By Rohit Bhatia, Mollie Bates, Google Chrome Security
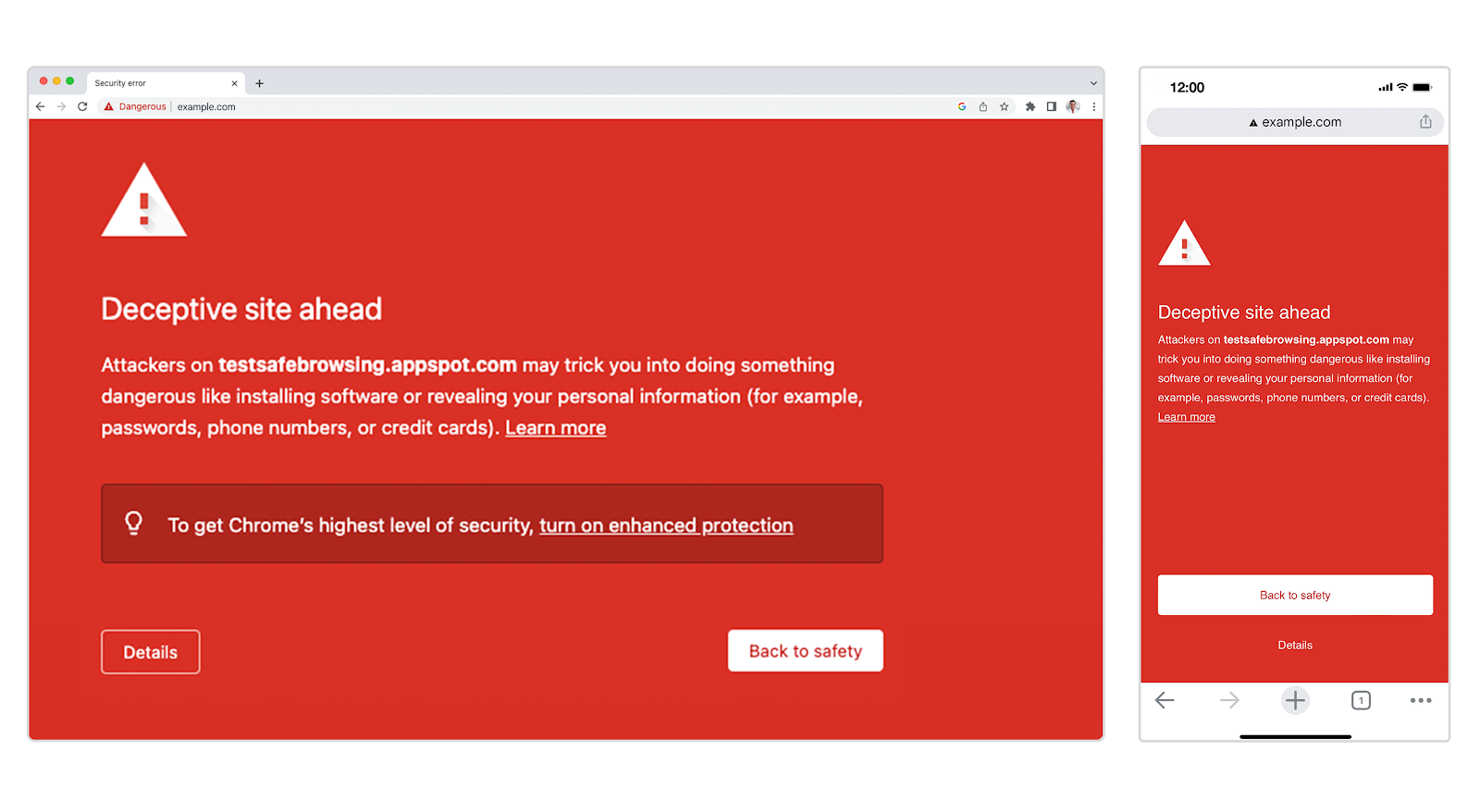
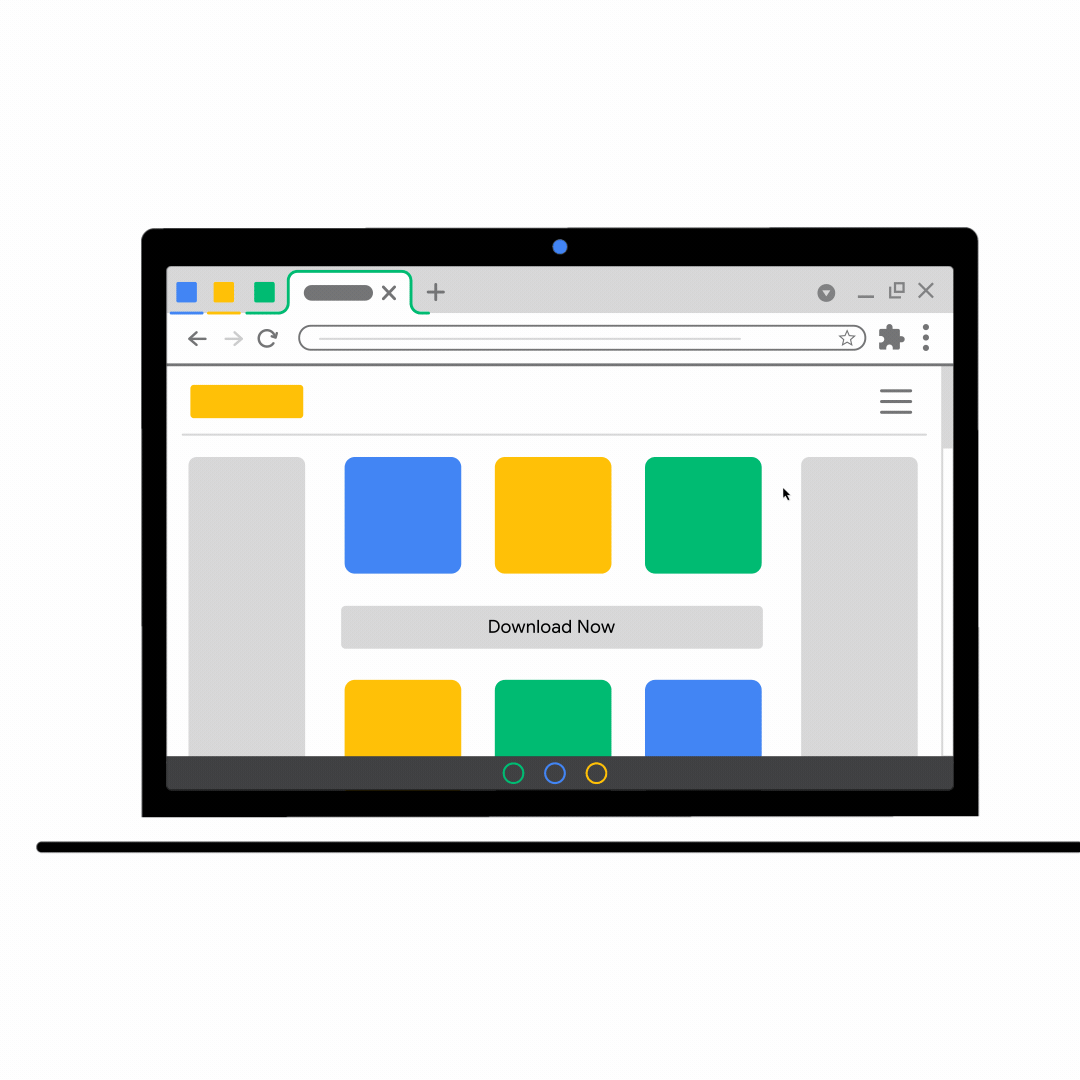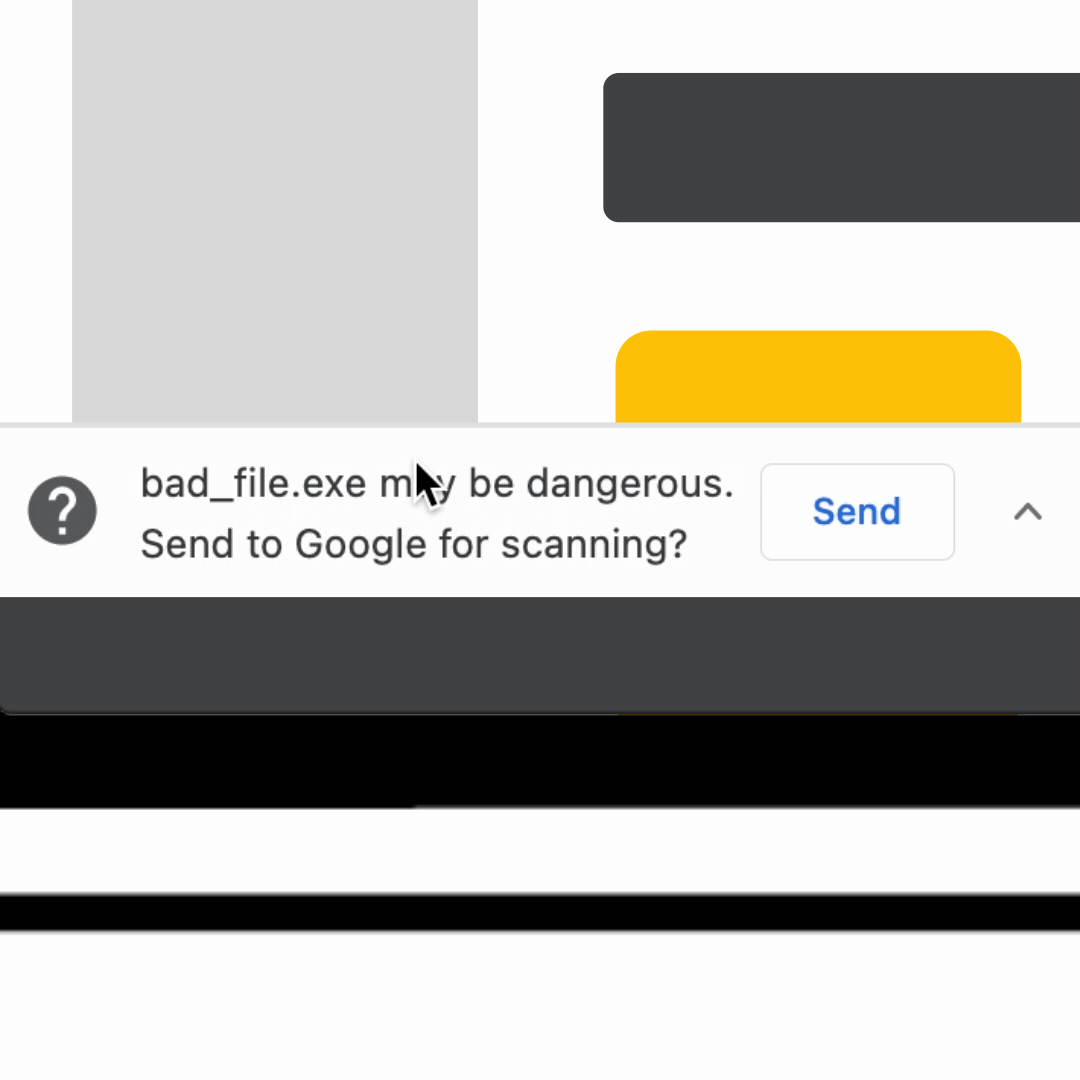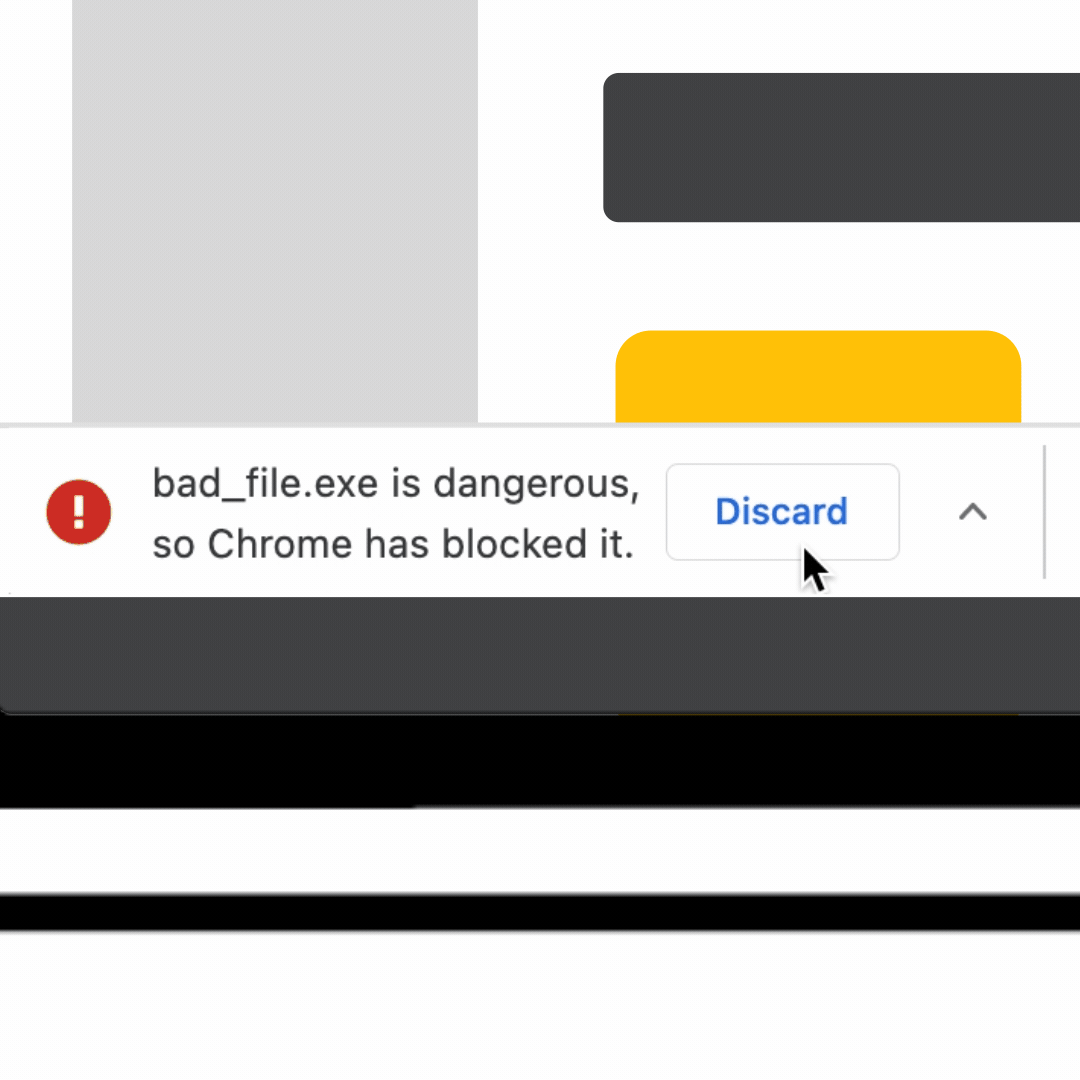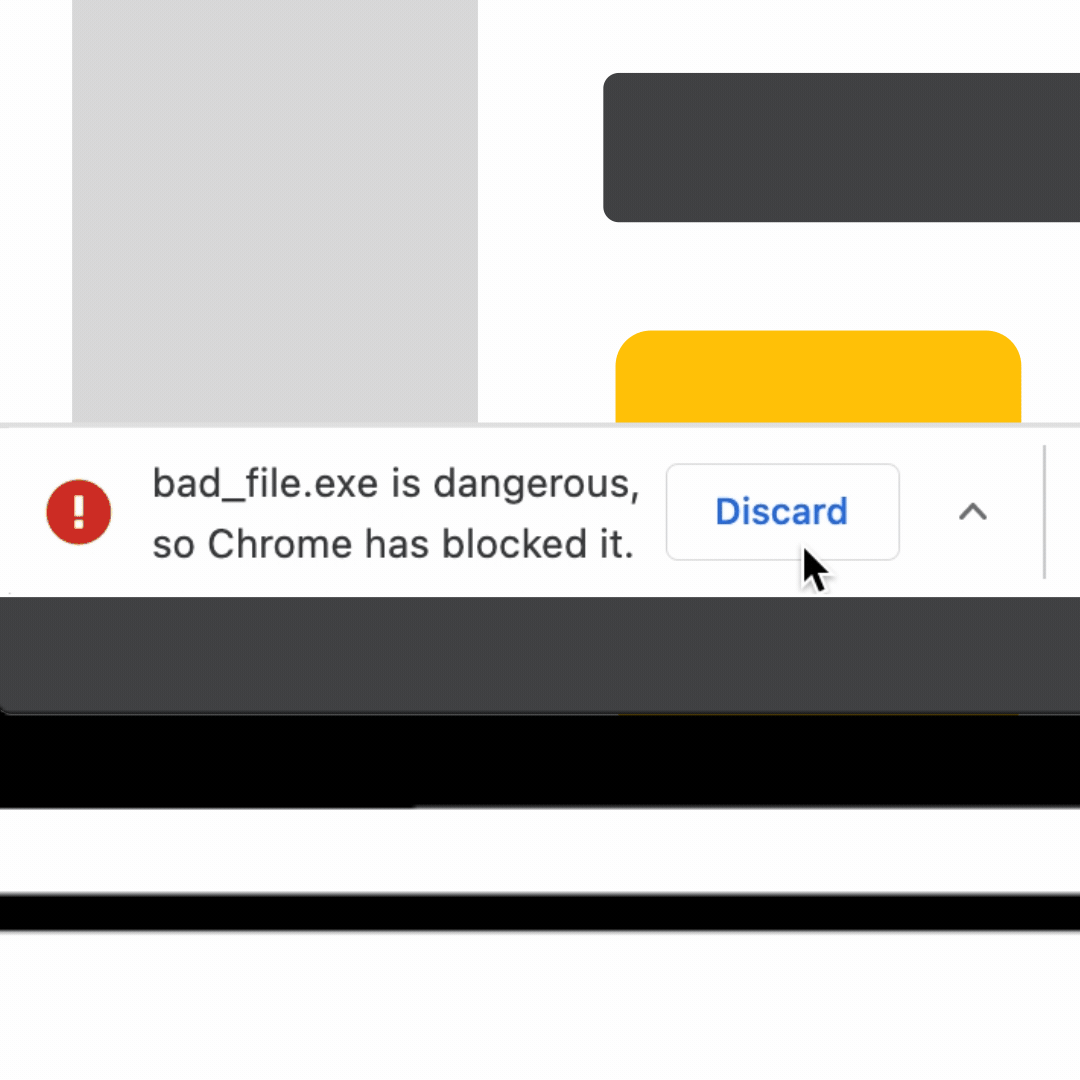
There are various threats a user faces when browsing the web. Users may be tricked into sharing sensitive information like their passwords with a misleading or fake website, also called phishing. They may also be led into installing malicious software on their machines, called malware, which can collect personal data and also hold it for ransom. Google Chrome, henceforth called Chrome, enables its users to protect themselves from such threats on the internet. When