The problem has been known for several years, but as shown by most recent research from Google performed with the open source platform Antmicro developed that we’ll describe in this note, it has yet to be completely solved. The tendency in DRAM manufacturing is to make the chips denser to pack more memory in the same size which inevitably results in increased interdependency between memory cells, making Rowhammer an ongoing problem.
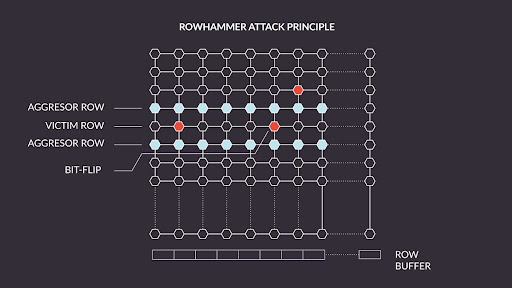
Solutions like TRR (Target Row Refresh) introduced in newer memory chips mitigate the issue, although only in part—and attack methods like Half-Double or TRRespass keep emerging. To go beyond the all-too-often used “security through obscurity” approach, Antmicro has been helping build open source platforms which give security researchers full control over the entire technology stack, and enables them to find new solutions to emerging threats.
The Rowhammer Tester platform
The Rowhammer Tester platform was developed for and with Google, who just like Antmicro believe that open source, well documented technical infrastructure is critical in speeding up research and increasing collaboration with the industry. In this case, we wanted to enable the memory security researchers and manufacturers to have access to a flexible platform for experimenting with new types of attacks and finding better Rowhammer mitigation techniques.Current Rowhammer test methods involve using the chip-specific MBIST (Memory Built-in Self-Test) or costly ATE (Automated Test Equipment), which means that the existing approaches are either costly, inflexible, or both. MBIST are specialized IP cores that test memory chips for errors. Although effective, they lack flexibility of changing testing algorithms hardcoded into the IP core. ATEs devices are usually used at foundries to run various tests on wafers. Access to these devices is limited and expensive; chip vendors have to rely on DFT (Design for Test) software to produce compressed test patterns, which require less access time to ATE while ensuring high test coverage.
The main goal of the project was to address those limitations, providing an FPGA-based Rowhammer testing platform that enables full control over the commands sent to the DRAM chip. This is important because DRAM memory requires specialized hardware controllers and any software-based testing approaches have to communicate with the DRAM indirectly via the controller, which pulls the researchers away from the main research subject when studying the DRAM chip behaviour itself.
Platform architecture
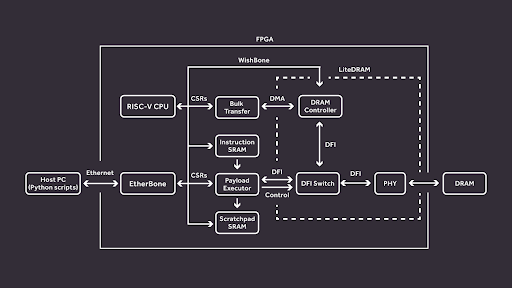
The Rowhammer Tester consists of two parts: the FPGA gateware that is loaded to the hardware platform and a set of Python scripts used to communicate with the FPGA system from the user’s PC. Internally, all the important modules of the FPGA system are connected to a shared WishBone bus. We use an EtherBone bridge to be able to interface with the FPGA WishBone bus from the host PC. EtherBone is a protocol that allows to perform regular WishBone transactions over Ethernet. This way we can perform all of the communication between the user PC and the FPGA efficiently through an Ethernet cable.
The FPGA gateware has four main parts: a Bulk transfer module, a Payload Executor, the LiteDRAM controller, and a VexRiscv CPU. The Bulk transfer module provides an efficient way of filling and testing the whole memory contents. It supports user-configurable access and data patterns, using high-performance DMA to make use of full bandwidth offered by the LiteDRAM controller. When using the Bulk transfer module, LiteDRAM handles all the required DRAM logic, including row activation, refreshing, etc. and ensuring that all DRAM timings are met.
If more fine-grained control is required, our Rowhammer Tester provides the Payload Executor module. Payload Executor can be thought of as a simple processor that can execute our custom instruction set. Most of the instructions map directly to DRAM commands, with minimal control flow provided by the LOOP instruction. A user can compile a “program” and load it to Rowhammer Tester’s instruction SRAM, which will be then executed. To execute a program, Payload Executor will disconnect the LiteDRAM controller and send the requested command sequences directly to the DRAM chip via the PHY’s DFI interface. After execution the LiteDRAM controller gets reconnected and the contents of the memory can be inspected to search for potential bit-flips.
