I use my Google Home all the time to check the weather before leaving home, set up alarms, listen to music, but I never considered writing an app for it. What does it take to write an app for the Google Home assistant? And can we make it smarter by leveraging Google Cloud? Those were the questions that my colleague Chris Bacon, and I were thinking about when we decided to build a demo for a conference talk.
My initial instinct was that building an app for Google Home would be quite complicated. After all, we’re talking about real humans talking to a device that triggers some service running in the cloud. There are many details to figure out and many things that could potentially go wrong.
Turns out, it is much easier than I thought and a lot of fun as well. In this post, I want to give you a glimpse of what we built. If you want to setup and run the demo yourself, instructions and code are hosted here on GitHub.
Overview
Our main goal with the app was to showcase Google Cloud .NET libraries in a fun and engaging way while highlighting Google’s unique strengths. After some brainstorming, we decided to build a voice-driven app using Dialogflow where we asked some random questions and let Google Home answer by harnessing the power of the cloud.In our app, you can ask Google Home to search for images of a city. Once it finds the images, they are displayed on a web frontend. You can select an image and ask more questions such as “Can you describe the image?” or “Does the image contain landmarks?” You can also ask questions about global temperatures such as “What was the hottest temperature in France in 2015?” or about Hacker News, for example “What was the top Hacker News story on May 1, 2018?” A picture is worth a thousand words. Here’s how the app ended up looking at the high level.
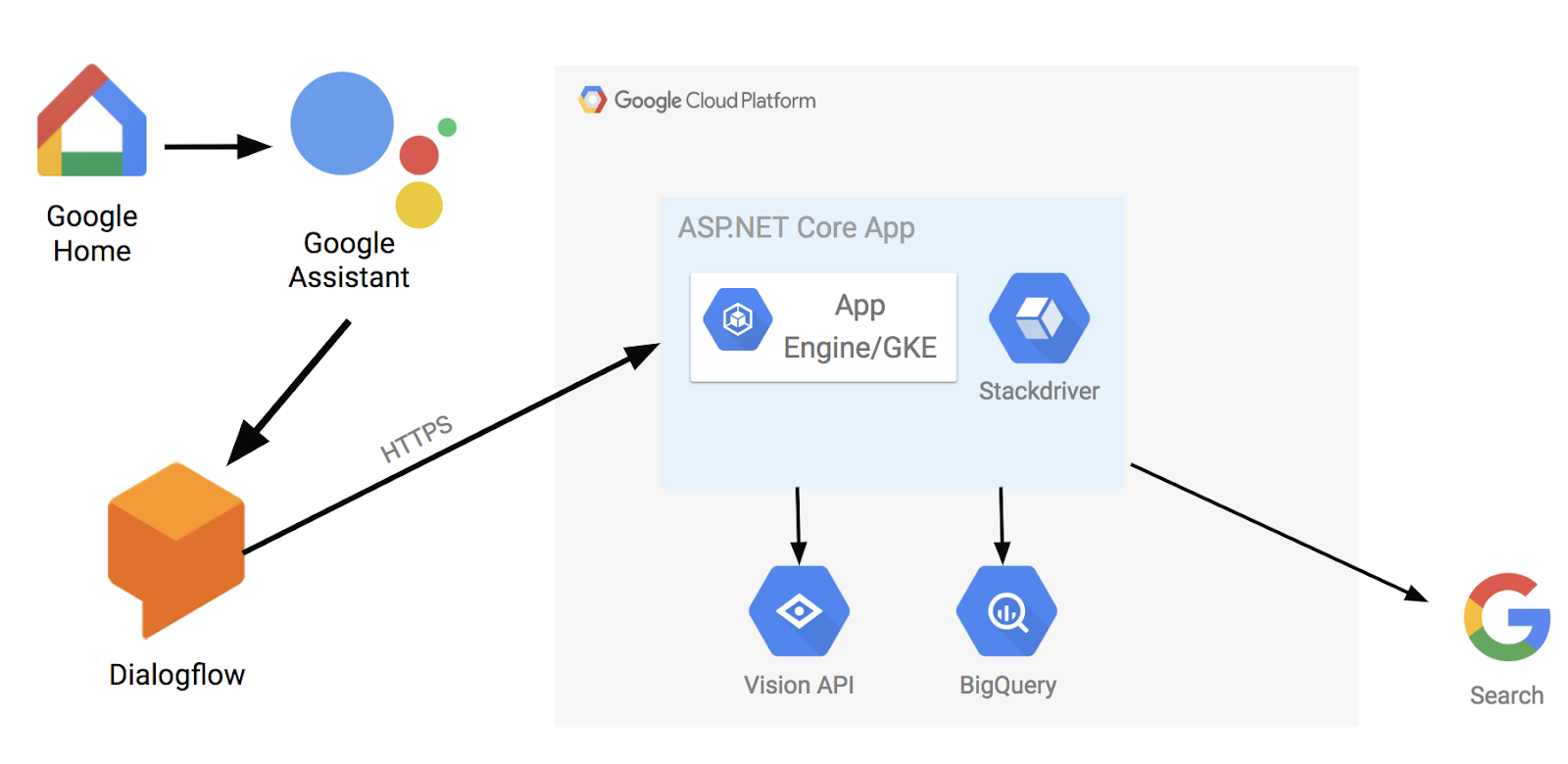
The voice command is first captured by Google Home device and passed to Google Assistant. We use Dialogflow to handle inputs to Google Assistant. Some inputs are handled directly in Dialogflow and some are passed to a pre-defined external webhook (in this case an HTTPS endpoint running in Google Cloud).
I should also mention that the app works anywhere Google Assistant is supported as long as you’re logged in the same Google account with which you created your Dialogflow app. If you don’t have a Google Home, you can simply use your Google Assistant-enabled phone to interact with the app.
Let’s take a look at the implementation in more detail.
Dialogflow
Dialogflow is a developer platform for building natural and rich conversational experiences. When we started thinking about this implementation, we quickly realized that Dialogflow would be a good starting point for the voice-driven part of the app. There are editions of Dialogflow (standard and enterprise) with different limits and SLAs. For our demo, the standard edition was more than enough.You start by creating an agent for your app in Dialogflow console. Within the agent, you create intents. An intent represents a mapping between what a user says and what action should be taken by your app. You don’t have to list all the phrases that can trigger a certain intent. Instead, you provide some training phrases and Dialogflow uses machine learning to learn what to expect. It can also pick up entities from those phrases such as a city name or a date. If the app requires an entity, Dialogflow makes sure that the user provides them. All these small features greatly simplify the work of creating a conversational app.
Some intents can be handled directly in Dialogflow; simply provide the text response for Dialogflow to say. In our app, you can say “Say hi to everyone,” which Dialogflow handles directly with a simple response.