Chrome users browse the web with Safe Browsing protections, Chrome uses the Safe Browsing service from Google to identify and ward off various threats.
Safe Browsing works in different ways depending on the user's preferences. In the most common case, Chrome uses the privacy-conscious Update API (Application Programming Interface) from the Safe Browsing service. This API was developed with user privacy in mind and ensures Google gets as little information about the user's browsing history as possible. If the user has opted-in to "Enhanced Protection" (covered in an earlier post) or "Make Searches and Browsing Better", Chrome shares limited additional data with Safe Browsing only to further improve user protection.
This post describes how Chrome implements the Update API, with appropriate pointers to the technical implementation and details about the privacy-conscious aspects of the Update API. This should be useful for users to understand how Safe Browsing protects them, and for interested developers to browse through and understand the implementation. We will cover the APIs used for Enhanced Protection users in a future post.
Threats on the Internet
When a user navigates to a webpage on the internet, their browser fetches objects hosted on the internet. These objects include the structure of the webpage (HTML), the styling (CSS), dynamic behavior in the browser (Javascript), images, downloads initiated by the navigation, and other webpages embedded in the main webpage. These objects, also called resources, have a web address which is called their URL (Uniform Resource Locator). Further, URLs may redirect to other URLs when being loaded. Each of these URLs can potentially host threats such as phishing websites, malware, unwanted downloads, malicious software, unfair billing practices, and more. Chrome with Safe Browsing checks all URLs, redirects or included resources, to identify such threats and protect users.
Safe Browsing Lists
Safe Browsing provides a list for each threat it protects users against on the internet. A full catalog of lists that are used in Chrome can be found by visiting chrome://safe-browsing/#tab-db-manager on desktop platforms.
