By Aparna Sinha, Group Product Manager, Container Engine
Just over a week ago Google led the most recent open source release of Kubernetes 1.7, and today, that version is available on
Container Engine,
Google Cloud Platform’s (GCP) managed container service. Container Engine is one of the first commercial
Kubernetes offerings running the latest 1.7 release, and includes differentiated features for enterprise security, extensibility, hybrid networking and developer efficiency. Let’s take a look at what’s new in Container Engine.
Enterprise security
Container Engine is designed with enterprise security in mind. By default, Container Engine clusters run a minimal, Google curated
Container-Optimized OS (COS) to ensure you don’t have to worry about OS vulnerabilities. On top of that, a team of Google
Site Reliability Engineers continuously monitor and manage the Container Engine clusters, so you don’t have to. Now, Container Engine adds several new security enhancements:
- Starting with this release, kubelet will only have access to the objects it needs to know. The Node authorizer beta restricts each kubelet’s API access to resources (such as secrets) belonging to its scheduled pods. This feature increases the protection of a cluster from a compromised/untrusted node.
- Network isolation can be an important extra boundary for sensitive workloads. The Kubernetes NetworkPolicy API allows users to control which pods can communicate with each other, providing defense-in-depth and improving secure multi-tenancy. Policy enforcement can now be enabled in alpha clusters.
- HTTP re-encryption through Google Cloud Load Balancing (GCLB) allows customers to use HTTPS from the GCLB to their service backends. This is an often requested feature that gives customers the peace of mind knowing that their data is fully encrypted in-transit even after it enters Google’s global network.
Together the above features improve workload isolation within a cluster, which is a frequently requested security feature in Kubernetes. Node Authorizer and NetworkPolicy can be combined with the existing RBAC control in Container Engine to improve the foundations of multi-tenancy:
- Network isolation between Pods (network policy)
- Resource isolation between Nodes (node authorizer)
- Centralized control over cluster resources (RBAC)
Enterprise and hybrid networks
Perhaps the most awaited features by our enterprise users are networking support for hybrid cloud and VPN with Container Engine. New in this release:
- GA Support for all private IP (RFC-1918) addresses, allowing users to create clusters and access resources in all private IP ranges and extending the ability to use Container Engine clusters with existing networks.
- Exposing services by internal load balancing is beta, allowing Kubernetes and non-Kubernetes services to access one another on a private network1.
- Source IP preservation is now generally available and allows applications to be fully aware of client IP addresses for services exposed through Kubernetes
Enterprise extensibility
As more enterprises use Container Engine, we're making a major investment to improve extensibility. We heard feedback that customers want to offer custom Kubernetes-style APIs in their clusters.
API Aggregation, launching today in beta on Container Engine, enables you to extend the Kubernetes API with custom APIs. For example, you can now add existing API solutions such as
service catalog, or build your own in the future.
Users also want to incorporate custom business logic and third-party solutions into their Container Engine clusters. So we’re introducing
Dynamic Admission Control in alpha clusters, providing two ways to add business logic to your cluster:
- Initializers can modify Kubernetes objects as they are created. For example, you can use an initializer to add Istio capability to a Container Engine alpha cluster, by injecting an Istio sidecar container in every Pod deployed.
- Webhooks enable you to validate enterprise policy. For example, you can verify that containers being deployed pass your enterprise security audits.
As part of our plans to improve extensibility for enterprises, we're replacing the Third Party Resource (TPR) API with the improved Custom Resource Definition (CRD) API. CRDs are a lightweight way to store structured metadata in Kubernetes, which make it easy to interact with custom controllers via kubectl. If you use the TPR beta feature, please plan to
migrate to CRD before upgrading to the 1.8 release.
Workload diversity
Container Engine now enhances your ability to run stateful workloads like databases and key value stores, such as ZooKeeper, with a new automated application update capability. You can:
- Select from a range of StatefulSet update strategies beta, including rolling updates
- Optimize roll-out speed with parallel or ordered pod provisioning, particularly useful for applications such as Kafka.
A popular workload on Google Cloud and Container Engine is training machine learning models for better predictive analytics. Many of you have requested GPUs to speed up training time, so we’ve updated Container Engine to support NVIDIA K80 GPUs in
alpha clusters for experimentation with this exciting feature. We’ll support additional GPUs in the future.
Developer efficiency
When developers don’t have to worry about infrastructure, they can spend more time building applications. Kubernetes provides building blocks to de-couple infrastructure and application management, and Container Engine builds on that foundation with best-in-class automation features.
We’ve automated large parts of maintaining the health of the cluster, with auto-repair and auto-upgrade of nodes.
- Auto-repair beta keeps your cluster healthy by proactively monitoring for unhealthy nodes and repairs them automatically without developer involvement.
