At the end of last year we released code that allows a user to classify images with TensorFlow models. This code demonstrated how to build an image classification system by employing a deep learning model that we had previously trained. This model was known to classify an image across 1000 categories supplied by the ImageNet academic competition with an error rate that approached human performance. After all, what self-respecting computer vision system would fail to recognize a cute puppy?
 |
| Image via Wikipedia |
{kind=link}
 |
| Images via Wikipedia |
{kind=link}
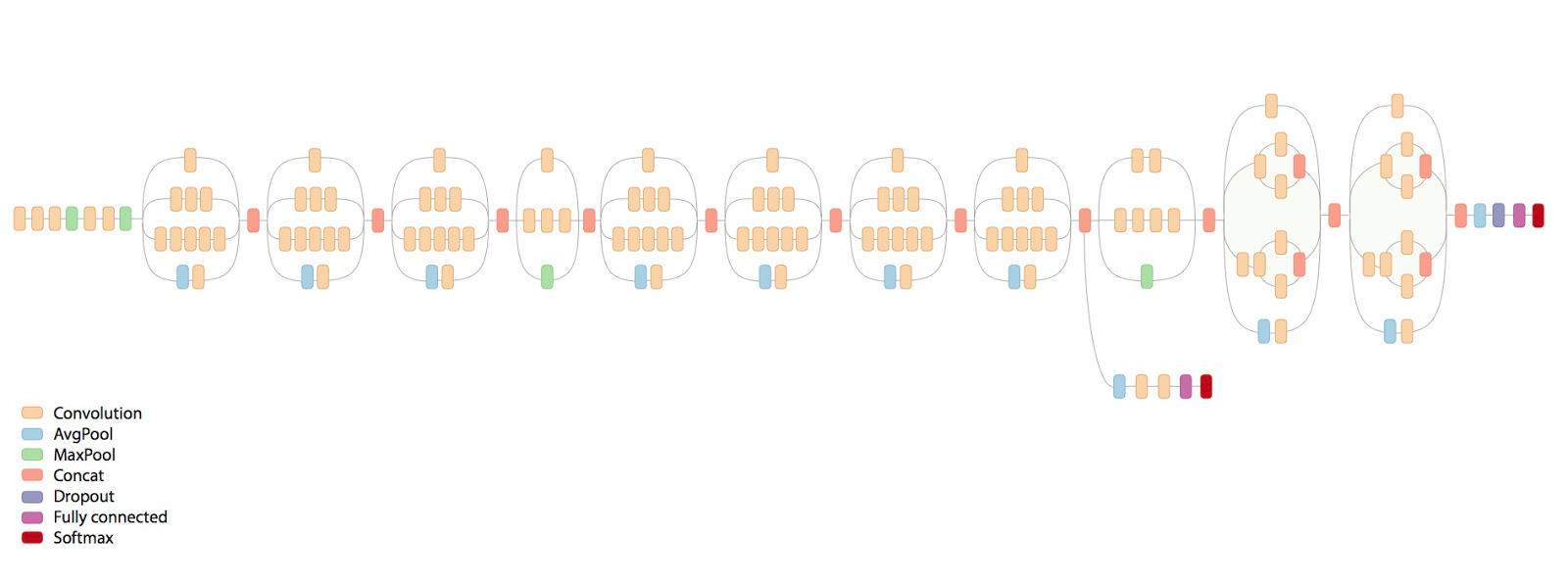 |
| Schematic diagram of Inception-v3 |
After the release of this model, many people in the TensorFlow community voiced their preference on having an Inception-v3 model that they can train themselves, rather than using our pre-trained model. We could not agree more, since a system for training an Inception-v3 model provides many opportunities, including:
- Exploration of different variants of this model architecture in order to improve the image classification system.
- Comparison of optimization algorithms and hardware setups for training this model faster or to a higher degree of predictive performance.
- Retraining/fine-tuning the Inception-v3 model on a distinct image classification task or as a component of a larger network tasked with object detection or multi-modal learning.
Today we are happy to announce that we are releasing libraries and code for training Inception-v3 on one or multiple GPU’s. Some features of this code include:
- Training an Inception-v3 model with synchronous updates across multiple GPUs.
- Employing batch normalization to speed up training of the model.
- Leveraging many distortions of the image to augment model training.
- Releasing a new (still experimental) high-level language for specifying complex model architectures, which we call TensorFlow-Slim.
- Demonstrating how to perform transfer learning by taking a pre-trained Inception-v3 model and fine-tuning it for another task.
Want to get started? See the accompanying instructions on how to train, evaluate or fine-tune a network.
Releasing this code has been a huge team effort. These efforts have taken several months with contributions from many individuals spanning research at Google. We wish to especially acknowledge the following people who contributed to this project:
- Model Architecture – Christian Szegedy, Sergey Ioffe, Vincent Vanhoucke, Jon Shlens and Zbigniew Wojna
- Systems Infrastructure – Sherry Moore, Martin Wicke, David Andersen, Matthieu Devin, Manjunath Kudlur and Nishant Patil
- TensorFlow-Slim – Sergio Guadarrama and Nathan Silberman
- Model Visualization – Fernanda Viégas, Martin Wattenberg and James Wexler