A list does not contain unsafe web addresses, also referred to as URLs, in entirety; it would be prohibitively expensive to keep all of them in a device’s limited memory. Instead it maps a URL, which can be very long, through a cryptographic hash function (SHA-256), to a unique fixed size string. This distinct fixed size string, called a hash, allows a list to be stored efficiently in limited memory. The Update API handles URLs only in the form of hashes and is also called hash-based API in this post.
Further, a list does not store hashes in entirety either, as even that would be too memory intensive. Instead, barring a case where data is not shared with Google and the list is small, it contains prefixes of the hashes. We refer to the original hash as a full hash, and a hash prefix as a partial hash.
A list is updated following the Update API’s request frequency section. Chrome also follows a back-off mode in case of an unsuccessful response. These updates happen roughly every 30 minutes, following the minimum wait duration set by the server in the list update response.
For those interested in browsing relevant source code, here’s where to look:
Source Code
- GetListInfos() contains all the lists, along with their associated threat types, the platforms they are used on, and their file names on disk.
- HashPrefixMap shows how the lists are stored and maintained. They are grouped by the size of prefixes, and appended together to allow quick binary search based lookups.
How is hash-based URL lookup done
As an example of a Safe Browsing list, let's say that we have one for malware, containing partial hashes of URLs known to host malware. These partial hashes are generally 4 bytes long, but for illustrative purposes, we show only 2 bytes.
['036b', '1a02', 'bac8', 'bb90']
Whenever Chrome needs to check the reputation of a resource with the Update API, for example when navigating to a URL, it does not share the raw URL (or any piece of it) with Safe Browsing to perform the lookup. Instead, Chrome uses full hashes of the URL (and some combinations) to look up the partial hashes in the locally maintained Safe Browsing list. Chrome sends only these matched partial hashes to the Safe Browsing service. This ensures that Chrome provides these protections while respecting the user’s privacy. This hash-based lookup happens in three steps in Chrome:
Step 1: Generate URL Combinations and Full Hashes
When Google blocks URLs that host potentially unsafe resources by placing them on a Safe Browsing list, the malicious actor can host the resource on a different URL. A malicious actor can cycle through various subdomains to generate new URLs. Safe Browsing uses host suffixes to identify malicious domains that host malware in their subdomains. Similarly, malicious actors can also cycle through various subpaths to generate new URLs. So Safe Browsing also uses path prefixes to identify websites that host malware at various subpaths. This prevents malicious actors from cycling through subdomains or paths for new malicious URLs, allowing robust and efficient identification of threats.
To incorporate these host suffixes and path prefixes, Chrome first computes the full hashes of the URL and some patterns derived from the URL. Following Safe Browsing API's URLs and Hashing specification, Chrome computes the full hashes of URL combinations by following these steps:
- First, Chrome converts the URL into a canonical format, as defined in the specification.
- Then, Chrome generates up to 5 host suffixes/variants for the URL.
- Then, Chrome generates up to 6 path prefixes/variants for the URL.
- Then, for the combined 30 host suffixes and path prefixes combinations, Chrome generates the full hash for each combination.
Source Code
- V4LocalDatabaseManager::CheckBrowseURL is an example which performs a hash-based lookup.
- V4ProtocolManagerUtil::UrlToFullHashes creates the various URL combinations for a URL, and computes their full hashes.
Example
For instance, let's say that a user is trying to visit https://evil.example.com/blah#frag. The canonical url is https://evil.example.com/blah. The host suffixes to be tried are evil.example.com, and example.com. The path prefixes are / and /blah. The four combined URL combinations are evil.example.com/, evil.example.com/blah, example.com/, and example.com/blah.
url_combinations = ["evil.example.com/", "evil.example.com/blah","example.com/", "example.com/blah"]
full_hashes = ['1a02…28', 'bb90…9f', '7a9e…67', 'bac8…fa']
Step 2: Search Partial Hashes in Local Lists
Chrome then checks the full hashes of the URL combinations against the locally maintained Safe Browsing lists. These lists, which contain partial hashes, do not provide a decisive malicious verdict, but can quickly identify if the URL is considered not malicious. If the full hash of the URL does not match any of the partial hashes from the local lists, the URL is considered safe and Chrome proceeds to load it. This happens for more than 99% of the URLs checked.
Source Code
- V4LocalDatabaseManager::GetPrefixMatches gets the matching partial hashes for the full hashes of the URL and its combinations.
Example
Chrome finds that three full hashes 1a02…28, bb90…9f, and bac8…fa match local partial hashes. We note that this is for demonstration purposes, and a match here is rare.
