Editor’s note: Today is the final installment in a seven-part video and blog series from Google Developer Advocate Sandeep Dinesh on how to get the most out of your Kubernetes environment.
Everyone knows it’s a good practice to keep your application up to date to optimize security and performance. Kubernetes and Docker can make performing these updates much easier, as you can build a new container with the updates and deploy it with relative ease.
Just like your applications, Kubernetes is constantly getting new features and security updates, so the underlying nodes and Kubernetes infrastructure need to be kept up to date as well.
In this episode of Kubernetes Best Practices, let’s take a look at how Google Kubernetes Engine can make upgrading your Kubernetes cluster painless!
The two parts of a cluster
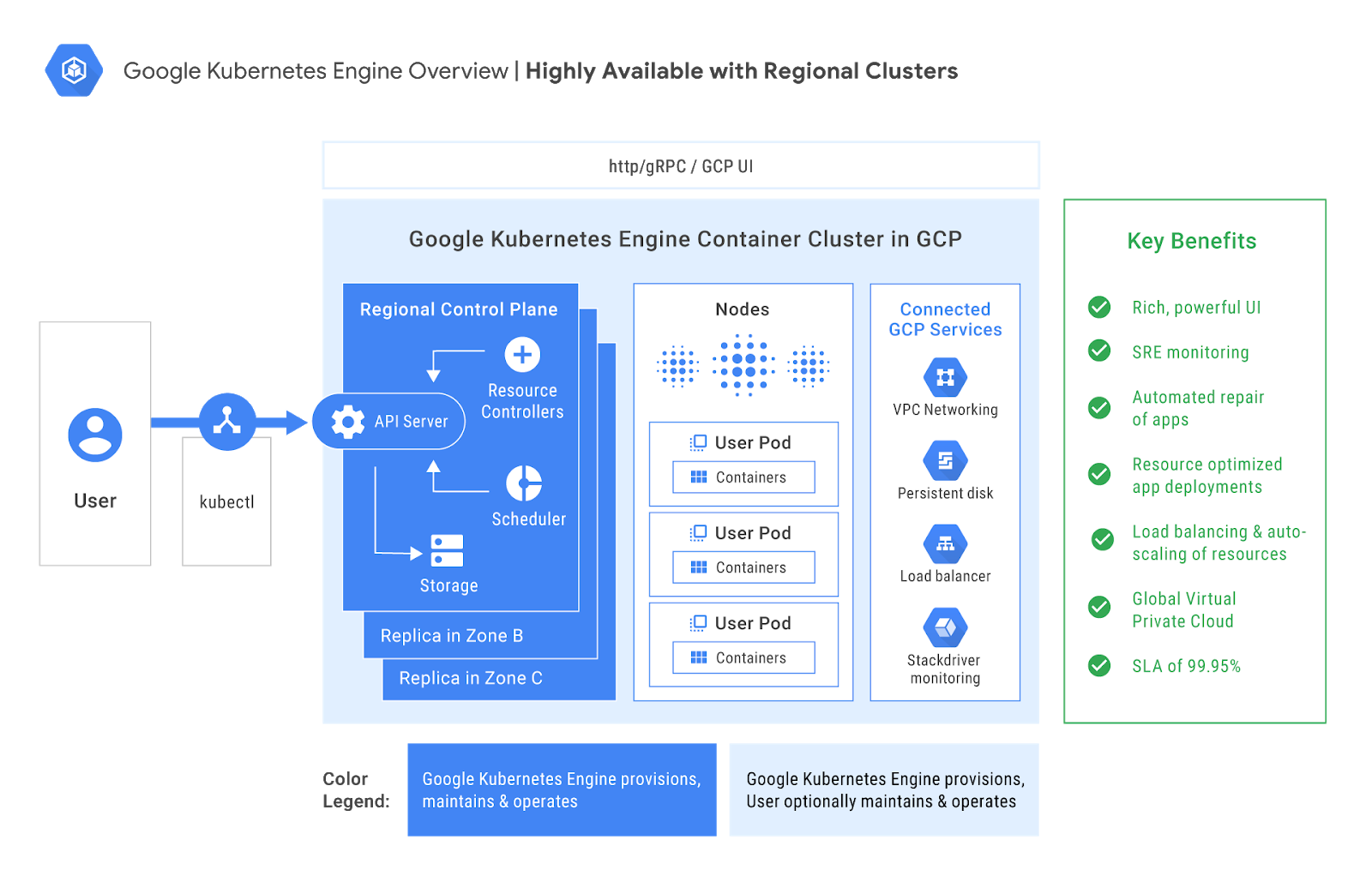
When it comes to upgrading your cluster, there are two parts that both need to be updated: the masters and the nodes. The masters need to be updated first, and then the nodes can follow. Let’s see how to upgrade both using Kubernetes Engine.Upgrading the master with zero downtime
Kubernetes Engine automatically upgrades the master as point releases are released, however it usually won’t upgrade to a new version (for example, 1.7 to 1.8) automatically. When you are ready to upgrade to a new version, you can just click the upgrade master button in the Kubernetes Engine console.

