Dealing with test flakiness is a critical skill in testing because automated tests that do not provide a consistent signal will slow down the entire development process. If you haven’t encountered flaky tests, this article is a must-read as it first tries to systematically outline the causes for flaky tests. If you have encountered flaky tests, see how many fall into the areas listed.
A follow-up article will talk about dealing with each of the causes.
Over the years I’ve seen a lot of reasons for flaky tests, but rather than review them one by one, let’s group the sources of flakiness by the components under which tests are run:
- The tests themselves
- The test-running framework
- The application or system under Test (SUT) and the services and libraries that the SUT and testing framework depend upon
- The OS and hardware that the SUT and testing framework depend upon
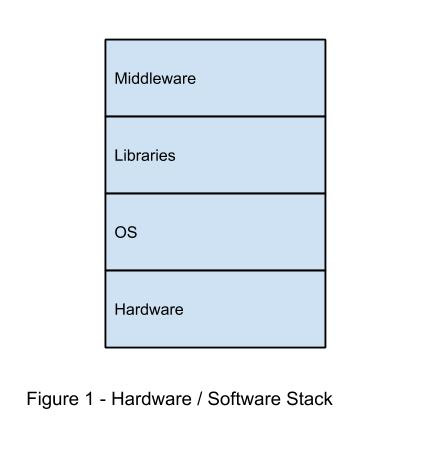
This is illustrated below. Figure 1 first shows the hardware/software stack that supports an application or system under test. At the lowest level is the hardware. The next level up is the operating system followed by the libraries that provide an interface to the system. At the highest level, is the middleware, the layer that provides application specific interfaces.
In a distributed system, however, each of the services of the application and the services it depends upon can reside on a different hardware / software stack as can the test running service. This is illustrated in Figure 2 as the full test running environment.

As discussed above, each of these components is a potential area for flakiness.
The tests themselves
The tests themselves can introduce flakiness. Typical causes include:
- Improper initialization or cleanup.
- Invalid assumptions about the state of test data.
- Invalid assumptions about the state of the system. An example can be the system time.
- Dependencies on the timing of the application.
- Dependencies on the order in which the tests are run. (Similar to the first case above.)
The test-running framework
An unreliable test-running framework can introduce flakiness. Typical causes include:
- Failure to allocate enough resources for the system under test thus causing it to fail coming up.
- Improper scheduling of the tests so they “collide” and cause each other to fail.
- Insufficient system resources to satisfy the test requirements.
The application or system under test and the services and libraries that the SUT and testing framework depend upon
Of course, the application itself (or the system under test) could be the source of flakiness. An application can also have numerous dependencies on other services, and each of those services can have their own dependencies. In this chain, each of the services can introduce flakiness. Typical causes include:
- Race conditions.
- Uninitialized variables.
- Being slow to respond or being unresponsive to the stimuli from the tests.
- Memory leaks.
- Oversubscription of resources.
- Changes to the application (or dependent services) happening at a different pace than those to the corresponding tests.
Testing environments are called hermetic when they contain everything that is needed to run the tests (i.e. no external dependencies like servers running in production). Hermetic environments, in general, are less likely to be flaky.
The OS and hardware that the SUT and testing framework depend upon
Finally, the underlying hardware and operating system can be the source of test flakiness. Typical causes include:
- Networking failures or instability.
- Disk errors.
- Resources being consumed by other tasks/services not related to the tests being run.
As can be seen from the wide variety of failures, having low flakiness in automated testing can be quite a challenge. This article has both outlined the areas and the types of flakiness that can occur in those areas, so it can serve as a cheat sheet when triaging flaky tests.
In the follow-up of this blog we’ll look at ways of addressing these issues.
References

