By Grace Mollison, Cloud Solutions Architect
Google Cloud Platform (GCP) offers robust service account key management capabilities to help ensure that only authorized and properly authenticated entities can access resources running on GCP.
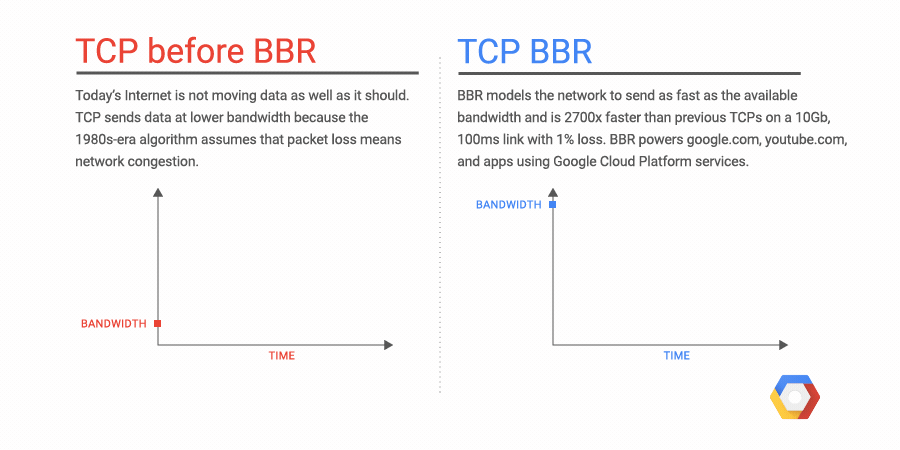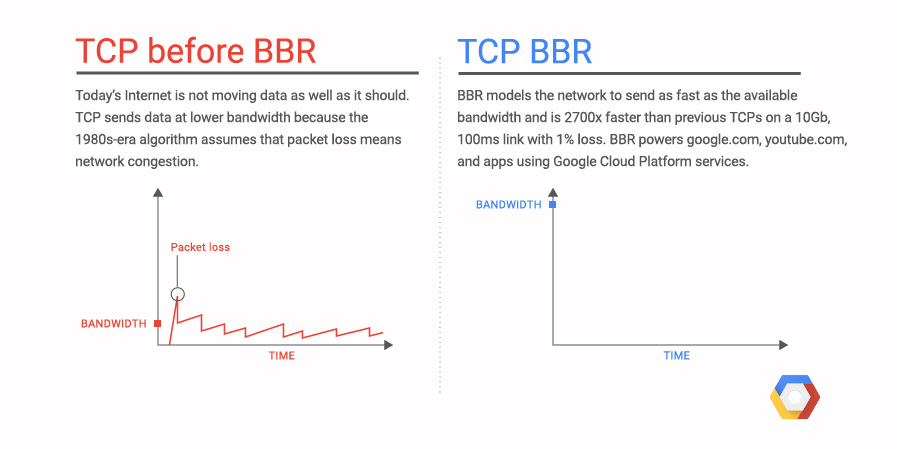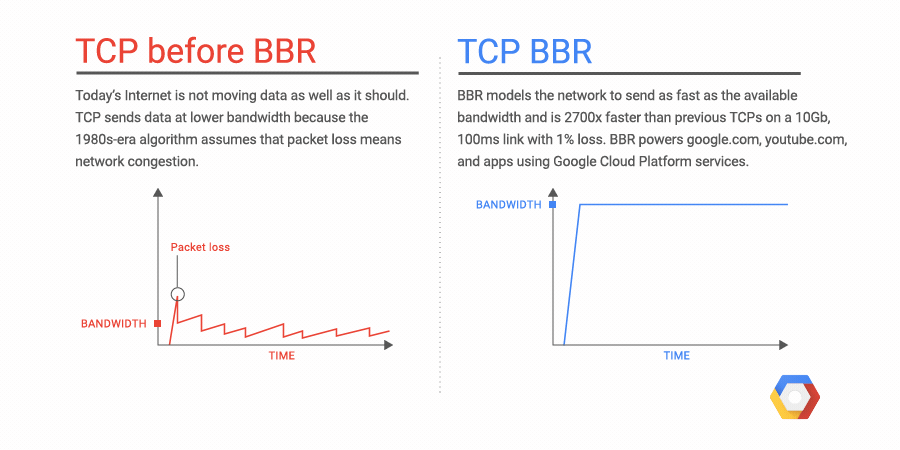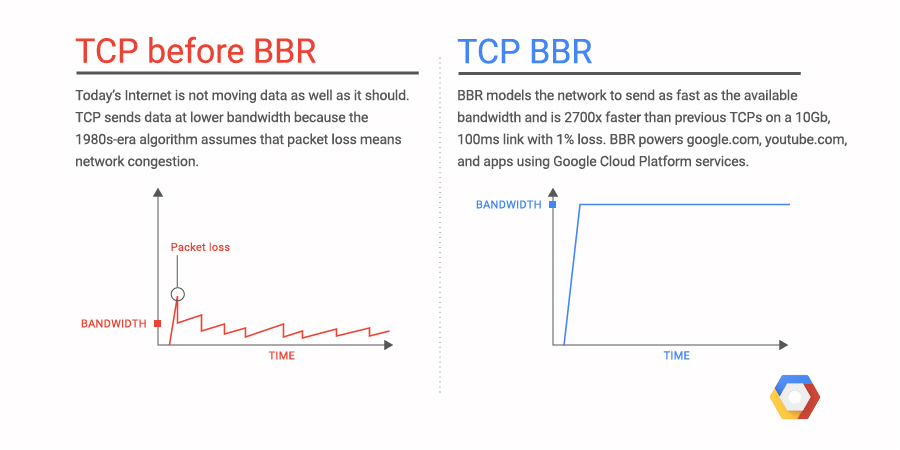
If an application runs entirely on GCP, managing service account keys is easy
— they never leave GCP, and GCP performs tasks like key rotation automatically. But many applications run on multiple environments
— local developer laptops, on-premises databases and even environments running in other public clouds. In that case, keeping keys safe can be tricky.
Ensuring that account keys aren’t exposed as they move across multiple environments is paramount to maintaining application security. Read on to learn about best practices you can follow when managing keys in a given application environment.
Introducing the service account
When using an application to access Cloud Platform APIs, we recommend you use a
service account, an identity whose credentials your application code can use to access other GCP services. You can access a service account from code running on GCP, in your on-premises environment or even another cloud.
If you’re running your code on GCP, setting up a service account is simple. In this example, we’ll use
Google Compute Engine as the target compute environment.
Now that you have a service account, you can launch instances to run from it. (Note: You can also temporarily stop an existing instance and
restart it with an alternative service account).
- Next, install the client library for the language in which your application is written. (You can also use the SDK but the client libraries are the most straightforward and recommended approach.) With this, your application can use the service account credentials to authenticate applications running on the instance. You don’t need to download any keys because you are using a Compute Engine instance, and we automatically create and rotate the keys.
Protecting service account keys outside GCP
