
Googlebot will soon speak HTTP/2
Quick summary: Starting November 2020, Googlebot will start crawling some sites over HTTP/2.

Quick summary: Starting November 2020, Googlebot will start crawling some sites over HTTP/2.
Ever since mainstream browsers started supporting the next major revision of HTTP, HTTP/2 or h2 for short, web professionals asked us whether Googlebot can crawl over the upgraded, more modern version of the protocol.
Today we're announcing that starting mid November 2020, Googlebot will support crawling over HTTP/2 for select sites.
As we said, it's the next major version of HTTP, the protocol the internet primarily uses for transferring data. HTTP/2 is much more robust, efficient, and faster than its predecessor, due to its architecture and the features it implements for clients (for example, your browser) and servers. If you want to read more about it, we have a long article on the HTTP/2 topic on developers.google.com.
In general, we expect this change to make crawling more efficient in terms of server resource usage. With h2, Googlebot is able to open a single TCP connection to the server and efficiently transfer multiple files over it in parallel, instead of requiring multiple connections. The fewer connections open, the fewer resources the server and Googlebot have to spend on crawling.
In the first phase, we'll crawl a small number of sites over h2, and we'll ramp up gradually to more sites that may benefit from the initially supported features, like request multiplexing.
Googlebot decides which site to crawl over h2 based on whether the site supports h2, and whether the site and Googlebot would benefit from crawling over HTTP/2. If your server supports h2 and Googlebot already crawls a lot from your site, you may be already eligible for the connection upgrade, and you don't have to do anything.
If your server still only talks HTTP/1.1, that's also fine. There's no explicit drawback for crawling over this protocol; crawling will remain the same, quality and quantity wise.
Our preliminary tests showed no issues or negative impact on indexing, but we understand that, for various reasons, you may want to opt your site out from crawling over HTTP/2. You can do that by instructing the server to respond with a 421 HTTP status code when Googlebot attempts to crawl your site over h2. If that's not feasible at the moment, you can send a message to the Googlebot team (however, this solution is temporary).
If you have more questions about Googlebot and HTTP/2, check the questions we thought you might ask. If you can't find your question, write to us on Twitter and in the help forums.
Posted by Jin Liang and Gary
The software we use to enable Googlebot to crawl over h2 has matured enough that it can be used in production.
It's really up to you. However, we will only switch to crawling over h2 sites that support it and will clearly benefit from it. If there's no clear benefit for crawling over h2, Googlebot will still continue to crawl over h1.
Cloudflare has a blog post with a plethora of different methods to test whether a site supports h2, check it out!
This really depends on your server. We recommend talking to your server administrator or hosting provider.
You can't. If the site supports h2, it is eligible for being crawled over h2, but only if that would be beneficial for the site and Googlebot. If crawling over h2 would not result in noticeable resource savings for example, we would simply continue to crawl the site over HTTP/1.1.
In our evaluations we found little to no benefit for certain sites (for example, those with very low qps) when crawling over h2. Therefore we have decided to switch crawling to h2 only when there's clear benefit for the site. We'll continue to evaluate the performance gains and may change our criteria for switching in the future.
When a site becomes eligible for crawling over h2, the owners of that site registered in Search Console will get a message saying that some of the crawling traffic may be over h2 going forward. You can also check in your server logs (for example, in the access.log file if your site runs on Apache).
Googlebot supports most of the features introduced by h2. Some features like server push, which may be beneficial for rendering, are still being evaluated.
No. Your website must use HTTPS and support HTTP/2 in order to be eligible for crawling over HTTP/2. This is equivalent to how modern browsers handle it.
Application-layer protocol negotiation (ALPN) will only be used for sites that are opted in to crawling over h2, and the only accepted protocol for responses will be h2. If the server responds during the TLS handshake with a protocol version other than h2, Googlebot will back off and come back later on HTTP/1.1.
Some of the many, but most prominent benefits of h2 include:
If you want to know more about specific h2 features and their relation to crawling, ask us on Twitter.
The primary benefit of h2 is resource savings, both on the server side, and on Googlebot side. Whether we crawl using h1 or h2 does not affect how your site is indexed, and hence it does not affect how much we plan to crawl from your site.
No.
The first Virtual Webmaster Unconference successfully took place on August 26th and, as promised, we’d like to share the main findings and conclusions here.
