Visual Question Answering (VQA) is a useful machine learning (ML) task that requires a model to answer a visual question about an image. What makes it challenging is its multi-task and open-ended nature; it involves solving multiple technical research questions in computer vision and natural language understanding simultaneously. Yet, progress on this task would enable a wide range of applications, from assisting the blind and the visually-impaired or communicating with robots to enhancing the user’s visual experience with external knowledge.
Effective and robust VQA systems cannot exist without high-quality, semantically and stylistically diverse large-scale training data of image-question-answer triplets. But, creating such data is time consuming and onerous. Perhaps unsurprisingly, the VQA community has focused more on sophisticated model development rather than scalable data creation.
In “All You May Need for VQA are Image Captions,” published at NAACL 2022, we explore VQA data generation by proposing “Visual Question Generation with Question Answering Validation” (VQ2A), a pipeline that works by rewriting a declarative caption into multiple interrogative question-answer pairs. More specifically, we leverage two existing assets — (i) large-scale image-text data and (ii) large-capacity neural text-to-text models — to achieve automatic VQA data generation. As the field has progressed, the research community has been making these assets larger and stronger in isolation (for general purposes such as learning text-only or image-text representations); together, they can achieve more and we adapt them for VQA data creation purposes. We find our approach can generate question-answer pairs with high precision and that this data can successfully be used for training VQA models to improve performance.
 |
 |
 |
| The VQ2A technique enables VQA data generation at scale from image captions by rewriting each caption into multiple question-answer pairs. |
VQ2A Overview
The first step of the VQ2A approach is to apply heuristics based on named entity recognition, part-of-speech tagging and manually defined rules to generate answer candidates from the image caption. These generated candidates are small pieces of information that may be relevant subjects about which to ask questions. We also add to this list two default answers, “yes” and “no”, which allow us to generate Boolean questions.
Then, we use a T5 model that was fine-tuned to generate questions for the candidate, resulting in [question, candidate answer] pairs. We then filter for the highest quality pairs using another T5 model (fine-tuned to answer questions) by asking it to answer the question based on the caption. was . That is, we compare the candidate answer to the output of this model and if the two answers are similar enough, we define this question as high quality and keep it. Otherwise, we filter it out.
The idea of using both question answering and question generation models to check each other for their round-trip consistency has been previously explored in other contexts. For instance, Q2 uses this idea to evaluate factual consistency in knowledge-grounded dialogues. In the end, the VQ2A approach, as illustrated below, can generate a large number of [image, question, answer] triplets that are high-quality enough to be used as VQA training data.
 |
| VQ2A consists of three main steps: (i) candidate answer extraction, (ii) question generation, (iii) question answering and answer validation. |
Results
Two examples of our generated VQA data are shown below, one based on human-written COCO Captions (COCO) and the other on automatically-collected Conceptual Captions (CC3M), which we call VQ2A-COCO and VQ2A-CC3M, respectively. We highlight the variety of question types and styles, which are critical for VQA. Overall, the cleaner the captions (i.e., the more closely related they are to their paired image), the more accurate the generated triplets. Based on 800 samples each, 87.3% of VQ2A-COCO and 66.0% VQ2A-CC3M are found by human raters to be valid, suggesting that our approach can generate question-answer pairs with high precision.
 |
 |
| Generated question-answer pairs based on COCO Captions (top) and Conceptual Captions (bottom). Grey highlighting denotes questions that do not appear in VQAv2, while green highlighting denotes those that do, indicating that our approach is capable of generating novel questions that an existing VQA dataset does not have. |
Finally, we evaluate our generated data by using it to train VQA models (highlights shown below). We observe that our automatically-generated VQA data is competitive with manually-annotated target VQA data. First, our VQA models achieve high performance on target benchmarks “out-of-the-box”, when trained only on our generated data (light blue and light red vs. yellow). Once fine-tuned on target data, our VQA models outperform target-only training slightly on large-scale benchmarks like VQAv2 and GQA, but significantly on the small, knowledge-seeking OK-VQA (dark blue/red vs. light blue/red).