In our platform, we use LiteDRAM which is an open-source controller that we have been using in multiple different projects. It is part of the wider LiteX ecosystem, which is also a very popular choice for many of our FPGA projects. The controller supports different memory types (SDR, DDR, DDR2, DDR3, DDR4, …), as well as many FPGA platforms (Lattice ECP5, Xilinx Series 6, 7, UltraScale, UltraScale+, …). Since it is an open source FPGA IP core, we have complete control over its internals. That means two things: firstly, we were able to easily integrate it with the rest of our system and contribute back to improve LiteDRAM itself. Secondly, and perhaps even more importantly, groups focused on researching new memory attacking methods can modify the controller in order to expose existing vulnerabilities. The results of such experiments should essentially motivate vendors to work on mitigating the uncovered flaws, rather than rely on the “security by obscurity” based approach.
Our Rowhammer Tester is fully open source. We provide an extensive set of Python scripts for controlling the board, performing rowhammer attacks and harvesting the results. For more complex testing you can use the so-called Playbook, which is a framework that allows to describe complex testing scenarios using JSON files, providing some predefined attack configurations.
Antmicro is actively collaborating with Google and memory makers to help study the Rowhammer vulnerability, contributing to standardization efforts under the JEDEC initiative. The platform has already been used to a lot of success in state-of-the-art Rowhammer research (like the case of finding a new type of Rowhammer attack called Half-Double, as mentioned previously).
New DRAM PHYs
Initially our Rowhammer Tester targeted two easily available and price-optimized boards: Digilent Arty (DDR3, Xilinx Series7 FPGA) and Xilinx ZCU104 (DDR4, Xilinx UltraScale+ FPGA). They were a good starting point, as DDR3 and DDR4 PHYs for these boards were already supported by LiteDRAM. After the initial version of the Rowhammer Tester was ready and tested on these boards, proving the validity of the concept, the next step was to cover more memory types, some of which find their way into many devices that we interact with daily. A natural target was the LPDDR4 DRAM—a relatively new type of memory designed for low-power operation with throughputs up to 3200 MT/s. For this end, we designed our dedicated LPDDR4 Test Board, which has already been covered in a previous blog note.
The design is quite interesting because we decided to put the LPDDR4 memory chips on a module, which is against the usual practice of putting LPDDR4 directly on the PCB, as close as possible to the CPU/FPGA to minimize trace impedance. The reason was trivial—we needed the platform to be able to test many memory types interchangeably without having to desolder and resolder parts, using complicated interposers or other niche techniques—the platform is supposed to be open and approachable to all.
Alongside the hardware platform we had to develop a new LPDDR4 PHY IP as LiteDRAM didn’t have support for LPDDR4 at that time, resolving problems related to the differences between LPDDR4 and previously supported DRAM types, such as new training modes. After a phase of verification and testing on our hardware, the newly implemented PHY has been contributed back to LiteDRAM.
What’s next?
The project does not stop there; we are already working on an LPDDR5 PHY for next-gen low power memory support. This latest low-power memory standard published by JEDEC poses some new and interesting challenges including a new clocking architecture and operation on an even lower voltage. As of today, LPDDR5 chips are hardly available on the market as a bleeding-edge technology, but we are continuing our work to prepare LPDDR5 support for our future hardware platform in simulation using custom and vendor provided simulation models.The fact that our platform has already been successfully used to demonstrate new types of Rowhammer attacks proves that open source test platforms can make a difference, and we are pleased to see a growing collaborative ecosystem around the project in a joint effort to ensure that we find robust and transparent mitigation techniques for all variants of Rowhammer for the foreseeable future.
Ultimately, our work with the Rowhammer Tester platform shows that by using open source, vendor-neutral IP, tools and hardware, we can create better platforms for more effective research and product development. In the future, building on the success of the FPGA version, our work as part of the CHIPS Alliance will most likely lead to demonstrating the LiteDRAM controller in ASIC form, unlocking even more performance based on the same solid platform.
If you are interested in state of the art, high-speed FPGA I/O and extreme customizability that open source FPGA blocks can offer, get in touch with Antmicro at [email protected] to hire development services to develop your next product.
Originally posted on the Antmicro blog.
By guest author Michael Gielda, Antmicro





 this can lead to substantial savings. For a quarter filling wavefunction on 48 qubits (24 orbitals) we would need 290 Gb and a qubit simulation would require 4.5 Petabytes.")