By Tim Allclair, Software Engineer, Google Kubernetes Engine, and Maya Kaczorowski, Product Manager, Security & Privacy
Editor’s note: This is the seventh in a series of blog posts on container security at Google.
To conclude our blog series on container security, today’s post covers isolation, and when containers are appropriate for actually, well... containing. While containers bring great benefits to your development pipeline and provide some resource separation, they were not designed to provide a strong security boundary.
The fact is, there are some cases where you might want to run untrusted code in your environment. Untrusted code lives on a spectrum. On one end you have known bad malware that an engineer is trying to examine and reverse-engineer; and on the other end you might just have a third-party application or tool that you haven't audited yourself. Maybe it’s a project that historically had vulnerabilities and you aren’t quite ready to let it loose in your environment yet. In each of these cases, you don’t want the code to affect the security of your own workloads.
With that said, let’s take a look at what kind of security isolation containers do provide, and, in the event that it’s not enough, where to look for stronger isolation.
Hypervisors provide a security boundary for VMs
Traditionally, you might have put this untrusted code in its own virtual machine, relying on the security of the hypervisor to prevent processes from escaping or affecting other processes. A hypervisor provides a relatively strong security boundary—that is, we don’t expect code to be able to easily cross it by breaking out of a VM. At Google, we use the KVM hypervisor, and put
significant effort into ensuring its security.
The level of trust you require for your code is all relative. The more sensitive the data you process, the more you need to be able to trust the software that accesses it. You don’t treat code that doesn’t access user data (or other critical data) the same way you treat code that does—or that’s in the serving path of active user sessions, or that has root cluster access. In a perfect world, you access your most critical data with code you wrote, reviewed for security issues, and ran some security checks against (such as fuzzing). You then verify that all these checks passed before you deploy it. Of course, you may loosen these requirements based on where the code runs, or what it does—the same open-source tool might be insufficiently trusted in a hospital system to examine critical patient information, but sufficiently trusted in a test environment for a game app you’re developing in your spare time.
A ‘trust boundary’ is the point at which your code changes its level of trust (and hence its security requirements), and a ‘security boundary’ is how you enforce these trust boundaries. A security boundary is a set of controls, managed together across all surfaces, to prevent a process from one trust level from elevating its trust level and affecting more trusted processes or access other users’ data. A container is one such security boundary, albeit not a very strong one. This is because, compared to a hypervisor, a native OS container is a larger, more complex security boundary, with more potential vulnerabilities. On the other hand,
containers are meant to be run on a minimal OS, which limits the potential surface area for an attack at the OS level. At Google, we aim to protect all trust boundaries with at least two different security boundaries that each need to fail in order to cross a trust boundary.
Layers of isolation in Kubernetes
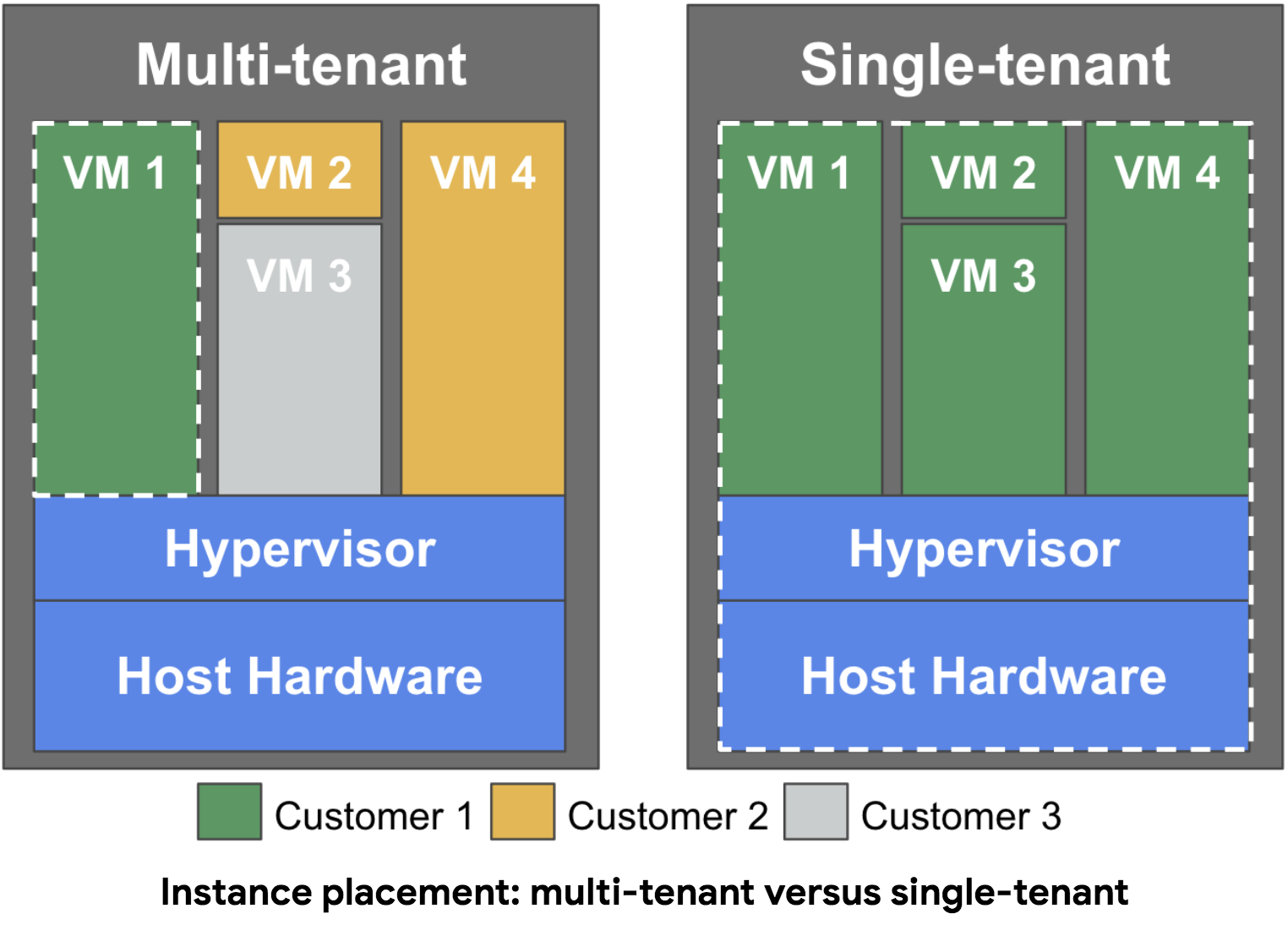
Kubernetes has several nested layers, each of which provides some level of isolation and security. Building on the container, Kubernetes layers provide progressively stronger isolation— you can start small and upgrade as needed. Starting from the smallest unit and moving outwards, here are the layers of a Kubernetes environment:
- Container (not specific to Kubernetes): A container provides basic management of resources, but does not isolate identity or the network, and can suffer from a noisy neighbor on the node for resources that are not isolated by cgroups. It provides some security isolation, but only provides a single layer, compared to our desired double layer.