- In this release, Container Engine’s auto-upgrade beta capability incorporates Pod Disruption Budgets at the node layer, making upgrades to infrastructure and application controllers predictable and safer.
Container Engine also offers cluster- and pod-level auto-scaling so applications can respond to user demand without manual intervention. This release introduces several GCP-optimized enhancements to cluster autoscaling:
- Support for scaling node pools to 0 or 1, for when you don’t need capacity
- Price-based expander for auto-scaling in the most cost-effective way
- Balanced scale-out of similar node groups, useful for clusters that span multiple zones
The combination of auto-repair, auto-upgrades and cluster autoscaling in Container Engine enables application developers to deploy and scale their apps without being cluster admins.
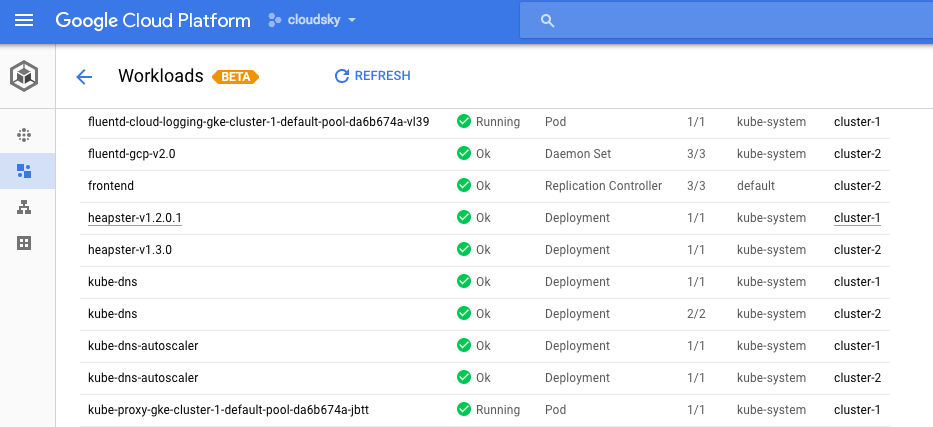
We’ve also updated the
Container Engine UI to assist in debugging and troubleshooting by including detailed workload-related views. For each workload, we show the type (DaemonSet, Deployment, StatefulSet, etc.), running status, namespace and cluster. You can also debug each pod and view annotations, labels, the number of replicas and status, etc. All views are cross-cluster so if you're using multiple clusters, these views allow you to focus on your workloads, no matter where they run. In addition, we also include load balancing and configuration views with deep links to GCP networking, storage and compute. This new UI will be rolling out in the coming week.
Container Engine everywhere
Google Cloud is enabling a shift in enterprise computing: from local to global, from days to seconds, and from proprietary to open. The benefits of this model are becoming clear and exemplified by Container Engine, which saw more than 10x growth last year.
To keep up with demand, we're expanding our global capacity with new Container Engine clusters in our latest
GCP regions:
- Sydney (australia-southeast1)
- Singapore (asia-southeast1)
- Oregon (us-west1)
- London (europe-west2)
These new
regions join the half dozen others from Iowa to Belgium to Taiwan where Container Engine clusters are already up and running.
This blog post highlighted some of the new features available in Container Engine. You can find the complete list of new features in the Container Engine
release notes.
The rapid adoption of Container Engine and its technology is translating into real customer impact. Here are a few recent stories that highlight the benefits companies are seeing:
- BQ, one of the leading technology companies in Europe that designs and develops consumer electronics, was able to scale quickly from 15 to 350 services while reducing its cloud hosting costs by approximately 60% through better utilization and use of Preemptible VMs on Container Engine. Read the full story here.
- Meetup, the social media networking platform, switched from a monolithic application in on-premises data centers to an agile microservices architecture in a multi-cloud environment with the help of Container Engine. This gave its engineering teams autonomy to work on features and develop roadmaps that are independent from other teams, translating into faster release schedules, greater creativity and new functionality. Read the case study here.
- Loot Crate, a leader in fan subscription boxes, launched a new offering on Container Engine to quickly get their Rails app production ready and able to scale with demand and zero downtime deployments. Read how it built its continuous deployment pipeline with Jenkins in this post.
At Google Cloud we’re really proud of our compute infrastructure, but what really makes it valuable is the services that run on top. Google creates game-changing services on top of world-class infrastructure and tooling. With Kubernetes and Container Engine, Google Cloud makes these innovations available to developers everywhere.
GCP is the first cloud offering a fully managed way to try the newest Kubernetes release, and with our generous 12-month
free trial of $300 credits, there’s no excuse to not
try it today.
Thanks for your feedback and support. Keep the conversation going and connect with us on the
Container Engine Slack channel.
1 Support for accessing Internal Load Balancers over Cloud VPN is currently in alpha; customers can apply for access here.