I was first introduced to neural networks as an undergraduate in 1990. Back then, many people in the AI community were excited about the potential of neural networks, which were impressive, but couldn’t yet accomplish important, real-world tasks. I was excited, too! I did my senior thesis on using parallel computation to train neural networks, thinking we only needed 32X more compute power to get there. I was way off. At that time, we needed 1 million times as much computational power.
A short 21 years later, with exponentially more computational power, it was time to take another crack at neural networks. In 2011, I and a few others at Google started training very large neural networks using millions of randomly selected frames from videos online. The results were remarkable. Without explicit training, the system automatically learned to recognize different objects (especially cats, the Internet is full of cats). This was one transformational discovery in AI among a long string of successes that is still ongoing — at Google and elsewhere.
I share my own history of neural networks to illustrate that, while progress in AI might feel especially fast right now, it’s come from a long arc of progress. In fact, prior to 2012, computers had a really difficult time seeing, hearing, or understanding spoken or written language. Over the past 10 years we’ve made especially rapid progress in AI.
Today, we’re excited about many recent advances in AI that Google is leading — not just on the technical side, but in responsibly deploying it in ways that help people around the world. That means deploying AI in Google Cloud, in our products from Pixel phones to Google Search, and in many fields of science and other human endeavors.
We’re aware of the challenges and risks that AI poses as an emerging technology. We were the first major company to release and operationalize a set of AI Principles, and following them has actually (and some might think counterintuitively) allowed us to focus on making rapid progress on technologies that can be helpful to everyone. Getting AI right needs to be a collective effort — involving not just researchers, but domain experts, developers, community members, businesses, governments and citizens.
I’m happy to make announcements in three transformative areas of AI today: first, using AI to make technology accessible in many more languages. Second, exploring how AI might bolster creativity. And third, in AI for Social Good, including climate adaptation.
1. Supporting 1,000 languages with AI
Language is fundamental to how people communicate and make sense of the world. So it’s no surprise it’s also the most natural way people engage with technology. But more than 7,000 languages are spoken around the world, and only a few are well represented online today. That means traditional approaches to training language models on text from the web fail to capture the diversity of how we communicate globally. This has historically been an obstacle in the pursuit of our mission to make the world’s information universally accessible and useful.
That’s why today we’re announcing the 1,000 Languages Initiative, an ambitious commitment to build an AI model that will support the 1,000 most spoken languages, bringing greater inclusion to billions of people in marginalized communities all around the world. This will be a many years undertaking – some may even call it a moonshot – but we are already making meaningful strides here and see the path clearly. Technology has been changing at a rapid clip – from the way people use it to what it’s capable of. Increasingly, we see people finding and sharing information via new modalities like images, videos, and speech. And our most advanced language models are multimodal – meaning they’re capable of unlocking information across these many different formats. With these seismic shifts come new opportunities.

As part of our this initiative and our focus on multimodality, we’ve developed a Universal Speech Model — or USM — that’s trained on over 400 languages, making it the largest language coverage seen in a speech model to date. As we expand on this work, we’re partnering with communities across the world to source representative speech data. We recently announced voice typing for 9 more African languages on Gboard by working closely with researchers and organizations in Africa to create and publish data. And in South Asia, we are actively working with local governments, NGOs, and academic institutions to eventually collect representative audio samples from across all the regions’ dialects and languages.
2. Empowering creators and artists with AI
AI-powered generative models have the potential to unlock creativity, helping people across cultures express themselves using video, imagery, and design in ways that they previously could not.
Our researchers have been hard at work developing models that lead the field in terms of quality, generating images that human raters prefer over other models. We recently shared important breakthroughs, applying our diffusion model to video sequences and generating long coherent videos for a sequence of text prompts. We can combine these techniques to produce video — for the first time, today we’re sharing AI-generated super-resolution video:
We’ll soon be bringing our text-to-image generation technologies to AI Test Kitchen, which provides a way for people to learn about, experience, and give feedback on emerging AI technology. We look forward to hearing feedback from users on these demos in AI Test Kitchen Season 2. You’ll be able to build themed cities with “City Dreamer” and design friendly monster characters that can move, dance, and jump with “Wobble” — all by using text prompts.