If your application is running outside GCP, follow the steps outlined above, but install the client library on the destination virtual or physical machine. When creating the service account, make sure that you're following the principles of least-privilege. This is good practice in all cases, but it becomes even more important when you download credentials, as GCP no longer manages the key, increasing the risk of it being inadvertently exposed.
In addition, you’ll need to
create a new key pair for the service account, and download the private key (which is not retained by Google). Note that with external keys, you're responsible for security of the private key and other management operations such as key rotation.
Applications need to be able to use external keys to be authorized to call Google Cloud APIs. Using the Google API client libraries facilitates this. Google API client libraries use
Application Default Credentials for a simple way to get authorization credentials when they're called. When using an application outside of GCP, you can
authenticate using the service account for which the key was generated by pointing the GOOGLE_APPLICATION_CREDENTIALS environment variable to the location where you downloaded the key.
Best practices when downloading service account keys
Now you have a key that can gain access to GCP resources, you need to ensure that you
manage the key appropriately. The remainder of this post focuses on best practices to avoid exposing keys outside of their intended scope of use. Here are best practices to follow:
- If you’ve downloaded the key for local development, make sure it's not granted access to production resources.
- Rotate keys using the following IAM Service Account API methods:
- ServiceAccounts.keys.create()
- Replace old key with new key
- ServiceAccounts.keys.delete()
- Consider implementing a daily key rotation process and provide developers with a cloud storage bucket from which they can download the new key every day.
- Audit service accounts and keys using either the serviceAccount.keys.list() method or the Logs Viewer page in the console.
- Restrict who is granted the Service Account Actor and Service Account User role for a service account, as they will have full access to all the resources.
- Always use the client libraries and the GOOGLE_APPLICATION_CREDENTIALS for local development.
- Prevent developers from committing keys to external source code repositories.
