This is part two of a series on test flakiness. The first article discussed the four components under which tests are run and the possible reasons for test flakiness. This article will discuss the triage tips and remedies for flakiness for each of these possible reasons.
Components
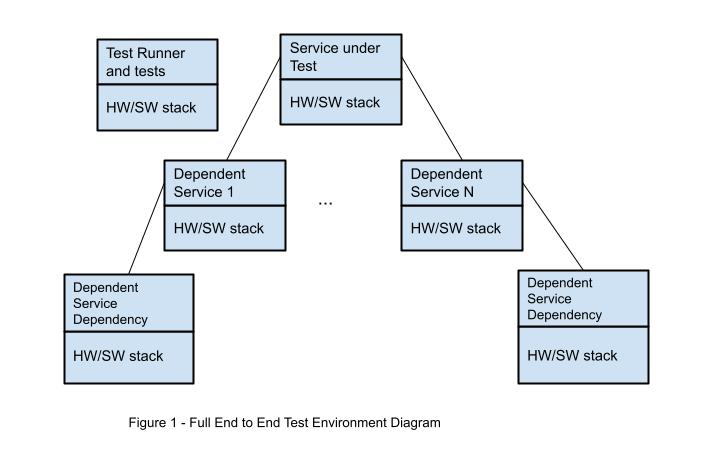
To review, the four components where flakiness can occur include:
- The tests themselves
- The test-running framework
- The application or system under test (SUT) and the services and libraries that the SUT and testing framework depend upon
- The OS and hardware and network that the SUT and testing framework depend upon
This was captured and summarized in the following diagram.
The reasons, triage tips, and remedies for flakiness are discussed below, by component.
The tests themselves
The tests themselves can introduce flakiness. This can include test data, test workflows, initial setup of test prerequisites, and initial state of other dependencies.
Table 1 - Reasons, triage tips, and remedies for flakiness in the tests themselves
The test-running framework
An unreliable test-running framework can introduce flakiness.
Table 2 - Reasons, triage tips, and remedies for flakiness in the test running framework
The application or SUT and the services and libraries that the SUT and testing framework depend upon
Of course, the application itself (or the SUT) could be the source of flakiness.
An application can also have numerous dependencies on other services, and each of those services can have their own dependencies. In this chain, each of the services can introduce flakiness.
Table 3 - Reasons, triage tips, and remedies for flakiness in the application or SUT
The OS and hardware that the SUT and testing framework depend upon
Finally, the underlying hardware and operating system can be sources of test flakiness.
Table 4 - Reasons, triage tips, and remedies for flakiness in the OS and hardware of the SUT
Conclusion
As can be seen from the wide variety of failures, having low flakiness in automated testing can be quite a challenge. This article has outlined both the components under which tests are run and the types of flakiness that can occur, and thus can serve as a cheat sheet when triaging and fixing flaky tests.
References