Posted by Kenny Sulaimon, Product Manager, ML Kit Chengji Yan, Suril Shah, Buck Bourdon, Software Engineers, ML Kit, Shiyu Hu, Technical Lead, ML Kit Dong Chen, Technical Lead, ML Kit
At the end of 2020, we introduced the Entity Extraction API to our ML Kit SDK, making it even easier to detect and perform actions on text within mobile apps. Since then, we’ve been hard at work updating our existing APIs with new functionality and also fine tuning Selfie Segmentation with the help of our partners in the ML Kit early access program.
Today we are excited to officially add Selfie Segmentation to the ML Kit lineup, introduce a few enhancements we’ve made to our popular Pose Detection API and announce that ML Kit has graduated to general availability!
General Availability
(ML Kit is now in General Availability)
We launched ML Kit back in 2018 in order to make it easy for developers on Android and iOS to use machine learning within their apps. Over the last two years we have rapidly expanded our set of APIs to help with both vision and natural language processing based use cases.
Thanks to the overwhelmingly positive response, developer feedback and a ton of adoption across both Android and iOS, we are ready to drop the beta label and officially announce the general availability of ML Kit’s APIs. All of our APIs (except Selfie Segmentation, Pose Detection, and Entity Extraction) are now in general availability!
Selfie Segmentation

(Example of ML Kit Selfie Segmentation)
With the increased usage of selfie cameras and webcams in today's world, being able to quickly and easily add effects to camera experiences has become a necessity for many app developers.
ML Kit's Selfie Segmentation API allows developers to easily separate the background from users within a scene and focus on what matters. Adding cool effects to selfies or inserting your users into interesting background environments has never been easier. The model works on live and still images, and both half and full body subjects.
Under The Hood
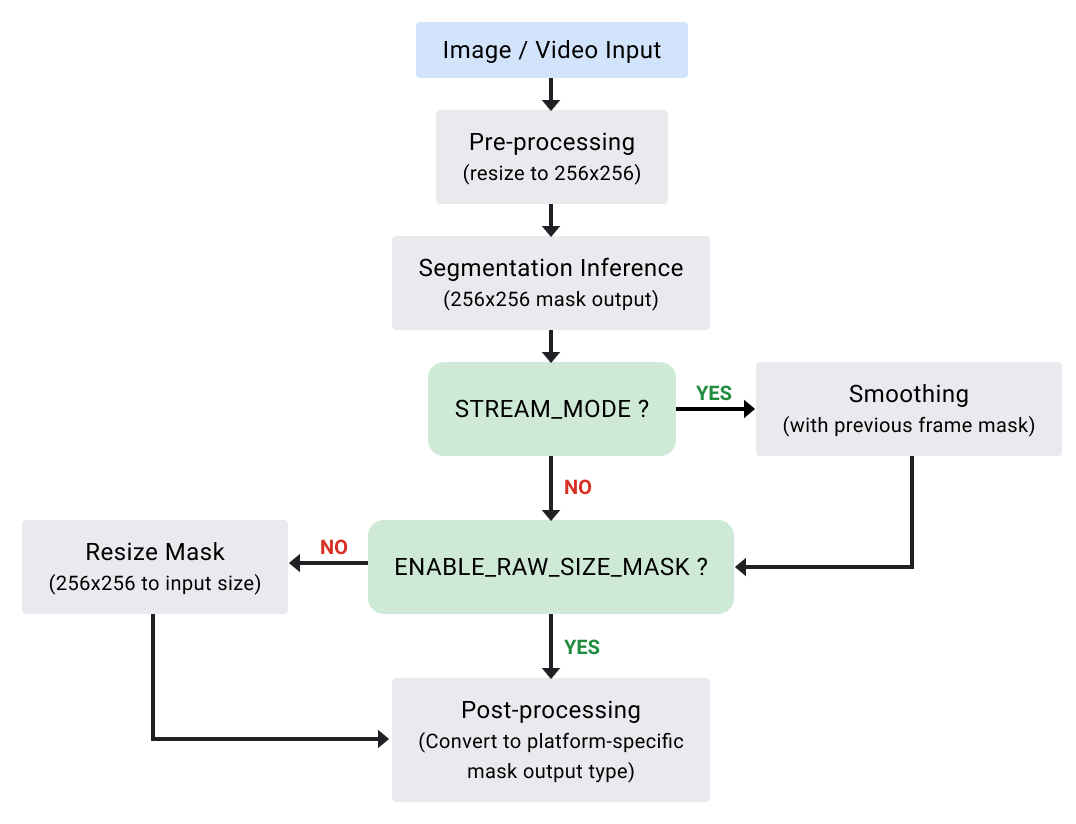
(Diagram of Selfie Segmentation API)
The Selfie Segmentation API takes an input image and produces an output mask. Each pixel of the mask is assigned a float number that has a range between [0.0, 1.0]. The closer the number is to 1.0, the higher the confidence that the pixel represents a person, and vice versa.
The API works with static images and live video use cases. During live video (stream_mode), the API will leverage output from previous frames to return smoother segmentation results.
We’ve also implemented a “RAW_SIZE_MASK” option to give developers more options for mask output. By default, the mask produced will be the same size as the input image. If the RAW_SIZE_MASK option is enabled, then the mask will be the size of the model output (256x256). This option makes it easier to apply customized rescaling logic or reduces latency if rescaling to the input image size is not needed for your use case.
Pose Detection Update

(Example of updated Pose Detection API; colors represent the Z value)
Last month, we updated our state-of-the-art Pose Detection API with a new model and new features. A quick summary of the enhancements is listed below:
- More poses added The API now recognizes more poses, targeting fitness and yoga use cases, especially when a user is directly facing the camera.
- 50% size reduction The base and accurate pose models are now significantly smaller. This change does not impact the quality of the models.
- Z Coordinate for depth analysis The API now outputs a depth coordinate Z to help determine whether parts of the user's body are in front or behind the user’s hips.
Z Coordinate
The Z Coordinate is an experimental feature that is calculated for every point (excluding the face). The estimate is provided using synthetic data, obtained via the GHUM model (articulated 3D human shape model).
It is measured in "image pixels" like the X and Y coordinates. The Z axis is perpendicular to the camera and passes between a subject's hips. The origin of the Z axis is approximately the center point between the hips (left/right and front/back relative to the camera). Negative Z values are towards the camera; positive values are away from it. The Z coordinate does not have an upper or lower bound.
For more information on the Pose Detection changes, please see our API documentation.
Pose Classification
After the release of Pose Detection, we’ve received quite a bit of requests from developers to help with classifying specific poses within their apps. To help tackle this problem, we partnered with the MediaPipe team to release a pose classification tutorial and Google Colab. In the classification tutorial, we demonstrate how to build and run a custom pose classifier within the ML Kit Android sample app and also demo a simple push-up and squat rep counter using the classifier.

(Example of Pose classification and repetition counting with MLKit Pose)
For a deep dive into building your own pose classifier with different camera angles, environment conditions, body shapes etc, please see the pose classification tutorial.
For more general classification tips, please see our Pose Classification Options page on the ML Kit website.
Beyond General Availability
It has been an exciting two years getting ML Kit to general availability and we couldn’t have gotten here without your help and feedback. As we continue to introduce new APIs such as Selfie Segmentation and Pose Detection, your feedback is more important than ever. Please continue to share your enhancement requests and questions with our development team or reach out through our community channels. Let’s build a smarter future together.