You can also enable an external endpoint to handle intents via a webhook. When an intent is triggered, Dialogflow passes the request to the defined endpoint. The only requirement is that the endpoint supports HTTPS. This is where the power of cloud comes in. In our app, we hosted an endpoint on Google Cloud to handle more complicated questions about images or global temperatures.
ASP.NET Core on App Engine (Flex)
For the endpoint, we decided to host a containerized ASP.NET Core web app on Google Cloud Platform (GCP). Since it’s a container running on Linux (yes, .NET runs on Linux!), we could have hosted on Google Kubernetes Engine or App Engine. We decided to go with App Engine, as it provides an HTTPS endpoint by default with minimal hassle. It also gives us versioning, so we can host multiple versions of our endpoint to do A/B testing or easy rollbacks.The web app serves two purposes. First, it’s the visual frontend to show images or queries (handled by HomeController). Second, it handles webhook calls from Dialogflow for more complicated queries about images or global temperatures (handled by ConversationController).
ConversationController delegates to DialogflowApp to handle the request. DialogflowApp picks up the session id of the request and either creates a new Conversation or finds the existing one. Then, Conversation picks up the intent name and matches that to a subclass of BaseHandler using IntentAttribute at the beginning of handler classes.
Searching for image
When the user says “Search for images of Paris”, that triggers a webhook-enabled “vision.search” intent in Dialogflow. This intent picks up “Paris” as an entity and passes it to the webhook as search term. The call is then routed to VisionSearchHandler running on App Engine. This class uses Google Custom Search APIs to search for images using the search term. In the end, you see a list of images in the web frontend of the app.
Vision API
Once you have a list of images, you can say “Select first picture” to select one. Now it gets interesting. For example, saying something like “Describe the image” triggers VisionDescribeHandler, which makes a call to Vision API using our Vision API .NET library, and gets labels back. We pass these labels back to Dialogflow, which in turn passes them to Google Home to say out loud. You can also say “Does the image contain landmarks?” which uses Vision API’s landmark detection feature (handled by VisionLandmarksHandler). Or you can say “Is the image safe?” to make sure the image does not contain any unsafe images (handled by VisionSafeHandler).BigQuery
BigQuery is Google's serverless data warehousing solution. It has many public datasets available for anyone to search and analyze. We decided to use two of those: Hacker News Data and NOAA Global Weather Data.For example, if you were to say “What was the top hacker news on May 1, 2018?” It would be picked up by the “bigquery.hackernews” intent and eventually routed to BigQueryHackerNewsHandler with the date entity. This class uses BigQuery .NET library to run a query against the Hacker News Data and picks up the top 10 Hacker News articles on that day.
SImilarly, if you say “What was the hottest temperature in France in 2015?” this triggers BigQueryNoaaextremeHandler to run a query against the global weather data and display the top 10 temperatures and locations for that country in that year in the web frontend.

All this is done by scanning gigabytes of data in a few seconds and made possible by BigQuery’s massively parallel infrastructure.
Logging and monitoring
This was all fun but we wanted to make sure that we could maintain our app going forward. Stackdriver is Google Cloud’s logging, monitoring, tracing and debugging tool. Enabling Stackdriver entailed a single API call (UseGoogleDiagnostics in Program) and making a slight modification to a Dockerfile. All of a sudden, we got application logs, tracing for all HTTP calls, monitoring and last but not least, the ability to do live production debugging.With Stackdriver Debugger, we can point to our code on GitHub and then take snapshots from anywhere in the code. Currently supported languages are Java, Python, Node.js, Go and C# (alpha). A snapshot can be captured on live production code without stopping or delaying the app. The snapshot can also be conditional, and contains local variables and stack traces, which are invaluable for production debugging.

Conclusion
In software development, something that should be easy usually ends up being much more complicated when you get into details. In this case, it was quite the opposite. Dialogflow made the voice recognition and routing of requests in our Google Home app very simple and straightforward. We deployed a containerized ASP.NET Core app on App Engine with a single command, and our Google Cloud .NET libraries for Vision API and BigQuery were straightforward and consistent to use.In the end, I had a lot of fun writing this demo with Chris! If you want to try this out yourself, the code and instructions are on GitHub.