Over 1 billion people use YouTube, watching hundreds of millions of hours of content all over the world everyday. We have been receiving content at a rate exceeding 100 hours/min for the last three years (currently at 400 hours/min). With those kinds of usage statistics what we see on ingest actually says something about the state of video technology today.
Video files are the currency of video sharing and distribution over the web. Each file contains the video and audio data wrapped up in some container format and associated with metadata that describes the nature of the content in some way. To make sure each user can “Broadcast yourself” we have spent years building systems that can faithfully extract the video and audio data hidden inside almost any kind of file you can imagine. That is why when our users upload to YouTube they have confidence that their video and audio will always appear.
The video and audio data is typically compressed using a codec and of course the data itself comes in a variety of resolutions, frame rates, sample rates and channels (in the case of audio). As technology evolves, codecs get better, and the nature of the data itself changes, typically toward higher fidelity. But how much variety is there in this landscape and how has that variety changed with time? We’ve been analyzing the anatomy of files you’ve been uploading over the years and think it reflects how video technology has changed.
Audio/video file anatomyAudio/video files contain audio and video media which can be played or viewed on some multimedia devices like a TV or desktop or smartphone. Each pixel of video data is associated with values for brightness and color which tells the display how that pixel should appear. A quick calculation on the data rate for the raw video data shows that for 720p video at 30 frames per second the data rate is in excess of 420 Mbits/sec. Raw audio data rates are smaller but still significant at about 1.5 MBits/sec for 44.1 KHz sampling with 16 bits per sample. These rates are well in excess of the 10’s of MBits/sec (at most) that many consumers have today. By using compression technology that same > 400 MBits/sec of data can be expressed in less than 5 Mbits/sec. This means that audio and video compression is a vital part of any practical media distribution system. Without compression we would not be able to stream media over the internet in the way everyone enjoys now.
There are three main components of media files today: the container, the compressed bitstream itself and finally metadata. The bitstream (called the video and audio “essence”) contains the actual audio and video media in a compressed form. It will also contain information about the size of the pictures and start and end of frames so that the codec knows how to decode the picture data in the right way. This information embedded in the bitstream is still not enough though. The “container” refers to the additional information that helps the decoder work out when a video frame is to be played, and when the audio data should be played relative to the frame. The container often also holds an index to the start of certain frames in the bitstream. This makes it easier for a player system to allow users to “seek” or “fast forward” through the contents. The container will also hold information about the file content itself like the author, and other kinds of “metadata” that could be useful for a rights holder or “menu” on a player for instance. So the bitstream contains the actual picture and audio, but the container lets the player know how that content should be played.
Standardization of containers and codecs was vital for the digital video industry to take off as it did in the late 1990s. The Motion Picture Experts Group (MPEG) was the consortium responsible and they are still active today. The interaction between containers and codecs has been so tight in the past that quite often the container and the codec might have the same name, because they arise from the same standards document. Needless to say, there are many different standards for the various components in a media file. Today we have MPEG and the Alliance for Open Media (AOM) emerging as the two major bodies engaged in creating new media compression and distribution technology. This is what makes the job of YouTube so challenging. We must correctly decode your content despite the endless variety, and despite the frequent errors and missing component in uploaded files. We deal with thousands of combinations of containers and codecs every week.
ContainersThe plot below shows the percentage of files uploaded having the same container month on month over the last five years. Each container is associated with the same color over time. The legend is ordered from the bottom up. The container type used in the largest fraction of uploads is at the bottom.