As communicated before, this event was a pilot, in which we wanted to test a) if there was an appetite for a very different type of event, and b) whether the community would actively engage in the discussions.
To the first question, we were overwhelmed with the interest to participate; it definitely exceeded our expectations and it gives us fuel to try out future iterations. Despite the frustration of many, who did not receive an invitation, we purposefully kept the event small. This brings us to our second point: it is by creating smaller venues that discussions can happen comfortably. Larger audiences are perfect for more conventional conferences, with keynotes and panels. The Virtual Webmaster Unconference, however, was created to hear the attendees’ voices. And we did.
In total, there were 17 sessions. We divided them into two blocks: half of them ran simultaneously on block 1, the other half on block 2. There were many good discussions and, while some teams took on a few suggestions from the community to improve their products and features, others used the session to bounce off ideas and for knowledge sharing.
What were the biggest realizations for our internal teams?
Core Web Vitals came up several times during the sessions. The teams realized that they still feel rather new to users, and that people are still getting used to them. Also, although Google has provided resources on them, many users still find them hard to understand and would like additional Google help docs for non-savvy users. Also, the Discover session shared its most recent documentation update.
The topic of findability of Google help docs was also a concern. Attendees mentioned that it should be easier for people to find the official search docs, in a more centralized way, especially for beginner users who aren't always sure what to search for.
Great feedback came out from the Search Console brainstorming session, around what features work very well (like the monthly performance emails) and others that don’t work as well for Search Console users (such as messaging cadence).
The Site Kit for WordPress session showed that users were confused about data discrepancies they see between Analytics and Search console. The Structured Data team realized that they still have to focus on clarifying some confusion between the Rich Results Test and the Structured Data Testing Tool.
The e-commerce session concluded that there is a lot of concern around the heavy competition that small businesses face in the online retail space. To get an edge over large retailers and marketplaces, e-commerce stores could try to focus their efforts on a single niche, thus driving all their ranking signals towards that specific topic. Additionally, small shops have the opportunity to add additional unique value through providing expertise, for example, by creating informative content on product-related topics and thus increasing relevance and trustworthiness for both their audience and Google.
What are the main technical findings for attendees?
The Java Script Issues session concluded that 3rd party script creep is an issue for developers. Also, during the session Fun with Scripts!, attendees saw how scripts can take data sets and turn them into actionable insights. Some of the resources shared were: Code Labs, best place to learn something quickly; Data Studio, if you’re interested in app scripts or building your own connector; a starting point to get inspired: https://developers.google.com/apps-script/guides/videos
Some myths were also busted...
There were sessions that busted some popular beliefs. For example, there is no inherent ranking advantage from mobile first indexing and making a site technically better doesn't mean that it's actually better, since the content is key.
The Ads and SEO Mythbusting session was able to bust the following false statements:
1) Ads that run on Google Ads rank higher & Sites that run Google Ads rank better (False)
2) Ads from other companies causing low dwell time/high bounce lower your Ranking (False)
3) Ads vs no ads on site affects SEO (False)
As we mentioned previously, the event was met with overwhelmingly positive responses from the community - we see there is a need and a format to make meaningful conversations between Googlers and the community happen, so we're happy to say: We will repeat this in the future!
Based on the feedback we got from you all, we are currently exploring options in terms of how we will run the future events in terms of timezones, languages and frequency. We've learned a lot from the pilot event and we're using these learnings to make the future Virtual Webmaster Unconference even more accessible and enjoyable.
On top of working on the next editions of this event format, we heard your voice and we will have more information about an online Webmaster Conference (the usual format) very soon, as well as other topics. In order to stay informed, make sure you follow us on Twitter, YouTube and this Blog so that you don’t miss any updates on future events or other news.
Thanks again for your fantastic support!
For the last few years, we’ve collaborated with the image licensing industry to raise awareness of licensing requirements for content found through Google Images. In 2018, we began supporting IPTC Image Rights metadata; in February 2020 we announced a new metadata framework through Schema.org and IPTC for licensable images. Since then, we’ve seen widespread adoption of this new standard by websites, image platforms and agencies of all sizes. Today, we’re launching new features on Google Images which will highlight licensing information for images, and make it easier for users to understand how to use images responsibly.
