For four years now, Google has been using QUIC, a UDP-based encrypted transport protocol optimized for HTTPS, to deliver traffic for our products – from Google Web Search, to YouTube, to this very blog. If you’re reading this in Chrome, you’re probably using QUIC right now. QUIC makes the web faster, particularly for slow connections, and now your cloud services can enjoy that speed: today, we’re happy to be the first major public cloud to offer QUIC support for our HTTPS load balancers.
QUIC’s key features include establishing connections faster, stream-based multiplexing, improved loss recovery, and no head-of-line blocking. QUIC is designed with mobility in mind, and supports migrating connections from WiFi to Cellular and back.
Benefits of QUIC
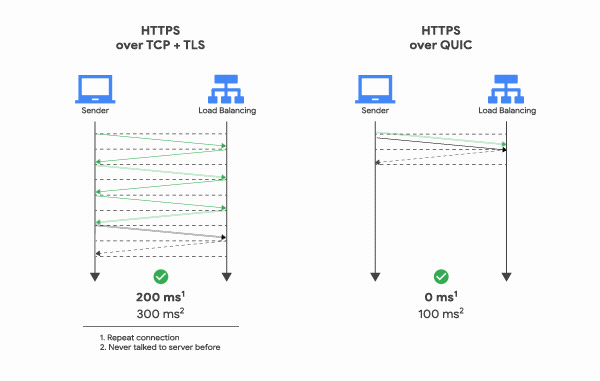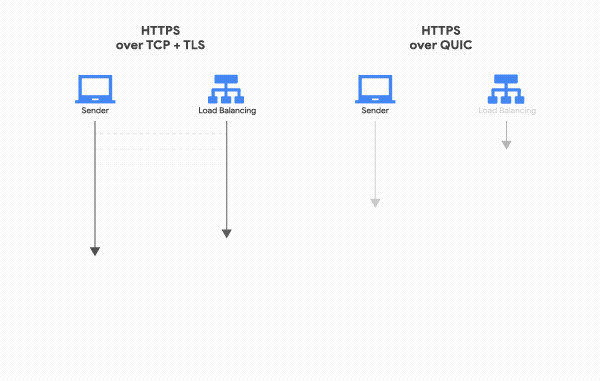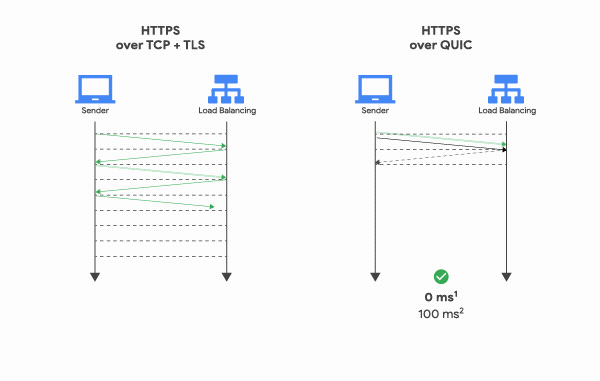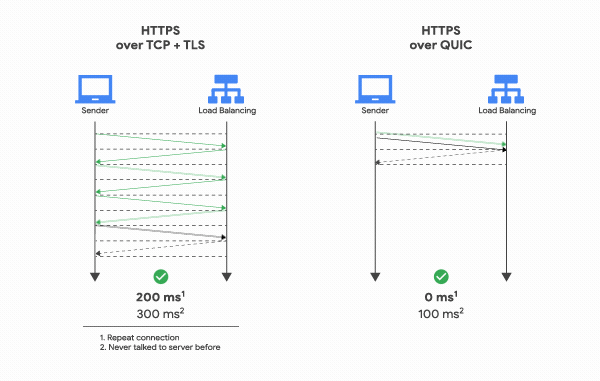
If your service is sensitive to latency, QUIC will make it faster because of the way it establishes connections. When a web client uses TCP and TLS, it requires two to three round trips with a server to establish a secure connection before the browser can send a request. With QUIC, if a client has talked to a given server before, it can start sending data without any round trips, so your web pages will load faster. How much faster? On a well-optimized site like Google Search, connections are often pre-established, so QUIC’s faster connections can only speed up some requests—but QUIC still improves mean page load time by 8% globally, and up to 13% in regions where latency is higher.