In addition to 2D images, text-to-3D is now a reality with DreamFusion, which produces a three-dimensional model that can be viewed from any angle and can be composited into any 3D environment. Researchers are also making significant progress in the audio generation space with AudioLM, a model that learns to generate realistic speech and piano music by listening to audio only. In the same way a language model might predict the words and sentences that follow a text prompt, AudioLM can predict which sounds should follow after a few seconds of an audio prompt.
We're collaborating with creative communities globally as we develop these tools. For example, we're working with writers using Wordcraft, which is built on our state-of-the-art dialog system LaMDA, to experiment with AI-powered text generation. You can read the first volume of these stories at the Wordcraft Writers Workshop.
3. Addressing climate change and health challenges with AI
AI also has great potential to address the effects of climate change, including helping people adapt to new challenges. One of the worst is wildfires, which affect hundreds of thousands of people today, and are increasing in frequency and scale.
Today, I’m excited to share that we’ve advanced our use of satellite imagery to train AI models to identify and track wildfires in real time, helping predict how they will evolve and spread. We’ve launched this wildfire tracking system in the U.S., Canada, Mexico, and are rolling out in parts of Australia, and since July we’ve covered more than 30 big wildfire events in the U.S. and Canada, helping inform our users and firefighting teams with over 7 million views in Google Search and Maps.
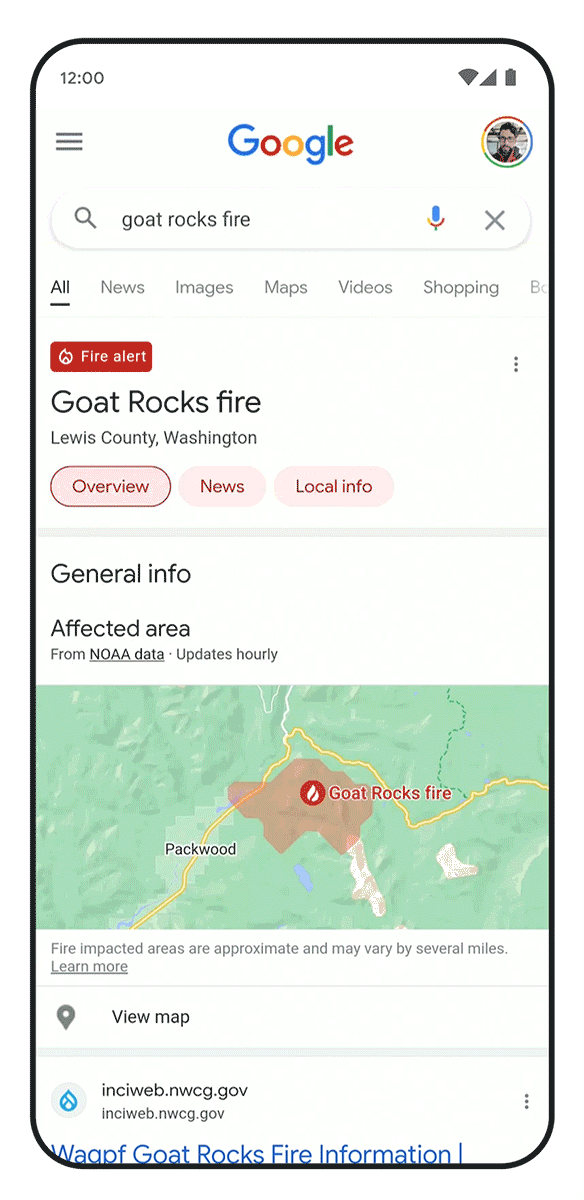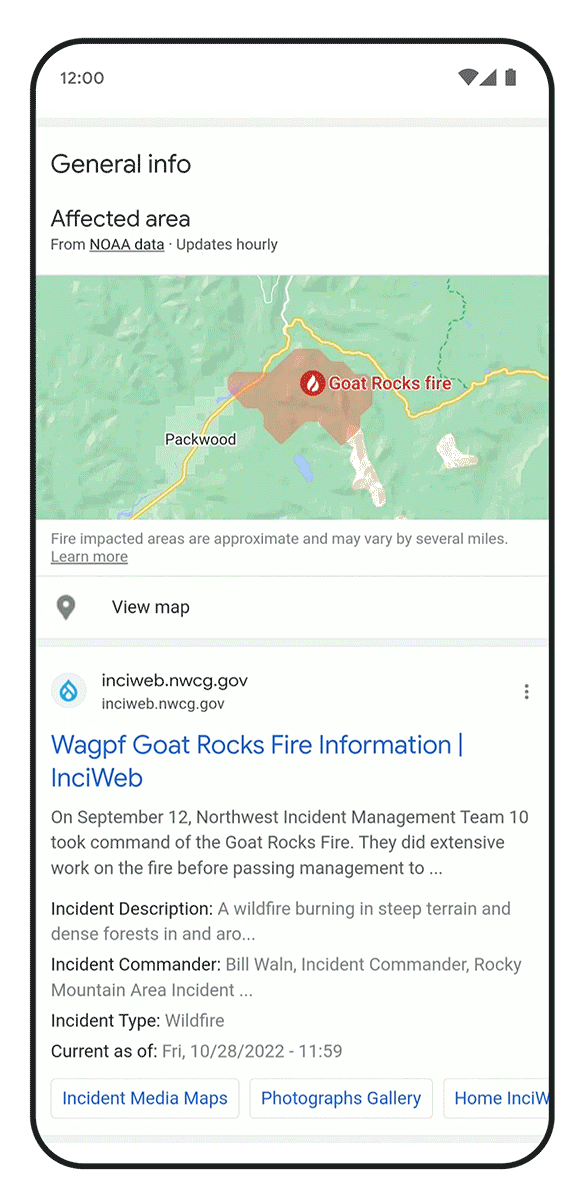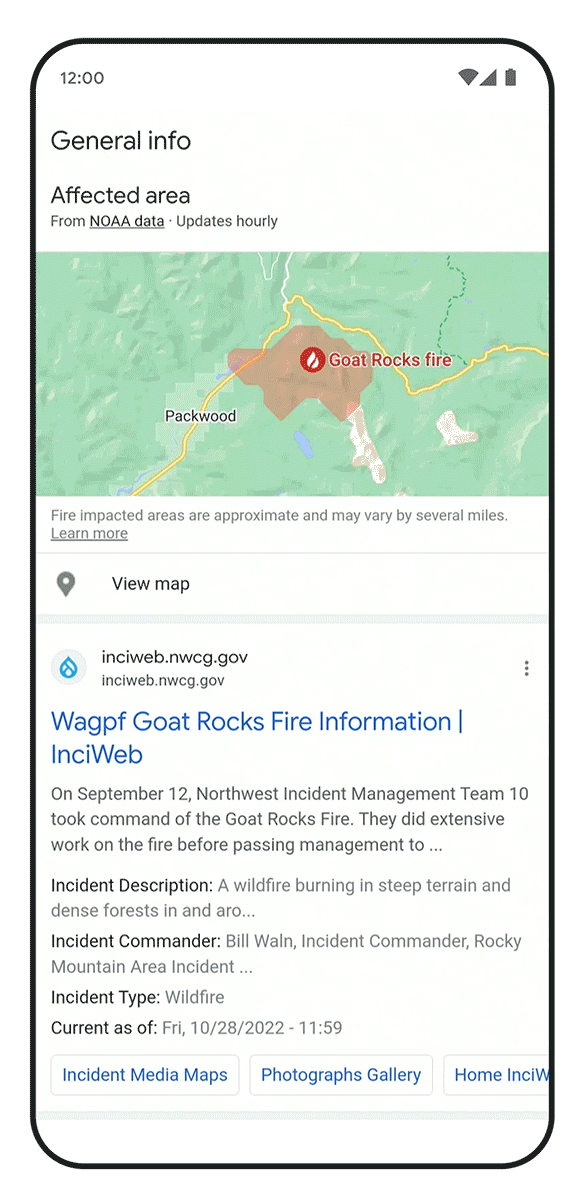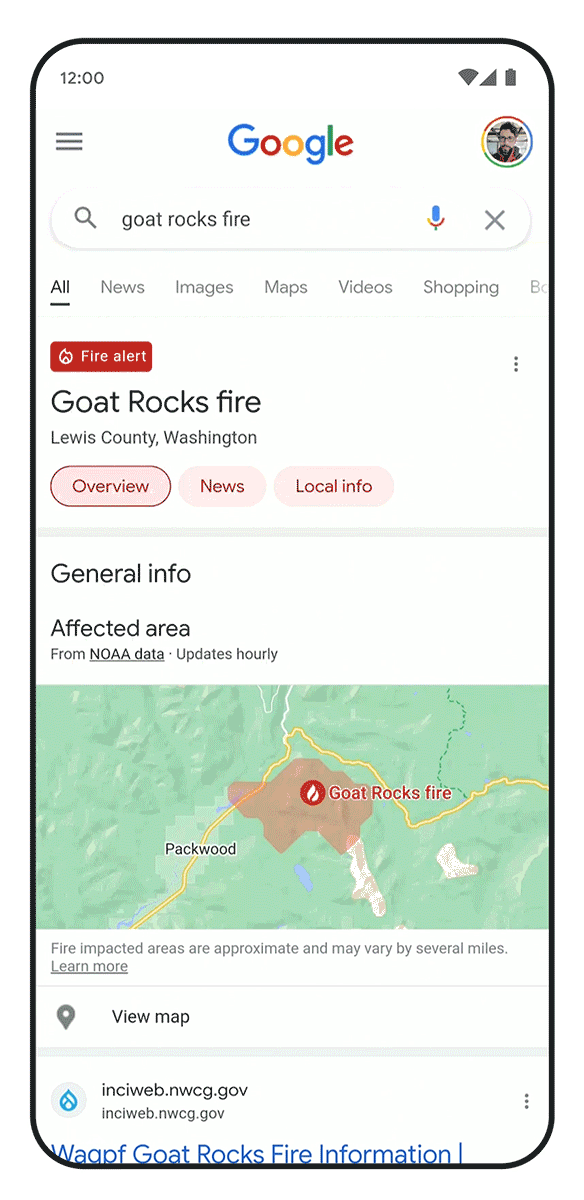
We’re also using AI to forecast floods, another extreme weather pattern exacerbated by climate change. We’ve already helped communities to predict when floods will hit and how deep the waters will get — in 2021, we sent 115 million flood alert notifications to 23 million people over Google Search and Maps, helping save countless lives. Today, we’re sharing that we’re now expanding our coverage to more countries in South America (Brazil and Colombia), Sub-Saharan Africa (Burkina Faso, Cameroon, Chad, Democratic Republic of Congo, Ivory Coast, Ghana, Guinea, Malawi, Nigeria, Sierra Leone, Angola, South Sudan, Namibia, Liberia, and South Africa), and South Asia (Sri Lanka). We’ve used an AI technique called transfer learning to make it work in areas where there’s less data available. We’re also announcing the global launch of Google FloodHub, a new platform that displays when and where floods may occur. We’ll also be bringing this information to Google Search and Maps in the future to help more people to reach safety in flooding situations.
Finally, AI is helping provide ever more access to healthcare in under-resourced regions. For example, we’re researching ways AI can help read and analyze outputs from low-cost ultrasound devices, giving parents the information they need to identify issues earlier in a pregnancy. We also plan to continue to partner with caregivers and public health agencies to expand access to diabetic retinopathy screening through our Automated Retinal Disease Assessment tool (ARDA). Through ARDA, we’ve successfully screened more than 150,000 patients in countries like India, Thailand, Germany, the United States, and the United Kingdom across deployed use and prospective studies — more than half of those in 2022 alone. Further, we’re exploring how AI can help your phone detect respiratory and heart rates. This work is part of Google Health’s broader vision, which includes making healthcare more accessible for anyone with a smartphone.
AI in the years ahead
Our advancements in neural network architectures, machine learning algorithms and new approaches to hardware for machine learning have helped AI solve important, real-world problems for billions of people. Much more is to come. What we’re sharing today is a hopeful vision for the future — AI is letting us reimagine how technology can be helpful. We hope you’ll join us as we explore these new capabilities and use this technology to improve people’s lives around the world.