Images that include licensing information will be labeled with a “Licensable” badge on the results page. When a user opens the image viewer (the window that appears when they select an image), we will show a link to the license details and/or terms page provided by the content owner or licensor. If available, we’ll also show an additional link that directs users to a page from the content owner or licensor where the user can acquire the image.

We’re also making it easier to find images with licensing metadata. We’ve enhanced the usage rights drop-down menu in Google Images to support filtering for Creative Commons licenses, as well as those that have commercial or other licenses.

We believe this is a step towards helping people better understand the nature of the content they’re looking at on Google Images and how they can use it responsibly.
To learn more about these features, how you can implement them and troubleshoot issues, visit the Google developer help page and our common FAQs page.
To provide feedback on these features, please use the feedback tools available on the developer page for the licensable images features, the Google Webmaster Forum, and stay tuned for upcoming virtual office hours where we will review common questions.
“A collaboration between Google and CEPIC, which started some four years ago, has ensured that authors and rights holders are identified on Google Images. Now, the last link of the chain, determining which images are licensable, has been implemented thanks to our fruitful collaboration with Google. We are thrilled at the window of opportunities that are opening up for photography agencies and the wider image industry due to this collaboration. Thanks, Google.”
- Alfonso Gutierrez, President of CEPIC
“As a result of a multi-year collaboration between IPTC and Google, when an image containing embedded IPTC Photo Metadata is re-used on a popular website, Google Images will now direct an interested user back to the supplier of the image,” said Michael Steidl, Lead of the IPTC Photo Metadata Working Group. “This is a huge benefit for image suppliers and an incentive to add IPTC metadata to image files.”
- Michael Steidl, Lead of the IPTC Photo Metadata Working Group
“Google's licensable image features are a great step forward in making it easier for users to quickly identify and license visual content. Google has worked closely with DMLA and its members during the features' development, sharing tools and details while simultaneously gathering feedback and addressing our members' questions or concerns. We look forward to continuing this collaboration as the features deploy globally.”
- Leslie Hughes, President of the Digital Media Licensing Association
“We live in a dynamic and changing media landscape where imagery is an integral component of online storytelling and communication for more and more people. This means that it is crucial that people understand the importance of licensing their images from proper sources for their own protection, and to ensure the investment required to create these images continues. We are hopeful Google’s approach will bring more visibility to the intrinsic value of licensed images and the rights required to use them.”
- Ken Mainardis, SVP, Content, Getty Images & iStock by Getty Images
“With Google’s licensable images features, users can now find high-quality images on Google Images and more easily navigate to purchase or license images in accordance with the image copyright. This is a significant milestone for the professional photography industry, in that it's now easier for users to identify images that they can acquire safely and responsibly. EyeEm was founded on the idea that technology will revolutionise the way companies find and buy images. Hence, we were thrilled to participate in Google’s licensable images project from the very beginning, and are now more than excited to see these features being released."
- Ramzi Rizk, Co-founder, EyeEm
"As the world's largest network of professional providers and users of digital images, we at picturemaxx welcome Google's licensable images features. For our customers as creators and rights managers, not only is the visibility in a search engine very important, but also the display of copyright and licensing information. To take advantage of this feature, picturemaxx will be making it possible for customers to provide their images for Google Images in the near future. The developments are already under way."
- Marcin Czyzewski, CTO, picturemaxx
“Google has consulted and collaborated closely with Alamy and other key figures in the photo industry on this project. Licensable tags will reduce confusion for consumers and help inform the wider public of the value of high quality creative and editorial images.”
- James Hall, Product Director, Alamy
“Google Images’ new features help both image creators and image consumers by bringing visibility to how creators' content can be licensed properly. We are pleased to have worked closely with Google on this feature, by advocating for protections that result in fair compensation for our global community of over 1 million contributors. In developing this feature, Google has clearly demonstrated its commitment to supporting the content creation ecosystem.
- Paul Brennan, VP of Content Operations, Shutterstock
"Google Images’ new licensable images features will provide expanded options for creative teams to discover unique content. By establishing Google Images as a reliable way to identify licensable content, Google will drive discovery opportunities for all agencies and independent photographers, creating an efficient process to quickly find and acquire the most relevant, licensable content."
