In Part 1 of this series on app discovery, we discussed using machine learning to gain a deeper understanding of the topics associated with an app, in order to provide a better search and discovery experience on the Google Play Apps Store. In this post, we discuss a deep learning framework to provide personalized recommendations to users based on their previous app downloads and the context in which they are used.
Providing useful and relevant app recommendations to visitors of the Google Play Apps Store is a key goal of our apps discovery team. An understanding of the topics associated with an app, however, is only one part of creating a system that best serves the user. In order to create a better overall experience, one must also take into account the tastes of the user and provide personalized recommendations. If one didn’t, the “You might also like” recommendation would look the same for everyone!
Discovering these nuances requires both an understanding what an app does, and also the context of the app with respect to the user. For example, to an avid sci-fi gamer, similar game recommendations may be of interest, but if a user installs a fitness app, recommending a health recipe app may be more relevant than five more fitness apps. As users may be more interested in downloading an app or game that complements one they already have installed, we provide recommendations based on app relatedness with each other (“You might also like”), in addition to providing recommendations based on the topic associated with an app (“Similar apps”).
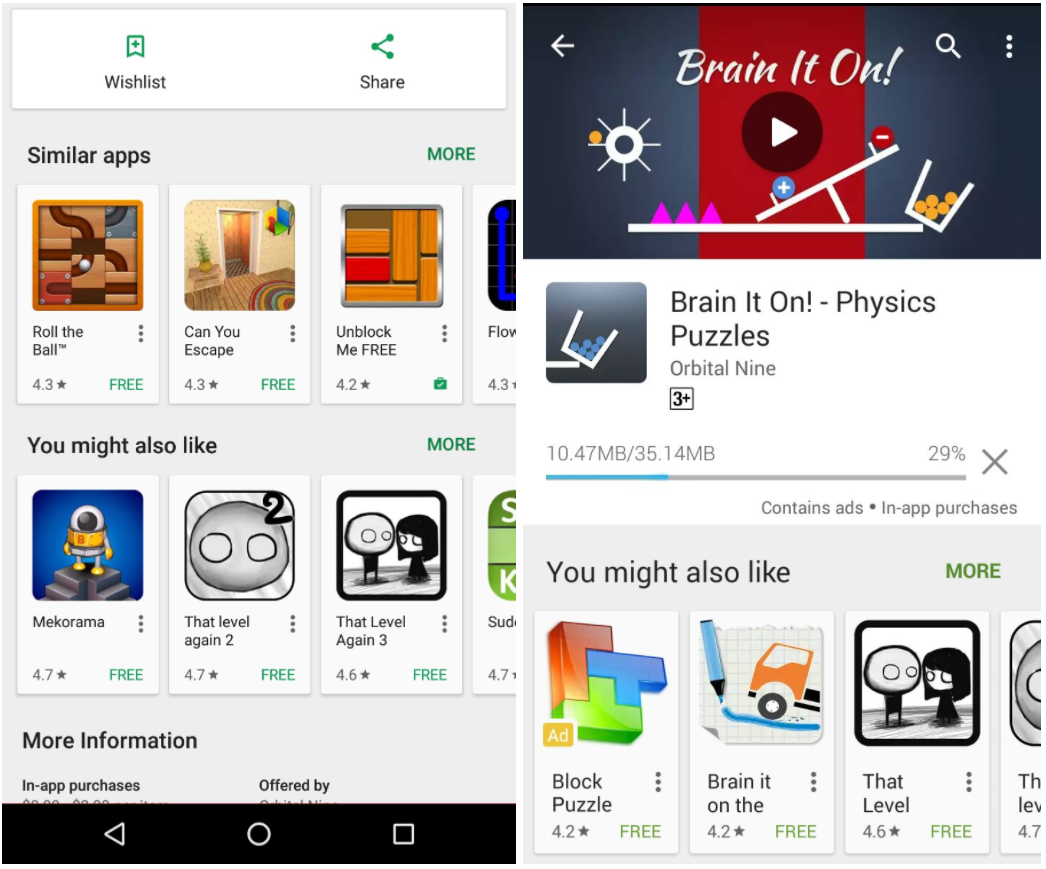 |
| Suggestions of similar apps and apps that you also might like shown both before making an install decision (left) and while the current install is in progress (right). |
One particularly strong contextual signal is app relatedness, based on previous installs and search query clicks. As an example, a user who has searched for and plays a lot of graphics-heavy games likely has a preference for apps which are also graphically intense rather than apps with simpler graphics. So, when this user installs a car racing game, the “You might also like” suggestions includes apps which relate to the “seed” app (because they are graphically intense racing games) ranked higher than racing apps with simpler graphics. This allows for a finer level of personalization where the characteristics of the apps are matched with the preferences of the user.
To incorporate this app relatedness in our recommendations, we take a two pronged approach: (a) offline candidate generation i.e. the generation of the potential related apps that other users have downloaded, in addition to the app in question, and (b) online personalized re-ranking, where we re-rank these candidates using a personalized ML model.
Offline Candidate Generation
The problem of finding related apps can be formulated as a nearest neighbor search problem. Given an app X, we want to find the k nearest apps. In the case of “you might also like”, a naive approach would be one based on counting, where if many people installed apps X and Y, then the app Y would be used as candidate for seed app X. However, this approach is intractable as it is difficult to learn and generalize effectively in the huge problem space. Given that there are over a million apps on Google Play, the total number of possible app pairs is over ~1012.
To solve this, we trained a deep neural network to predict the next app installed by the user given their previous installs. Output embeddings at the final layer of this deep neural network generally represents the types of apps a given user has installed. We then apply the nearest neighbor algorithm to find related apps for a given seed app in the trained embedding space. Thus, we perform dimensionality reduction by representing apps using embeddings to help prune the space of potential candidates.
Online Personalized Re-ranking
The candidates generated in the previous step represent relatedness along multiple dimensions. The objective is to assign scores to the candidates so they can be re-ranked in a personalized way, in order to provide an experience that is crafted to the user’s overall interests and yet maintain relevance for the user installing a given app. In order to do this, we take the characteristics of the app candidates as input to a separate deep neural network, which is then trained with real-time with user specific context features (region, language, app store search queries, etc.) to predict the likelihood of a related app being specifically relevant to the user.
 |
| Architecture for personalized related apps |
One of the takeaways from this work is that re-ranking content, like related apps, is one of the critical ways of app discovery in the store, and can bring great value to the user without impacting perceived relevance. Compared to the control (where no re-ranking was done), we saw a 20% increase in the app install rate from the “You might also like” suggestions. This had no user perceivable change in latency.
In Part 3 of this series, we will discuss how we employ machine learning to keep bad actors who try to manipulate the signals we use for search and personalization at bay.
Acknowledgements
This work was done within the Google Play team in collaboration with Halit Erdogan, Mark Taylor, Michael Watson, Huazhong Ning, Stan Bileschi, John Kraemer, and Chuan Yu Foo.
