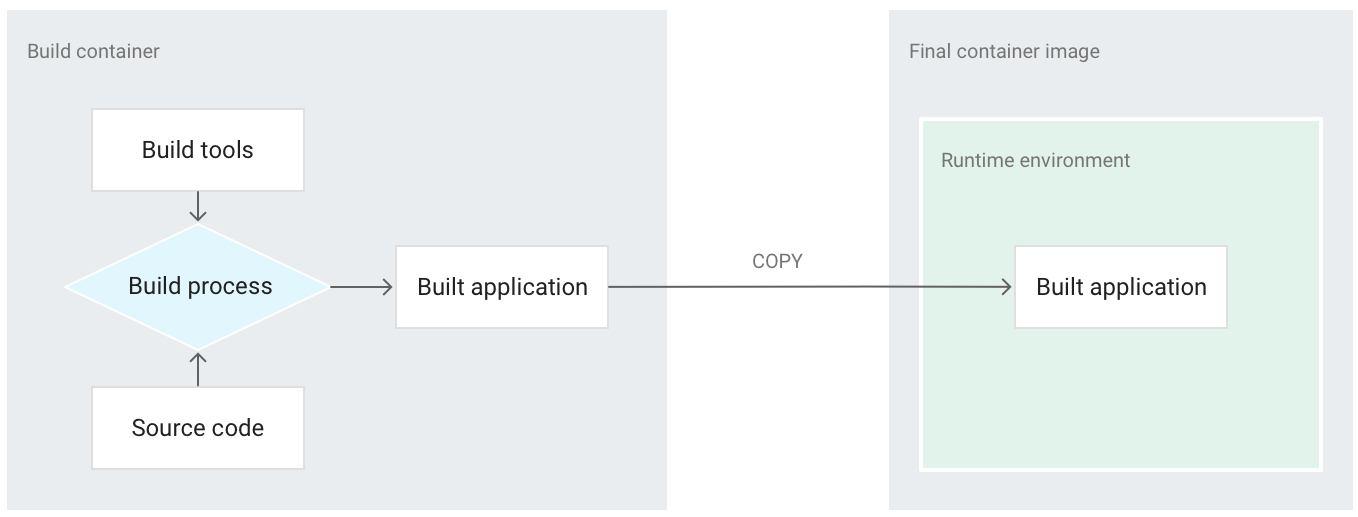
- And on that topic, this best practices for building containers post was a hit, too, giving you tips that will set you up to run your environment more smoothly. The tips in this blog post cover graceful application shutdowns, how to simplify containers and how to choose and tag the container images you’ll use.
It’s been a busy month at GCP, and we’re glad to share lots of new tools with you. Till next time, build away!