- Andrew Fingerman, CEO of PhotoShelter
Earlier this year Google launched a new way for shoppers to find clothes, shoes and other retail products on Search in the U.S. and recently announced that free retail listings are coming to product knowledge panels on Google Search. These new types of experiences on Google Search, along with the global availability of rich results for products, enable retailers to make information about their products visible to millions of Google users, for free.
The best way for retailers and brands to participate in this experience is by annotating the product information on their websites using schema.org markup or by submitting this information directly to Google Merchant Center. Retailers can refer to our documentation to learn more about showing products for free on surfaces across Google or adding schema.org markup to a website.
While the processes above are the best way to ensure that product information will appear in this Search experience, Google may also include content that has not been marked up using schema.org or submitted through Merchant Center when the content has been crawled and is related to retail. Google does this to ensure that users see a wide variety of products from a broad group of retailers when they search for information on Google.
While we believe that this approach positively benefits the retail ecosystem, we recognize that some retailers may prefer to control how their product information appears in this experience. This can be done by using existing mechanisms for Google Search, as covered below.
There are a number of ways that retailers can control what data is displayed on Google. These are consistent with changes announced last year that allow website owners and retailers specifically to provide preferences on which information from their website can be shown as a preview on Google. This is done through a set of robots meta tags and an HTML attribute.
Here are some ways you can implement these controls to limit your products and product data from being displayed on Google:
Using this meta tag you can specify that no snippet should be shown for this page in search results. It completely removes the textual, image and rich snippet for this page on Google and removes the page from any free listing experience.
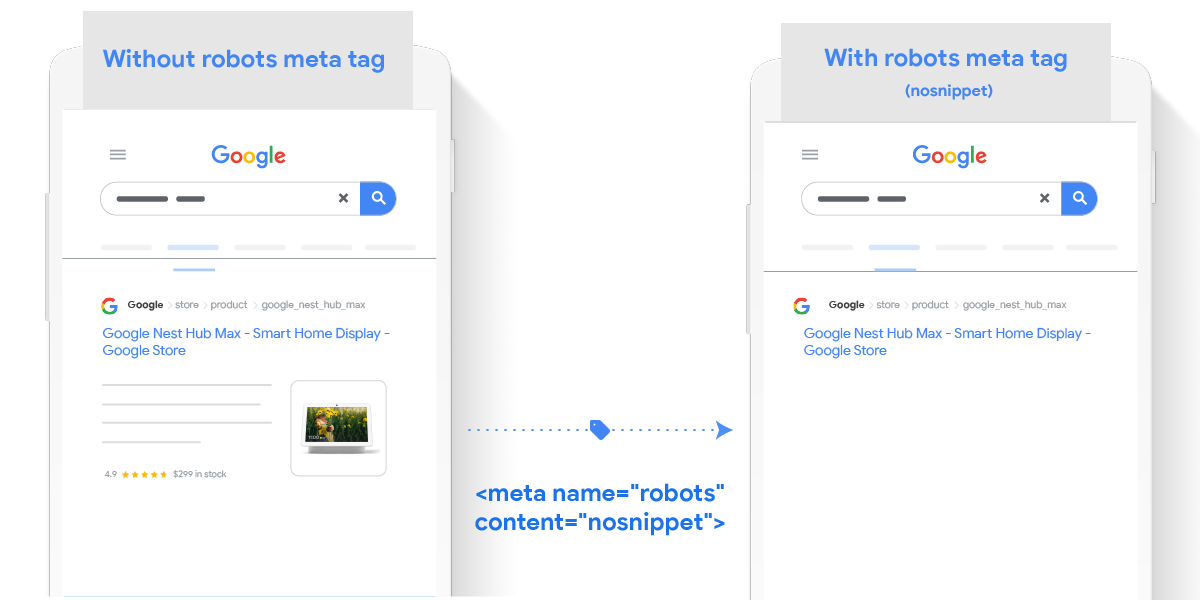
This meta tag allows you to specify a maximum snippet length, in characters, of a snippet for your page to be displayed on Google results. If the structured data (e.g. product name, description, price, availability) is greater than the maximum snippet length, the page will be removed from any free listing experience.