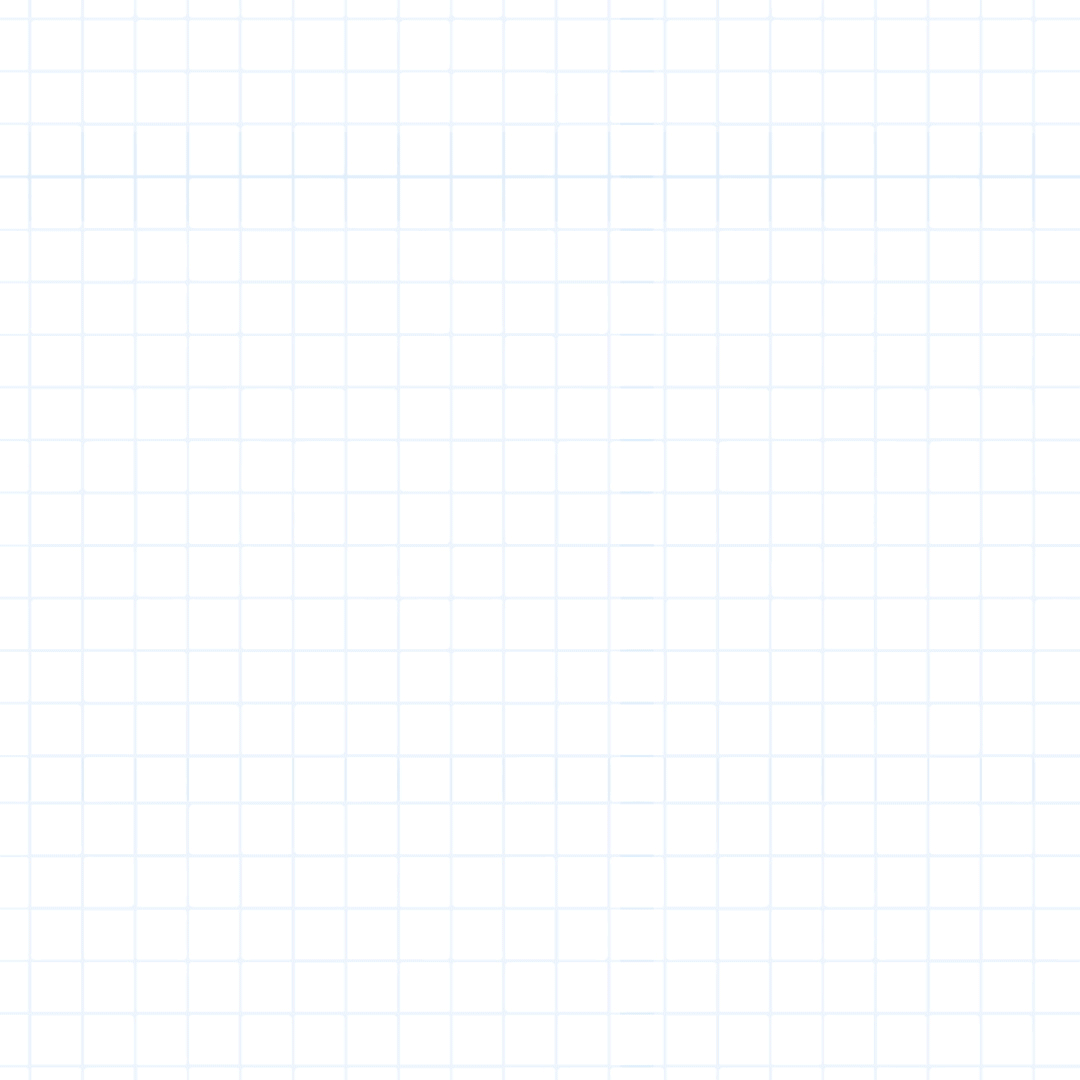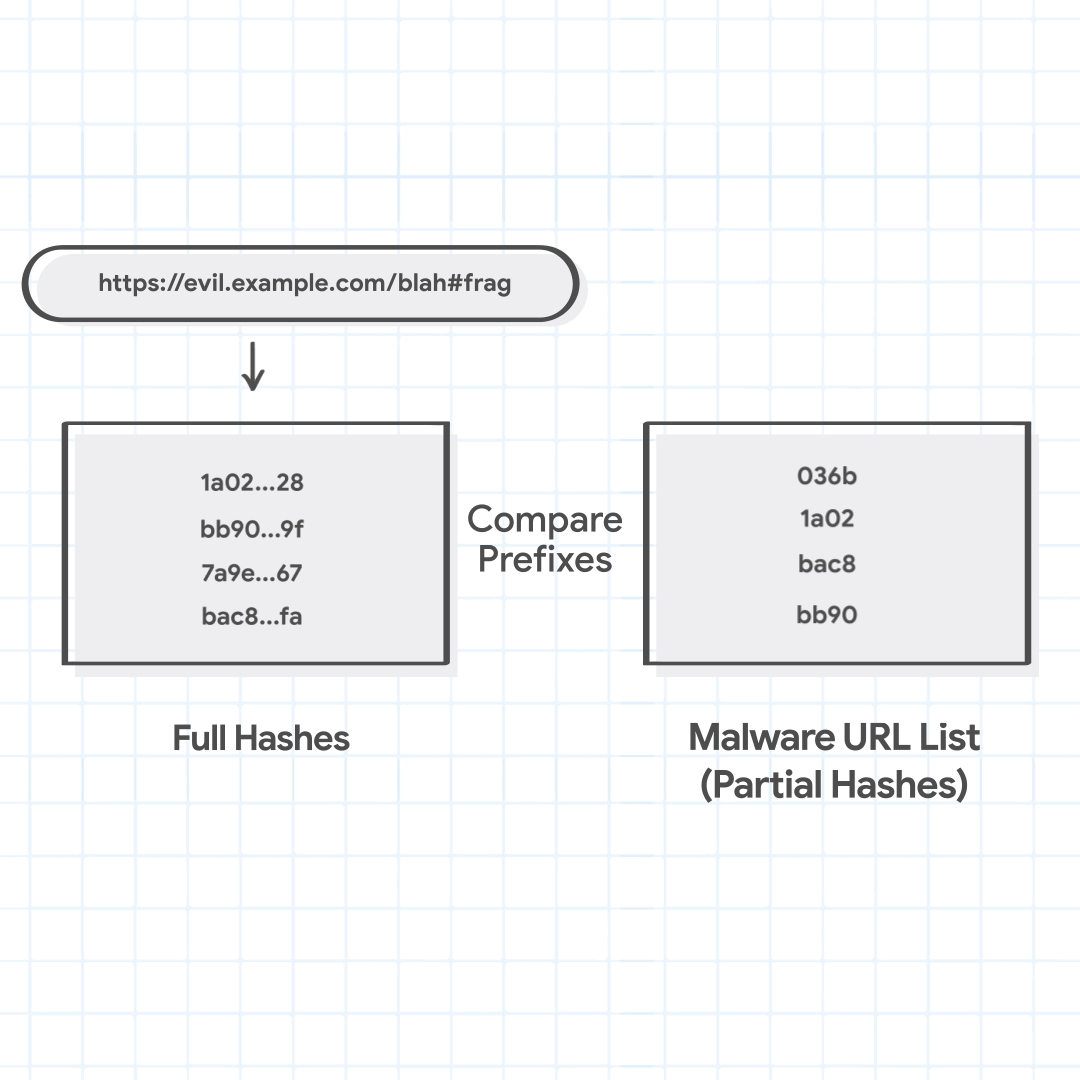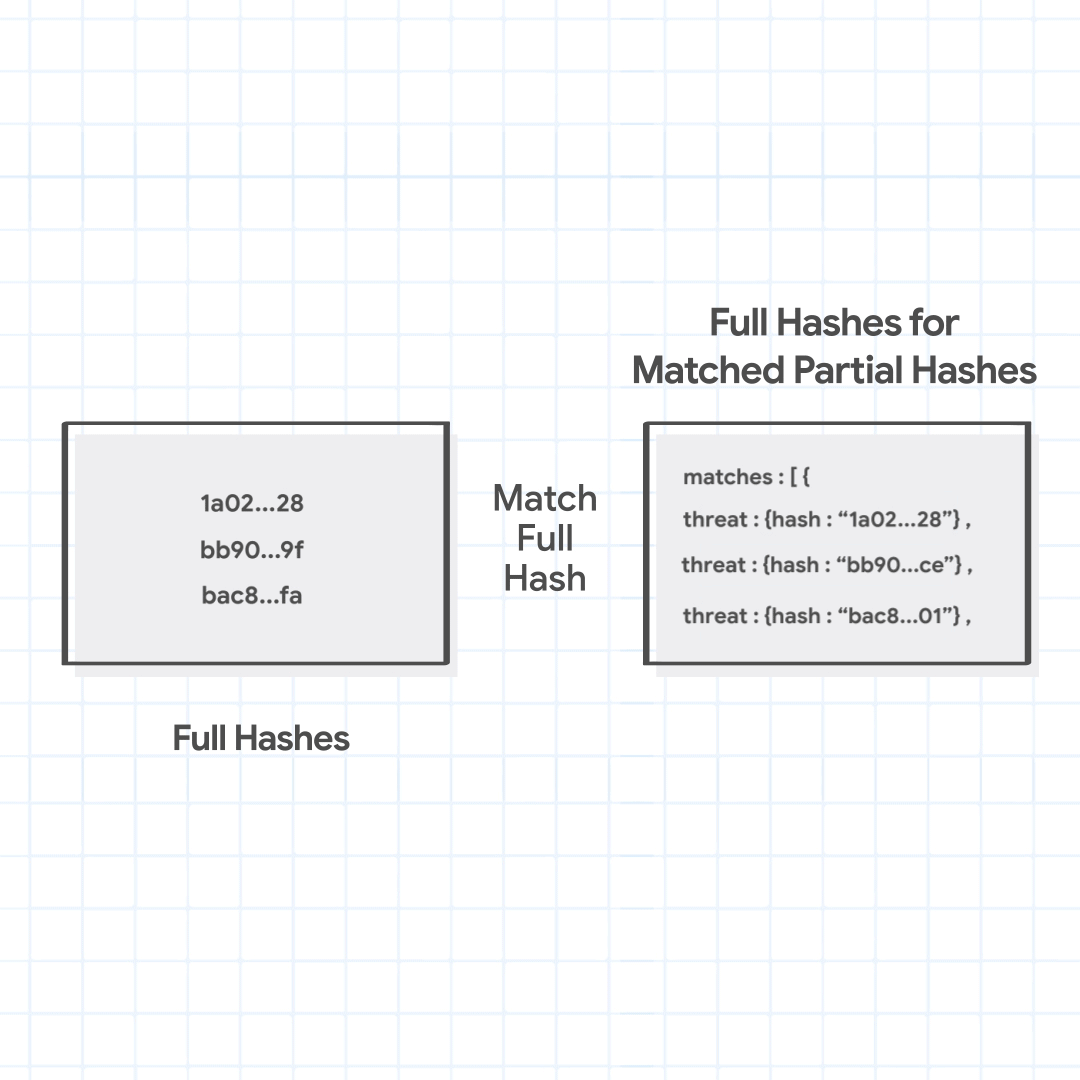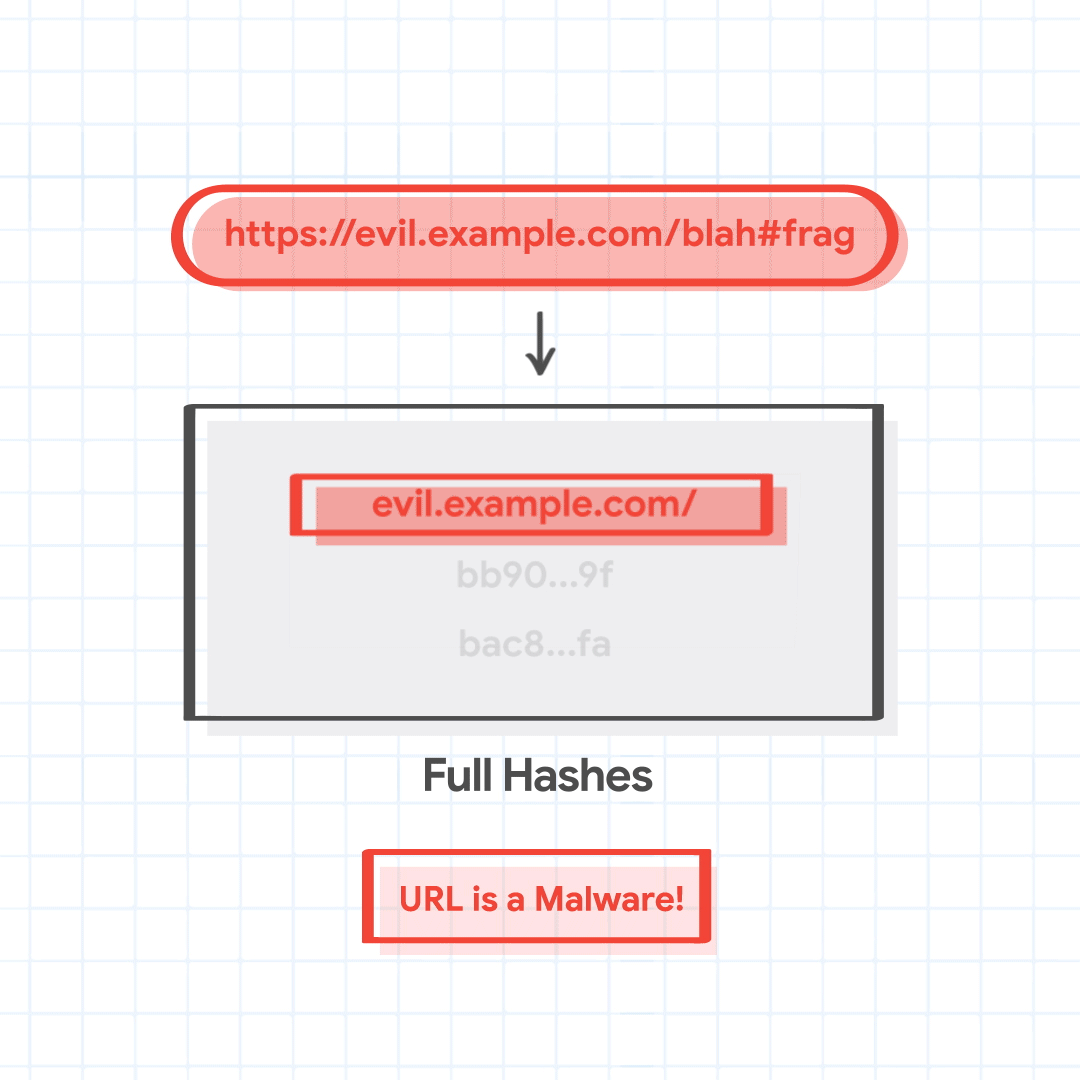
Step 3: Fetch Matching Full Hashes
Next, Chrome sends only the matching partial hash (not the full URL or any particular part of the URL, or even their full hashes), to the Safe Browsing service's fullHashes.find method. In response, it receives the full hashes of all malicious URLs for which the full hash begins with one of the partial hashes sent by Chrome. Chrome checks the fetched full hashes with the generated full hashes of the URL combinations. If any match is found, it identifies the URL with various threats and their severities inferred from the matched full hashes.
Source Code
- V4GetHashProtocolManager::GetFullHashes performs the lookup for the full hashes for the matched partial hashes.
Example
Chrome sends the matched partial hashes 1a02, bb90, and bac8 to fetch the full hashes. The server returns full hashes that match these partial hashes, 1a02…28, bb90…ce, and bac8…01. Chrome finds that one of the full hashes matches with the full hash of the URL combination being checked, and identifies the malicious URL as hosting malware.
Conclusion
Safe Browsing protects Chrome users from various malicious threats on the internet. While providing these protections, Chrome faces challenges such as constraints in memory capacity, network bandwidth usage, and a dynamic threat landscape. Chrome is also mindful of the users’ privacy choices, and shares little data with Google.
In a follow up post, we will cover the more advanced protections Chrome provides to its users who have opted in to “Enhanced Protection”.