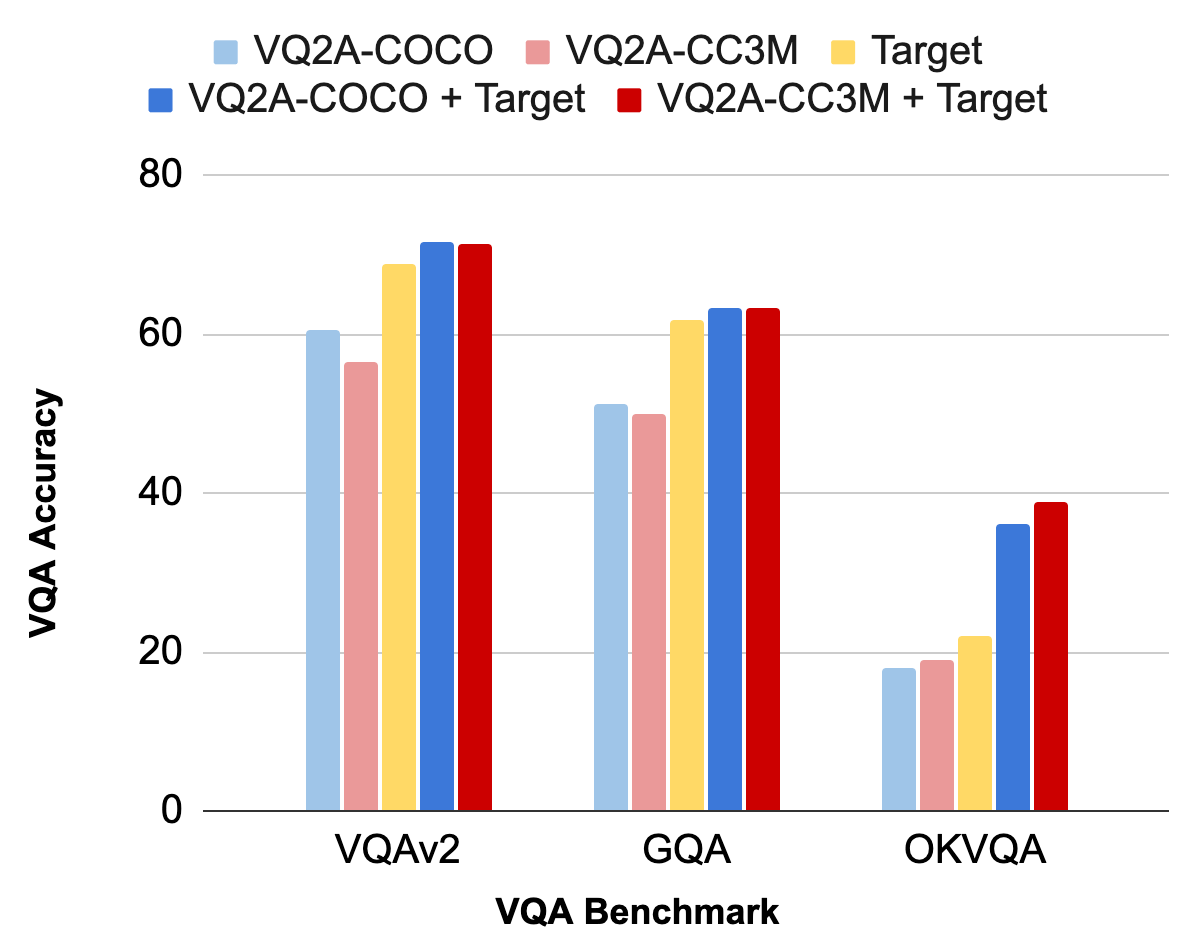 |
| VQA accuracy on popular benchmark datasets. |
Conclusion
All we may need for VQA are image captions! This work demonstrates that it is possible to automatically generate high-quality VQA data at scale, serving as an essential building block for VQA and vision-and-language models in general (e.g., ALIGN, CoCa). We hope that our work inspires other work on data-centric VQA.
Acknowledgments
We thank Roee Aharoni, Idan Szpektor, and Radu Soricut for their feedback on this blogpost. We also thank our co-authors: Xi Chen, Nan Ding, Idan Szpektor, and Radu Soricut. We acknowledge contributions from Or Honovich, Hagai Taitelbaum, Roee Aharoni, Sebastian Goodman, Piyush Sharma, Nassim Oufattole, Gal Elidan, Sasha Goldshtein, and Avinatan Hassidim. Finally, we thank the authors of Q2, whose pipeline strongly influences this work.


.png)