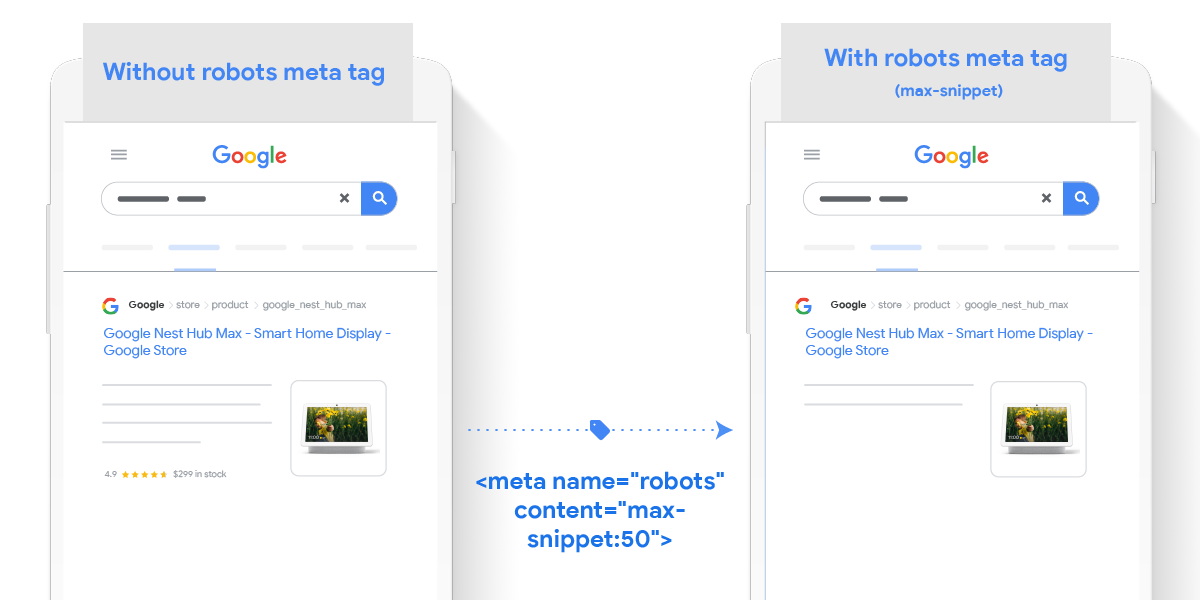
This meta tag allows you to specify a maximum size of image preview to be shown for images on this page, using either "none", "standard", or "large".

This attribute allows you to specify a section on your webpage that should not be included in a snippet preview on Google. When applied to relevant attributes for offers (price, availability, ratings, image) removes the textual, image and rich snippet for this page on Google and removes the listing from any free listing experiences.

Additional notes on these preferences:
The above preferences do not apply to information supplied via schema.org markup on the page itself. The schema.org markup needs to be removed first, before these opt-out mechanisms can become active.
The opt-out preferences do not apply to product data submitted through Google Merchant Center, which offers specific mechanisms to opt-out products from appearing on surfaces across Google.
Use of mechanisms like nosnippet and data-nosnippet only affect the display of data and eligibility for certain experiences. Display restrictions don’t affect the ranking of these pages in Search. The exclusion of some parts of product data from display may prevent the product from being shown in rich results and other product results on Google.
We hope these options make it easier for you to maximize the value you get from Search and achieve your business goals. These options are available to retailers worldwide and will operate the same for results we display globally. For more information, check out our developer documentation on meta tags.
Should you have any questions, feel free to reach out to us, or drop by our webmaster help forums.
Signed Exchanges (SXG) is a subset of the emerging family of specifications called Web Packaging, which enables publishers to safely make their content portable, while still keeping the publisher’s integrity and attribution. In 2019, Google Search started linking to signed AMP pages served from Google’s cache when available. This feature allows the content to be prefetched without loss of privacy, while attributing the content to the right origin.
Today we are happy to announce that sites implementing SXG for their AMP pages will be able to understand if there are any issues preventing Google from serving the SXG version of their page using the Google AMP Cache.