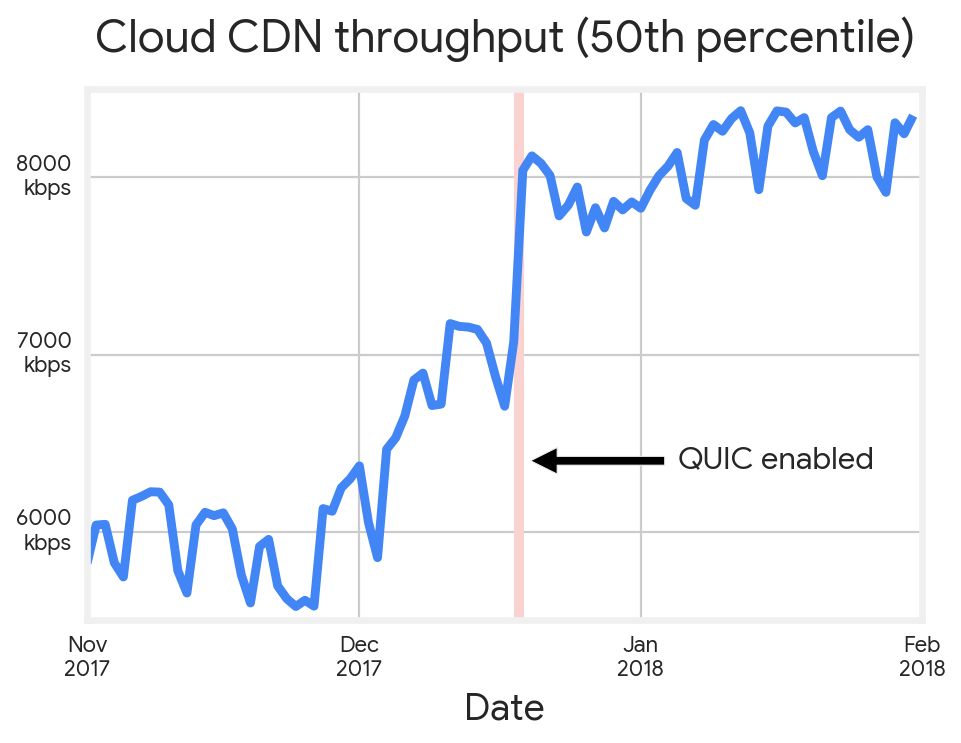
Cedexis benchmarked our Cloud CDN performance using a Google Cloud project. Here’s what happened when we enabled QUIC.
Encryption is built into QUIC, using AEAD algorithms such as AES-GCM and ChaCha20 for both privacy and integrity. QUIC authenticates the parts of its headers that it doesn’t encrypt, so attackers can’t modify any part of a message. Like HTTP/2, QUIC multiplexes multiple streams into one connection, so that a connection can serve several HTTP requests simultaneously. But HTTP/2 uses TCP as its transport, so all of its streams can be blocked when a single TCP packet is lost—a problem called head-of-line blocking. QUIC is different: Loss of a UDP packet within a QUIC connection only affects the streams contained within that packet. In other words, QUIC won’t let a problem with one request slow the others down, even on an unreliable connection.
Enabling QUIC
You can enable QUIC in your load balancer with a single setting in the GCP Console. Just edit the frontend configuration for your load balancer and enable QUIC negotiation for the IP and port you want to use, and you’re done.
You can also enable QUIC using gcloud:
gcloud compute target-https-proxies update proxy-name
--quic_override=ENABLEThe Future of QUIC
We’re working to help QUIC become a standard for web communication, just as we did with HTTP/2. The IETF formed a QUIC working group in November 2016, which has seen intense engagement from IETF participants, and is scheduled to complete v1 drafts this November. QUIC v1 will support HTTP over QUIC, use TLS 1.3 as the cryptographic handshake, and support migration of client connections. At the working group’s most recent interop event, participants presented over ten independent implementations.QUIC is designed to evolve over time. A client and server can negotiate which version of QUIC to use, and as the IETF QUIC specifications become more stable and members reach clear consensus on key decisions, we’ve used that version negotiation to keep pace with the current IETF drafts. Future planned versions will also include features such as partial reliability, multipath, and support for non-HTTP applications like WebRTC.
QUIC works across changing network connections. QUIC can migrate client connections between cellular and Wifi networks, so requests don’t time out and fail when the current network degrades. This migration reduces the number of failed requests and decreases tail latency, and our developers are working on making it even better. QUIC client connection migration will soon be available in Cronet.
Try it out today
Read more about QUIC in the HTTPS load balancing documentation and enable it for your project(s) by editing your HTTP(S) load balancer settings. We look forward to your feedback!









 You can even use exclusion filters to collect a percentage of logs, such as 1% of successful HTTP responses. Plus, exclusion filters are easy to update, so if you’re troubleshooting your system, you can always temporarily increase the logs you’re ingesting.
You can even use exclusion filters to collect a percentage of logs, such as 1% of successful HTTP responses. Plus, exclusion filters are easy to update, so if you’re troubleshooting your system, you can always temporarily increase the logs you’re ingesting.
