
Language models (LMs) are the driving force behind many recent breakthroughs in natural language processing. Models like T5, LaMDA, GPT-3, and PaLM have demonstrated impressive performance on various language tasks. While multiple factors can contribute to improving the performance of LMs, some recent studies suggest that scaling up the model’s size is crucial for revealing emergent capabilities. In other words, some instances can be solved by small models, while others seem to benefit from increased scale.
Despite recent efforts that enabled the efficient training of LMs over large amounts of data, trained models can still be slow and costly for practical use. When generating text at inference time, most autoregressive LMs output content similar to how we speak and write (word after word), predicting each new word based on the preceding words. This process cannot be parallelized since LMs need to complete the prediction of one word before starting to compute the next one. Moreover, predicting each word requires significant computation given the model’s billions of parameters.
In “Confident Adaptive Language Modeling”, presented at NeurIPS 2022, we introduce a new method for accelerating the text generation of LMs by improving efficiency at inference time. Our method, named CALM, is motivated by the intuition that some next word predictions are easier than others. When writing a sentence, some continuations are trivial, while others might require more effort. Current LMs devote the same amount of compute power for all predictions. Instead, CALM dynamically distributes the computational effort across generation timesteps. By selectively allocating more computational resources only to harder predictions, CALM generates text faster while preserving output quality.
Confident Adaptive Language Modeling
When possible, CALM skips some compute effort for certain predictions. To demonstrate this, we use the popular encoder-decoder T5 architecture. The encoder reads the input text (e.g., a news article to summarize) and converts the text to dense representations. Then, the decoder outputs the summary by predicting it word by word. Both the encoder and decoder include a long sequence of Transformer layers. Each layer includes attention and feedforward modules with many matrix multiplications. These layers gradually modify the hidden representation that is ultimately used for predicting the next word.
Instead of waiting for all decoder layers to complete, CALM attempts to predict the next word earlier, after some intermediate layer. To decide whether to commit to a certain prediction or to postpone the prediction to a later layer, we measure the model’s confidence in its intermediate prediction. The rest of the computation is skipped only when the model is confident enough that the prediction won’t change. For quantifying what is “confident enough”, we calibrate a threshold that statistically satisfies arbitrary quality guarantees over the full output sequence.
 |
| Text generation with a regular language model (top) and with CALM (bottom). CALM attempts to make early predictions. Once confident enough (darker blue tones), it skips ahead and saves time. |
Language Models with Early Exits
Enabling this early exit strategy for LMs requires minimal modifications to the training and inference processes. During training, we encourage the model to produce meaningful representations in intermediate layers. Instead of predicting only using the top layer, our learning loss function is a weighted average over the predictions of all layers, assigning higher weight to top layers. Our experiments demonstrate that this significantly improves the intermediate layer predictions while preserving the full model’s performance. In one model variant, we also include a small early-exit classifier trained to classify if the local intermediate layer prediction is consistent with the top layer. We train this classifier in a second quick step where we freeze the rest of the model.
Once the model is trained, we need a method to allow early-exiting. First, we define a local confidence measure for capturing the model’s confidence in its intermediate prediction. We explore three confidence measures (described in the results section below): (1) softmax response, taking the maximum predicted probability out of the softmax distribution; (2) state propagation, the cosine distance between the current hidden representation and the one from the previous layer; and (3) early-exit classifier, the output of a classifier specifically trained for predicting local consistency. We find the softmax response to be statistically strong while being simple and fast to compute. The other two alternatives are lighter in floating point operations (FLOPS).
Another challenge is that the self-attention of each layer depends on hidden-states from previous words. If we exit early for some word predictions, these hidden-states might be missing. Instead, we attend back to the hidden state of the last computed layer.
Finally, we set up the local confidence threshold for exiting early. In the next section, we describe our controlled process for finding good threshold values. As a first step, we simplify this infinite search space by building on a useful observation: mistakes that are made at the beginning of the generation process are more detrimental since they can affect all of the following outputs. Therefore, we start with a higher (more conservative) threshold, and gradually reduce it with time. We use a negative exponent with user-defined temperature to control this decay rate. We find this allows better control over the performance-efficiency tradeoff (the obtained speedup per quality level).
Reliably Controlling the Quality of the Accelerated Model
Early exit decisions have to be local; they need to happen when predicting each word. In practice, however, the final output should be globally consistent or comparable to the original model. For example, if the original full model generated “the concert was wonderful and long”, one would accept CALM switching the order of the adjectives and outputting “the concert was long and wonderful”. However, at the local level, the word “wonderful” was replaced with “long”. Therefore, the two outputs are globally consistent, but include some local inconsistencies. We build on the Learn then Test (LTT) framework to connect local confidence-based decisions to globally consistent outputs.