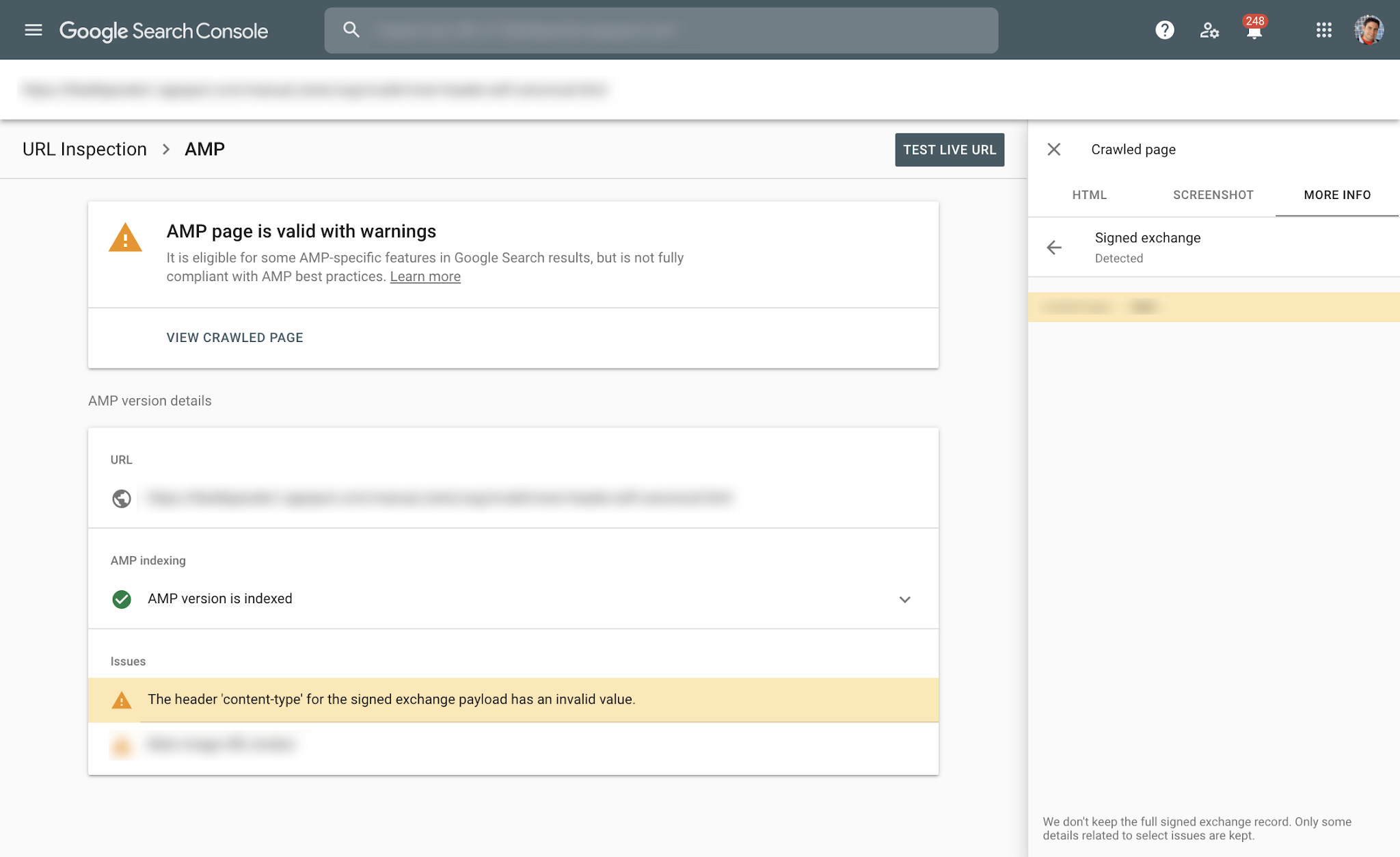
Use the AMP report to check if your site has any SXG related issues - look for issues with 'signed exchange' in their name. We will also send emails to alert you of new issues as we detect them.

To help with debugging and to verify a specific page is served using SXG, you can inspect a URL using the URL Inspection Tool to find if any SXG related issues appear on the AMP section of the analysis.
You can diagnose issues affecting the indexed version of the page or use the “live” option which will check validity for the live version currently served by your site.
To learn more about the types of SXG issues we can report on, check out this Help Center Article on SXG issues. If you have any questions, feel free to ask in the Webmasters community or the Google Webmasters Twitter handle.
Posted by Amir Rachum, Search Console Software Engineer & Jeffrey Jose, Google Search Product Manager.