- And finally, regularly scan external repositories for keys and take remedial action if any are located.
Now let’s look at ways to implement some of these best practices.
Key rotation
Keyrotator is a simple CLI tool written in Python that you can use as is, or as the basis for a service account rotation process. Run it as a cron job on an admin instance, say, at midnight, and write the new key to Cloud Storage for developers to download in the morning.
It's essential to control access to the Cloud Storage bucket that contains the keys. Here’s how:
- Create a dedicated project setup for shared resources.
- Create a bucket in the dedicated project; do NOT make it publicly accessible.
- Create a group for the developers who need to download the new daily key.
- Grant read access to the bucket using Cloud IAM by granting the storage.objectViewer role to your developer group for the project with the storage bucket.
If you wish to implement stronger controls, use the
Google Cloud Key Management Service to
manage secrets using Cloud Storage.
Prevent committing keys to external source code repositories
You should not need to keep any keys with your code, but accidents happen and keys may inadvertently get pushed out with your code.
One way to avoid this is not to use external repositories and put processes in place to prevent their use. GCP provides
private git repositories for this use case.
You can also put in place preventive measures to stop keys from being committed to your git repo. One open-source tool you can use is
git-secrets. This is configured as a git hook when installed
It runs automatically when you run the
‘git commit’ command.
You need to configure git-secrets to check for patterns that match service account keys. This is fairly straightforward to configure:
Here's a service account private key when downloaded as a JSON file:
{
"type": "service_account",
"project_id": "your-project-id",
"private_key_id": "randomsetofalphanumericcharacters",
"private_key": "-----BEGIN PRIVATE KEY-----\thisiswhereyourprivatekeyis\n-----END PRIVATE KEY-----\n",
"client_email": "[email protected]",
"client_id": "numberhere",
"auth_uri": "https://accounts.google.com/o/oauth2/auth",
"token_uri": "https://accounts.google.com/o/oauth2/token",
"auth_provider_x509_cert_url": "https://www.googleapis.com/oauth2/v1/certs",
"client_x509_cert_url": "https://www.googleapis.com/robot/v1/metadata/x509/keyname%40your-project-id.iam.gserviceaccount.com"
}
To locate any service account keys, look for patterns that match the key name such as ‘private_key_id’ and ‘private_key’. Then, to locate any service account files in the local git folder, add the following registered patterns:
git secrets --add 'private_key'
git secrets --add 'private_key_id'
Now, when you try to run ‘git commit’ and it detects the pattern, you'll receive an error message and be unable to do the commit unless mitigating action is taken.
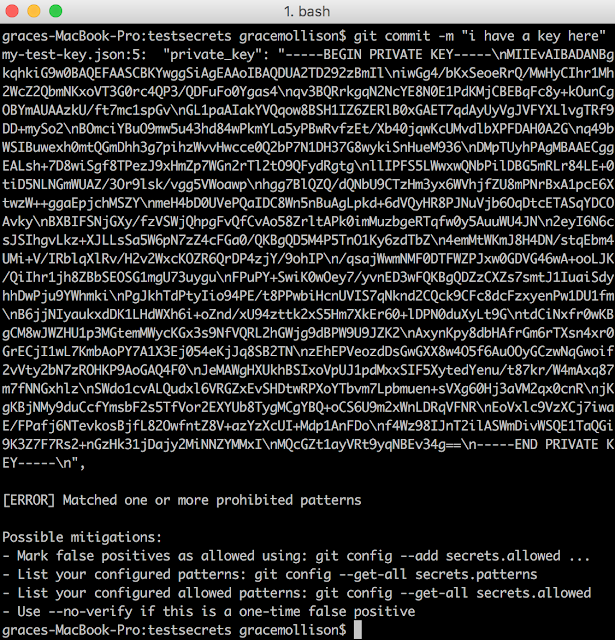 |
| This screenshot shows a (now deleted) key to illustrate what developers see when they try to commit files that may contain private details. |
Scan external repositories for keys
To supplement the use of git-secrets you can also run the open-source tool
trufflehog. Trufflehog searches a repo’s history for secrets by using entropy analysis (it uses
Shannon entropy) to find any keys that may have been uploaded.
Conclusion
In this post, we’ve shown you how to help secure service account keys, whether you're using them to authenticate applications running exclusively on GCP, in your local environment or in other clouds. Follow these best practices to avoid accidentally revealing keys and to control who can access your application resources. To learn more about authentication and authorization on GCP, check out our
Authentication Overview.