Recommendation engines are the technology behind content discovery networks and the suggestion features of most ecommerce websites. They improve a visitor's experience by offering relevant items at the right time and on the right page. Adding that intelligence makes your application more attractive, enhances the customer experience and increases their satisfaction. Digital Trends studies show that 73% of customers prefer to get a personalized experience during their shopping experience.
There are various components to a recommendation engine, ranging from data ingestion and analytics to machine learning algorithms. In order to provide relevant recommendations, the system must be scalable and able to handle the demands that come with processing Big Data and must provide an easy way to improve the algorithms.
Recommendation engines, particularly the scalable ones that produce great suggestions, are highly compute-intensive workloads. The following features of Google Cloud Platform are well-suited to support this kind of workload:
- Multi-tenant, redundant datacenters
- Custom instance types
- Global network
- Years of experience in software infrastructure innovation, such as MapReduce, BigTable, Dremel, Flume, and Spanner.
Customers building recommendation engines are jumping on board. Antvoice uses Google Cloud Platform to deploy their self-learning, multi-channel, predictive recommendation platform.
This new solution article provides an introduction to implementing product recommendations. It shows you how you can use open source technologies to setup a basic recommendation engine on Cloud Platform. It uses the example of a house-renting website that suggests houses that the user might be interested in based on their previous behavior through a technique known as collaborative filtering.
To provide recommendations, whether in real time while customers browse your site, or through email later on, several things need to happen. At first, while you know little about your users' tastes and preferences, you might base recommendations on item attributes alone. But your system needs to be able to learn from your users, collecting data about their tastes and preferences.
Over time and with enough data, you can use machine learning algorithms to perform useful analysis and deliver meaningful recommendations. Other users’ inputs can also improve the results, effectively periodically retraining the system. This solution deals with a recommendations system that already has enough data to benefit from machine learning algorithms.
A recommendation engine typically processes data through the following four phases:

The following diagram represents the architecture of such a system:
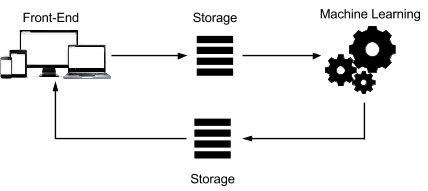
Each component of this architecture can be deployed using various easy-to-implement technologies to get you started:
- Front-End: By deploying a simple application on Google App Engine, a user can see a page with top recommendations. You can take it from there, easily building a strong and scalable web platform that can manage one to several millions of users, with minimum operations.
- Storage: The solution uses Google Cloud SQL, our managed MySQL option. A commonly used database in the ecommerce domain, this database integrates well with MLlib, a machine learning library.
- Machine learning: Using Google Cloud Dataproc or bdutil, two options that simplify deployment and management of Hadoop/Spark clusters, you'll deploy and run MLlib-based scripts.
- Timeliness concerns, such as real-time, near-real-time, and batch data analysis. This information can help you understand your options for how quickly you can present recommendations to the user and what it takes to implement each option. The sample solution focuses mainly on a near-real-time approach.
- Filtering methods, such as content-based, cluster and collaborative filtering. You'll need to decide exactly what information goes into making a recommendation, and these filtering methods are the common ones in use today. The sample solution focuses mainly on collaborative filtering, but a helpful appendix provides more information about the other options.
We hope that this solution will give you the nuts and bolts you need to build an intelligent and ever-improving application that makes the most of the information that your users give you. Happy reading!
If you liked this blog post . . . you can get started today following these steps:
- Sign up for a free trial
- Download and follow the instructions on the Google Cloud Platform Github page
- “Recommend” this solution to your friends.
- Posted by Matthieu Mayran, Cloud Solutions Architect