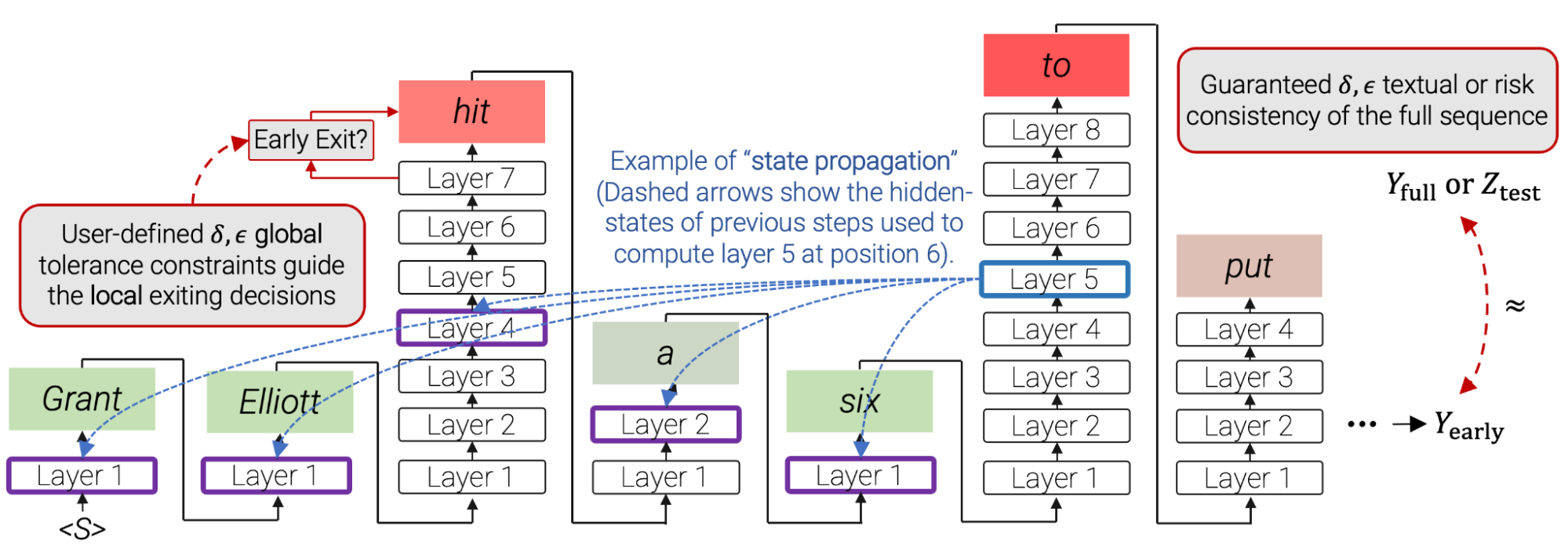 |
| In CALM, local per-timestep confidence thresholds for early exiting decisions are derived, via LTT calibration, from user-defined consistency constraints over the full output text. Red boxes indicate that CALM used most of the decoder’s layers for that specific prediction. Green boxes indicate that CALM saved time by using only a few Transformer layers. Full sentence shown in the last example of this post. |
First, we define and formulate two types of consistency constraints from which to choose:
- Textual consistency: We bound the expected textual distance between the outputs of CALM and the outputs of the full model. This doesn’t require any labeled data.
- Risk consistency: We bound the expected increase in loss that we allow for CALM compared to the full model. This requires reference outputs against which to compare.
For each of these constraints, we can set the tolerance that we allow and calibrate the confidence threshold to allow early exits while reliably satisfying our defined constraint with an arbitrarily high probability.
CALM Saves Inference Time
We run experiments on three popular generation datasets: CNN/DM for summarization, WMT for machine translation, and SQuAD for question answering. We evaluate each of the three confidence measures (softmax response, state propagation and early-exit classifier) using an 8-layer encoder-decoder model. To evaluate global sequence-level performance, we use the standard Rouge-L, BLEU, and Token-F1 scores that measure distances against human-written references. We show that one can maintain full model performance while using only a third or half of the layers on average. CALM achieves this by dynamically distributing the compute effort across the prediction timesteps.
As an approximate upper bound, we also compute the predictions using a local oracle confidence measure, which enables exiting at the first layer that leads to the same prediction as the top one. On all three tasks, the oracle measure can preserve full model performance when using only 1.5 decoder layers on average. In contrast to CALM, a static baseline uses the same number of layers for all predictions, requiring 3 to 7 layers (depending on the dataset) to preserve its performance. This demonstrates why the dynamic allocation of compute effort is important. Only a small fraction of the predictions require most of the model’s complexity, while for others much less should suffice.
 |
| Performance per task against the average number of decoder layers used. |
Finally, we also find that CALM enables practical speedups. When benchmarking on TPUs, we saved almost half of the compute time while maintaining the quality of the outputs.
 |
| Example of a generated news summary. The top cell presents the reference human-written summary. Below is the prediction of the full model (8 layers) followed by two different CALM output examples. The first CALM output is 2.9x faster and the second output is 3.6x faster than the full model, benchmarked on TPUs. |
Conclusion
CALM allows faster text generation with LMs, without reducing the quality of the output text. This is achieved by dynamically modifying the amount of compute per generation timestep, allowing the model to exit the computational sequence early when confident enough.
As language models continue to grow in size, studying how to efficiently use them becomes crucial. CALM is orthogonal and can be combined with many efficiency related efforts, including model quantization, distillation, sparsity, effective partitioning, and distributed control flows.
Acknowledgements
It was an honor and privilege to work on this with Adam Fisch, Ionel Gog, Seungyeon Kim, Jai Gupta, Mostafa Dehghani, Dara Bahri, Vinh Q. Tran, Yi Tay, and Donald Metzler. We also thank Anselm Levskaya, Hyung Won Chung, Tao Wang, Paul Barham, Michael Isard, Orhan Firat, Carlos Riquelme, Aditya Menon, Zhifeng Chen, Sanjiv Kumar, and Jeff Dean for helpful discussions and feedback. Finally, we thank Tom Small for preparing the animation in this blog post.