Clustering is a central problem in unsupervised machine learning (ML) with many applications across domains in both industry and academic research more broadly. At its core, clustering consists of the following problem: given a set of data elements, the goal is to partition the data elements into groups such that similar objects are in the same group, while dissimilar objects are in different groups. This problem has been studied in math, computer science, operations research and statistics for more than 60 years in its myriad variants. Two common forms of clustering are metric clustering, in which the elements are points in a metric space, like in the k-means problem, and graph clustering, where the elements are nodes of a graph whose edges represent similarity among them.
 |
| In the k-means clustering problem, we are given a set of points in a metric space with the objective to identify k representative points, called centers (here depicted as triangles), so as to minimize the sum of the squared distances from each point to its closest center. Source, rights: CC-BY-SA-4.0 |
{kind=link}
Despite the extensive literature on algorithm design for clustering, few practical works have focused on rigorously protecting the user's privacy during clustering. When clustering is applied to personal data (e.g., the queries a user has made), it is necessary to consider the privacy implications of using a clustering solution in a real system and how much information the output solution reveals about the input data.
To ensure privacy in a rigorous sense, one solution is to develop differentially private (DP) clustering algorithms. These algorithms ensure that the output of the clustering does not reveal private information about a specific data element (e.g., whether a user has made a given query) or sensitive data about the input graph (e.g., a relationship in a social network). Given the importance of privacy protections in unsupervised machine learning, in recent years Google has invested in research on theory and practice of differentially private metric or graph clustering, and differential privacy in a variety of contexts, e.g., heatmaps or tools to design DP algorithms.
Today we are excited to announce two important updates: 1) a new differentially-private algorithm for hierarchical graph clustering, which we’ll be presenting at ICML 2023, and 2) the open-source release of the code of a scalable differentially-private k-means algorithm. This code brings differentially private k-means clustering to large scale datasets using distributed computing. Here, we will also discuss our work on clustering technology for a recent launch in the health domain for informing public health authorities.
Differentially private hierarchical clustering
Hierarchical clustering is a popular clustering approach that consists of recursively partitioning a dataset into clusters at an increasingly finer granularity. A well known example of hierarchical clustering is the phylogenetic tree in biology in which all life on Earth is partitioned into finer and finer groups (e.g., kingdom, phylum, class, order, etc.). A hierarchical clustering algorithm receives as input a graph representing the similarity of entities and learns such recursive partitions in an unsupervised way. Yet at the time of our research no algorithm was known to compute hierarchical clustering of a graph with edge privacy, i.e., preserving the privacy of the vertex interactions.
In “Differentially-Private Hierarchical Clustering with Provable Approximation Guarantees”, we consider how well the problem can be approximated in a DP context and establish firm upper and lower bounds on the privacy guarantee. We design an approximation algorithm (the first of its kind) with a polynomial running time that achieves both an additive error that scales with the number of nodes n (of order n2.5) and a multiplicative approximation of O(log½ n), with the multiplicative error identical to the non-private setting. We further provide a new lower bound on the additive error (of order n2) for any private algorithm (irrespective of its running time) and provide an exponential-time algorithm that matches this lower bound. Moreover, our paper includes a beyond-worst-case analysis focusing on the hierarchical stochastic block model, a standard random graph model that exhibits a natural hierarchical clustering structure, and introduces a private algorithm that returns a solution with an additive cost over the optimum that is negligible for larger and larger graphs, again matching the non-private state-of-the-art approaches. We believe this work expands the understanding of privacy preserving algorithms on graph data and will enable new applications in such settings.
Large-scale differentially private clustering
We now switch gears and discuss our work for metric space clustering. Most prior work in DP metric clustering has focused on improving the approximation guarantees of the algorithms on the k-means objective, leaving scalability questions out of the picture. Indeed, it is not clear how efficient non-private algorithms such as k-means++ or k-means// can be made differentially private without sacrificing drastically either on the approximation guarantees or the scalability. On the other hand, both scalability and privacy are of primary importance at Google. For this reason, we recently published multiple papers that address the problem of designing efficient differentially private algorithms for clustering that can scale to massive datasets. Our goal is, moreover, to offer scalability to large scale input datasets, even when the target number of centers, k, is large.
We work in the massively parallel computation (MPC) model, which is a computation model representative of modern distributed computation architectures. The model consists of several machines, each holding only part of the input data, that work together with the goal of solving a global problem while minimizing the amount of communication between machines. We present a differentially private constant factor approximation algorithm for k-means that only requires a constant number of rounds of synchronization. Our algorithm builds upon our previous work on the problem (with code available here), which was the first differentially-private clustering algorithm with provable approximation guarantees that can work in the MPC model.