However, you may have noticed that the dialog box says the following:
“Changing the master version can result in several minutes of control plane downtime. During that period you will be unable to edit this cluster.”
When the master goes down for the upgrade, deployments, services, etc. continue to work as expected. However, anything that requires the Kubernetes API stops working. This means kubectl stops working, applications that use the Kubernetes API to get information about the cluster stop working, and basically you can’t make any changes to the cluster while it is being upgraded.
So how do you update the master without incurring downtime?
Highly available masters with Kubernetes Engine regional clusters
While the standard “zonal” Kubernetes Engine clusters only have one master node backing them, you can create “regional” clusters that provide multi-zone, highly available masters.When creating your cluster, be sure to select the “regional” option:

And that’s it! Kubernetes Engine automatically creates your nodes and masters in three zones, with the masters behind a load-balanced IP address, so the Kubernetes API will continue to work during an upgrade.
Upgrading nodes with zero downtime
When upgrading nodes, there are a few different strategies you can use. There are two I want to focus on:- Rolling update
- Migration with node pools
The simplest way to update your Kubernetes nodes is to use a rolling update. The is the default upgrade mechanism Kubernetes Engine uses to update your nodes.
A rolling update works in the following way. One by one, a node is drained and cordoned so that there are no more pods running on that node. Then the node is deleted, and a new node is created with the updated Kubernetes version. Once that node is up and running, the next node is updated. This goes on until all nodes are updated.
You can let Kubernetes Engine manage this process for you completely by enabling automatic node upgrades on the node pool.

If you don’t select this, the Kubernetes Engine dashboard alerts you when an upgrade is available:
 Just click the link and follow the prompt to begin the rolling update.
Just click the link and follow the prompt to begin the rolling update.Warning: Make sure your pods are managed by a ReplicaSet, Deployment, StatefulSet, or something similar. Standalone pods won’t be rescheduled!
While it’s simple to perform a rolling update on Kubernetes Engine, it has a few drawbacks.
One drawback is that you get one less node of capacity in your cluster. This issue is easily solved by scaling up your node pool to add extra capacity, and then scaling it back down once the upgrade is finished.
The fully automated nature of the rolling update makes it easy to do, but you have less control over the process. It also takes time to roll back to the old version if there is a problem, as you have to stop the rolling update and then undo it.
Migration with node pools
Instead of upgrading the “active” node pool as you would with a rolling update, you can create a fresh node pool, wait for all the nodes to be running, and then migrate workloads over one node at a time.
Let’s assume that our Kubernetes cluster has three VMs right now. You can see the nodes with the following command:
kubectl get nodes
NAME STATUS AGE
gke-cluster-1-default-pool-7d6b79ce-0s6z Ready 3h
gke-cluster-1-default-pool-7d6b79ce-9kkm Ready 3h
gke-cluster-1-default-pool-7d6b79ce-j6ch Ready 3hCreating the new node pool
To create the new node pool with the name “pool-two”, run the following command:
gcloud container node-pools create pool-twoNote: Remember to customize this command so that the new node pool is the same as the old pool. You can also use the GUI to create a new node pool if you want.
Now if you check the nodes, you will notice there are three more nodes with the new pool name:
$ kubectl get nodes
NAME STATUS AGE
gke-cluster-1-pool-two-9ca78aa9–5gmk Ready 1m
gke-cluster-1-pool-two-9ca78aa9–5w6w Ready 1m
gke-cluster-1-pool-two-9ca78aa9-v88c Ready 1m
gke-cluster-1-default-pool-7d6b79ce-0s6z Ready 3h
gke-cluster-1-default-pool-7d6b79ce-9kkm Ready 3h
gke-cluster-1-default-pool-7d6b79ce-j6ch Ready 3hHowever, the pods are still on the old nodes! Let’s move them over.
Drain the old pool
Now we need to move work to the new node pool. Let’s move over one node at a time in a rolling fashion.
First, cordon each of the old nodes. This will prevent new pods from being scheduled onto them.
kubectl cordon <node_name>Warning: Make sure your pods are managed by a ReplicaSet, Deployment, StatefulSet, or something similar. Standalone pods won’t be rescheduled!
Run the following command to drain each node. This deletes all the pods on that node.
kubectl drain <node_name> --forceAfter you drain a node, make sure the new pods are up and running before moving on to the next one.
If you have any issues during the migration, uncordon the old pool and then cordon and drain the new pool. The pods get rescheduled back to the old pool.
Delete the old pool
Once all the pods are safely rescheduled, it is time to delete the old pool.
Replace “default-pool” with the pool you want to delete.
gcloud container node-pools delete default-poolYou have just successfully updated all your nodes!
Conclusion
By using Kubernetes Engine, you can keep your Kubernetes cluster up to date with just a few clicks.
If you are not using a managed service like Kubernetes, you can still use the rolling update or node pools method with your own cluster to upgrade nodes. The difference is you need to manually add the new nodes to your cluster, and perform the master upgrade yourself, which can be tricky.
I highly recommend using Kubernetes Engine regional clusters for the high-availability masters and automatic node upgrades to have a hassle-free upgrade experience. If you need the extra control for your node updates, using node pools gives you that control without giving up the advantages of a managed Kubernetes platform that Kubernetes Engine gives you.
And thus concludes this series on Kubernetes best practices. If you have ideas for other topics you’d like me to address in the future, you can find me on Twitter. And if you’re attending Google Cloud Next ‘18 this July, be sure to drop by and say hi!