While the in-person Webmaster Conference events are still on hold, we continue to share insights and information with you in the Webmaster Conference Lightning Talks series on our YouTube channel. But we understand that you might be missing the connection during live events, so we’d like to invite you to join a new event format: the first Virtual Webmaster Unconference, on August 26th, at 8AM PDT!
Because we want you to actively participate in the event, this is neither a normal Webmaster Conference nor a typical online conference. This event isn't just for you - it's your event. In particular, the word "Unconference" means that you get to choose which sessions you want to attend and become an active part of. You will shape the event by taking part in discussions, feedback sessions and similar formats that need your input.
It's your chance to collaborate with other webmasters, SEOs, developers, digital marketers, publishers and Google product teams, such as Search Console and Google Search, and help us to deliver more value to you and the community.
We have opened the registration for a few more spots in the event again. If you're seeing "registration is closed", the spots have filled up already. We may run more events in the future, so keep an eye on our Twitter feed and this blog.
As part of the registration process, we will ask you to select two sessions you would like to participate in. Only the sessions that receive the most votes will be scheduled to take place on the event day, so make sure you pick your favorite ones before August 19th!
As we have limited spots, we might have to select attendees based on background and demographics to get a good mix of perspectives in the event. We will let you know by August 20th if your registration is confirmed. Once your registration is confirmed, you will receive the invitation for the Google Meet call on August 26th with all the other participants, the MC and the session leads. You can expect to actively participate in the sessions you're interested in via voice and/or video call through Google Meet. Please note that the sessions will not be recorded; we will publish a blog post with some of the top learnings after the event.
A few weeks ago we held another Webmaster Conference Lightning Talk, this time about Rich Results and Search Console. During the talk we hosted a live chat and a lot of viewers asked questions - we tried to answer all we could, but our typing skills didn’t match the challenge… so we thought we’d follow up on the questions posed in this blog post.
If you missed the video, you can watch it below: it discusses how to get started with rich results and use Search Console to optimize your search appearance in Google Search.
Will a site rank higher against competitors if it implements structured data?
Structured data by itself is not a generic ranking factor. However, it can help Google to understand what the page is about, which can make it easier for us to show it where relevant and make it eligible for additional search experiences.
Which structured data would you recommend to use in Ecommerce category pages?
You don't need to mark up the products on a category page, a Product should only be marked up when they are the primary element on a page.
How much content should be included in my structured data? Can there be too much?
There is no limit to how much structured data you can implement on your pages, but make sure you’re sticking to the general guidelines. For example the markup should always be visible to users and representative of the main content of the page.
What exactly are FAQ clicks and impressions based on?
A Frequently Asked Question (FAQ) page contains a list of questions and answers pertaining to a particular topic. Properly marked up FAQ pages may be eligible to have a rich result on Search and an Action on the Google Assistant, which can help site owners reach the right users. These rich results include snippets with frequently asked questions, allowing users to expand and collapse answers to them. Every time such a result appears in Search results for an user it will be counted as an impression on Search Console, and if the user clicks to visit the website it will be counted as a click. Clicks to expand and collapse the search result will not be counted as clicks on Search Console as they do not lead the user to the website. You can check impressions and clicks on your FAQ rich results using the ‘Search appearance’ tab in the Search Performance report.
Will Google show rich results for reviews made by the review host site?
Reviews must not be written or provided by the business or content provider. According to our review snippets guidelines: “Ratings must be sourced directly from users” - publishing reviews written by the business itself are against the guidelines and might trigger a Manual Action.
There are schema types that are not used by Google, why should we use them?
Google supports a number of schema types, but other search engines can use different types to surface rich results, so you might want to implement it for them.
Why do rich results that previously appeared in Search sometimes disappear?
The Google algorithm tailors search results to create what it thinks is the best search experience for each user, depending on many variables, including search history, location, and device type. In some cases, it may determine that one feature is more appropriate than another, or even that a plain blue link is best. Check the Rich Results Status report, If you don’t see a drop in the number of valid items, or a spike in errors, your implementation should be fine.
How can I verify my dynamically generated structured data?
The safest way to check your structured data implementation is to inspect the URL on Search Console. This will provide information about Google's indexed version of a specific page. You can also use the Rich Results Test public tool to get a verdict. If you don’t see the structured data through those tools, your markup is not valid.