The DP constant factor approximation algorithm drastically improves on the previous work using a two phase approach. In an initial phase it computes a crude approximation to “seed” the second phase, which consists of a more sophisticated distributed algorithm. Equipped with the first-step approximation, the second phase relies on results from the Coreset literature to subsample a relevant set of input points and find a good differentially private clustering solution for the input points. We then prove that this solution generalizes with approximately the same guarantee to the entire input.
Vaccination search insights via DP clustering
We then apply these advances in differentially private clustering to real-world applications. One example is our application of our differentially-private clustering solution for publishing COVID vaccine-related queries, while providing strong privacy protections for the users.
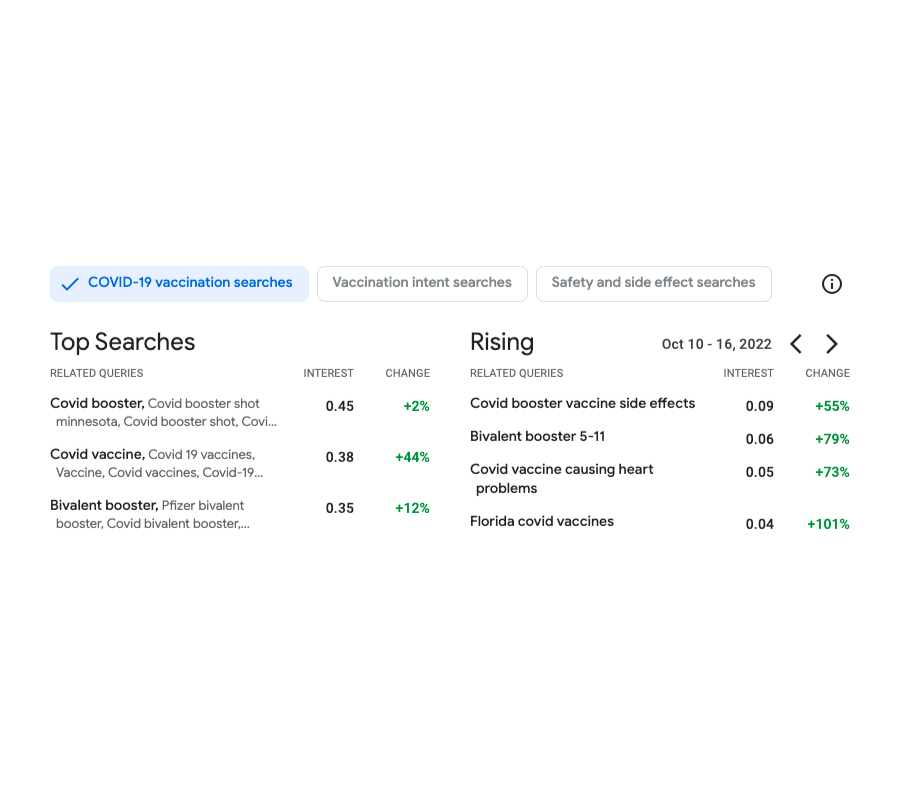
The goal of Vaccination Search Insights (VSI) is to help public health decision makers (health authorities, government agencies and nonprofits) identify and respond to communities' information needs regarding COVID vaccines. In order to achieve this, the tool allows users to explore at different geolocation granularities (zip-code, county and state level in the U.S.) the top themes searched by users regarding COVID queries. In particular, the tool visualizes statistics on trending queries rising in interest in a given locale and time.
 |
| Screenshot of the output of the tool. Displayed on the left, the top searches related to Covid vaccines during the period Oct 10-16 2022. On the right, the queries that have had rising importance during the same period and compared to the previous week. |
To better help identifying the themes of the trending searches, the tool clusters the search queries based on their semantic similarity. This is done by applying a custom-designed k-means–based algorithm run over search data that has been anonymized using the DP Gaussian mechanism to add noise and remove low-count queries (thus resulting in a differentially clustering). The method ensures strong differential privacy guarantees for the protection of the user data.
This tool provided fine-grained data on COVID vaccine perception in the population at unprecedented scales of granularity, something that is especially relevant to understand the needs of the marginalized communities disproportionately affected by COVID. This project highlights the impact of our investment in research in differential privacy, and unsupervised ML methods. We are looking to other important areas where we can apply these clustering techniques to help guide decision making around global health challenges, like search queries on climate change–related challenges such as air quality or extreme heat.
Acknowledgements
We thank our co-authors Silvio Lattanzi, Vahab Mirrokni, Andres Munoz Medina, Shyam Narayanan, David Saulpic, Chris Schwiegelshohn, Sergei Vassilvitskii, Peilin Zhong and our colleagues from the Health AI team that made the VSI launch possible Shailesh Bavadekar, Adam Boulanger, Tague Griffith, Mansi Kansal, Chaitanya Kamath, Akim Kumok, Yael Mayer, Tomer Shekel, Megan Shum, Charlotte Stanton, Mimi Sun, Swapnil Vispute, and Mark Young.
For more information on the Graph Mining team (part of Algorithm and Optimization) visit our pages.