- Pod: A pod is a collection of containers. A pod isolates a few more resources than a container, including the network. It does so with micro-segmentation using Kubernetes Network Policy, which dictates which pods can speak to one another. At the moment, a pod does not have a unique identity, but the Kubernetes community has made proposals to provide this. A pod still suffers from noisy neighbors on the same host.
- Node: This is a machine, either physical or virtual. A node includes a collection of pods, and has a superset of the privileges of those pods. A node leverages a hypervisor or hardware for isolation, including for its resources. Modern Kubernetes nodes run with distinct identities, and are authorized only to access the resources required by pods that are scheduled to the node. There can still be attacks at this level, such as convincing the scheduler to assign sensitive workloads to the node. You can use firewall rules to restrict network traffic to the node.
- Cluster: A cluster is a collection of nodes and a control plane. This is a management layer for your containers. Clusters offer stronger network isolation with per-cluster DNS.
- Project: A GCP project is a collection of resources, including Kubernetes Engine clusters. A project provides all of the above, plus some additional controls that are GCP-specific, like project-level IAM for Kubernetes Engine and org policies. Resource names, and other resource metadata, are visible up to this layer.
There’s also the
Kubernetes Namespace, the fundamental unit for authorization in Kubernetes. A namespace can contain multiple pods. Namespaces provide some control in terms of authorization, via namespace-level RBAC, but don’t try to control resource quota, network, or policies. Namespaces allow you to easily allocate resources to certain processes; these are meant to help you manage how you use your resources, not necessarily prevent a malicious process from escaping and accessing another process’ resources.
Diagram 1: Isolation provided by layer of Kubernetes
Recently, Google also announced the
open-source gVisor project, which provides stronger isolation at the pod level.
Sample scenario: Multi-tenant SaaS workload
In practice, it can be hard to decide what isolation requirements you should have for your workload, and how to enforce them—there isn’t a one-size-fits-all solution. Time to do a little threat modeling.
A common scenario we hear, is a developer building a multi-tenant SaaS application running in Kubernetes Engine, in order to help manage and scale their application as needed to meet demand. In this scenario, let’s say we have a SaaS application running its front-end and back-end on Kubernetes Engine, with a back-end database for transaction data, and a back-end database for payment data; plus some open-source code for critical functions such as DNS and secret management.
You might be worried about a noisy (or nosy!) neighbor—that someone else is monopolizing resources you need, and you’re unable to serve your app. Cryptomining is a trendy attack vector these days, and being able to stay up and running even if one part of your infrastructure is affected is important to you. In cases like these, you might want to isolate certain critical workloads at the node layer.
You might be worried about information leaking between your applications. Of course
Spacely Sprockets knows that you have other customers, but it shouldn’t be able to find out that
Cogswell’s Cogs is also using your application—they’re competitors. In this case, you might want to be careful with your naming, and take care to block access to unauthenticated node ports (with NetworkPolicy), or isolate at the cluster level.
You might also be concerned that critical data, like customer payment data, is sufficiently segmented from access by less trusted workloads. Customer payment data should require different trust levels to access than user-submitted jobs. In this case, you might want to isolate at the cluster level, or run these each in their own sandbox.
So all together, you might have your entire application running in a single project, with different clusters for each environment, and place any highly trusted workload in its own cluster. In addition, you’ll need to make careful resource sharing decisions at the node and pod layers to isolate different customers.
Another common multi-tenant scenario we hear is one where you’re running entirely untrusted code. For example, your users may give you arbitrary code that you run on their behalf. In this case, for a multi-tenant cluster you'll want to investigate sandboxing solutions.
In the end
If you’ve learned one thing from this blog post, it’s that there’s no one right way to configure a Kubernetes environment—the right security isolation settings depend on what you are running, where, who is accessing the data, and how. We hope you enjoyed this
series on container security! And while this is the last installment, you can look forward to more information about security best practices, as we continue to make Google Cloud, including Kubernetes Engine, the best place to run containers.