How can I add structured data in WordPress?
There are a number of WordPress plugins available that could help with adding structured data. Also check your theme settings, it might also support some types of markup.
With the deprecation of the Structured Data Testing Tool, will the Rich Results Test support structured data that is not supported by Google Search?
The Rich Results Test supports all structured data that triggers a rich result on Google Search, and as Google creates new experiences for more structured data types we’ll add support for them in this test. While we prepare to deprecate the Structured Data Testing Tool, we’ll be investigating how a generic tool can be supported outside of Google.
If you missed our previous lightning talks, check the WMConf Lightning Talk playlist. Also make sure to subscribe to our YouTube channel for more videos to come! We definitely recommend joining the premieres on YouTube to participate in the live chat and Q&A session for each episode!
Posted by Daniel Waisberg, Search Advocate
Over the past year, we have been working to upgrade the infrastructure of the Search Console API, and we are happy to let you know that we’re almost there. You might have already noticed some minor changes, but in general, our goal was to make the migration as invisible as possible. This change will help Google to improve the performance of the API as demand grows.
Note that if you’re not querying the API yourself you don't need to take action. If you are querying the API for your own data or if you maintain a tool which uses that data (e.g. a WordPress plugin), read on. Below is a summary of the changes:
Please note that other than these changes, the API is backward compatible and there are currently no changes in scope or functionality.
In the Google Cloud Console dashboards, you will notice a traffic drop for the legacy API and an increase in calls to the new one. This is the same API, just under the new name.
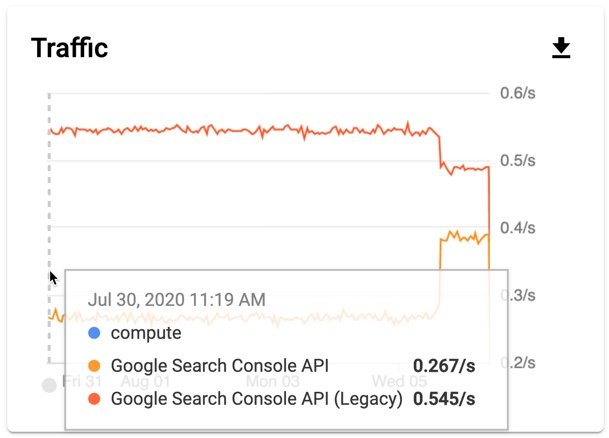 |
| Image: Search Console API changes in Google Cloud Console |
You can monitor your API usage on the new Google Search Console API page.
As mentioned in the introduction, these instructions are important only if you query the data yourself or provide a tool that does that for your users.
To check if you have an API restriction active on your API key, follow these steps in the credentials page and make sure the Search Console API is not restricted. If you have added an API restriction for your API keys you will need to take action by August 31.
In order to allow your API calls to be migrated automatically to the new API infrastructure, you need to make sure the Google Search Console API is not restricted.
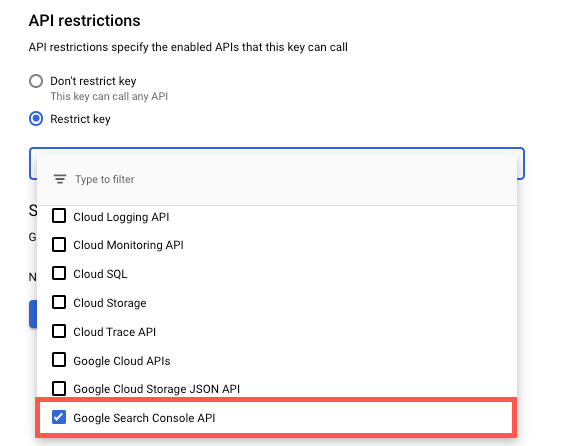 |
| Image: Google Search Console API restrictions setting |
If you’re querying the Search Console API using an external API library, or querying the Webmasters API discovery document directly you will need to take action as we’ll drop the support in the Webmasters discovery document. Our current plan is to support it until December 31, 2020 - but we’ll provide more details and guidance in the coming months.
If you have any questions, feel free to ask in the Webmasters community or the Google Webmasters Twitter handle.
Posted by Nati Yosephian, Search Console Software Engineer