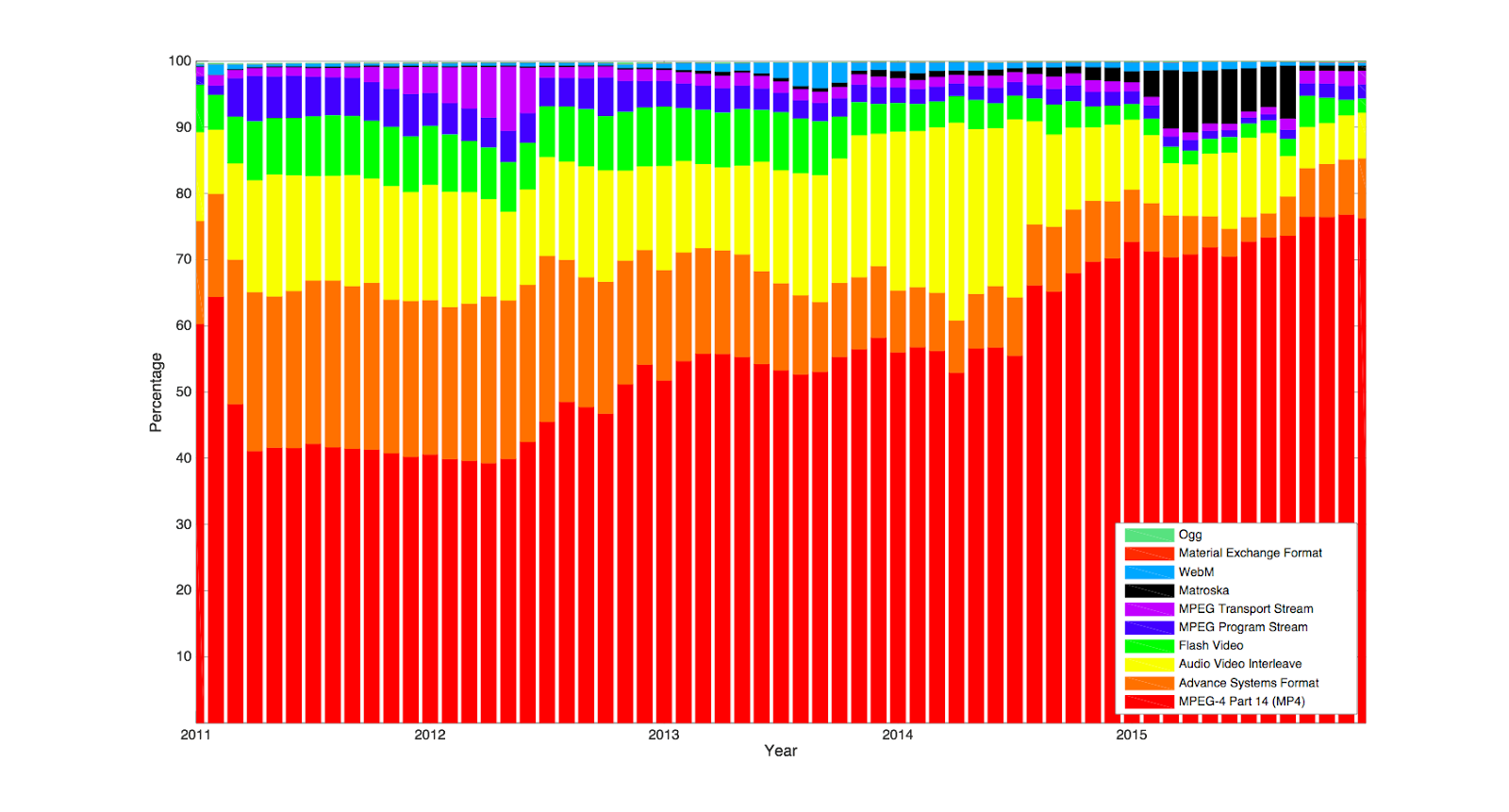
In 2011, MP4 (.mp4), Audio Video Interleave (.avi), Flash Video (.flv), Advanced Systems Format (.asf) and MPEG Transport Stream (.ts) were more equally distributed than they are now. But over the years MP4 has overtaken them all to become the most common ingest container format. Open source formats like WebM and Matroska seem to have been slowly gaining in popularity since about 2012, which is when we started rolling out the open source VP9 codec. Windows Media files (using the .asf container) and Flash Video have declined significantly. On the other end of the scale, files using Creative Labs video containers (for instance), which were popular before 2011, are hardly ever seen in our ingest today.
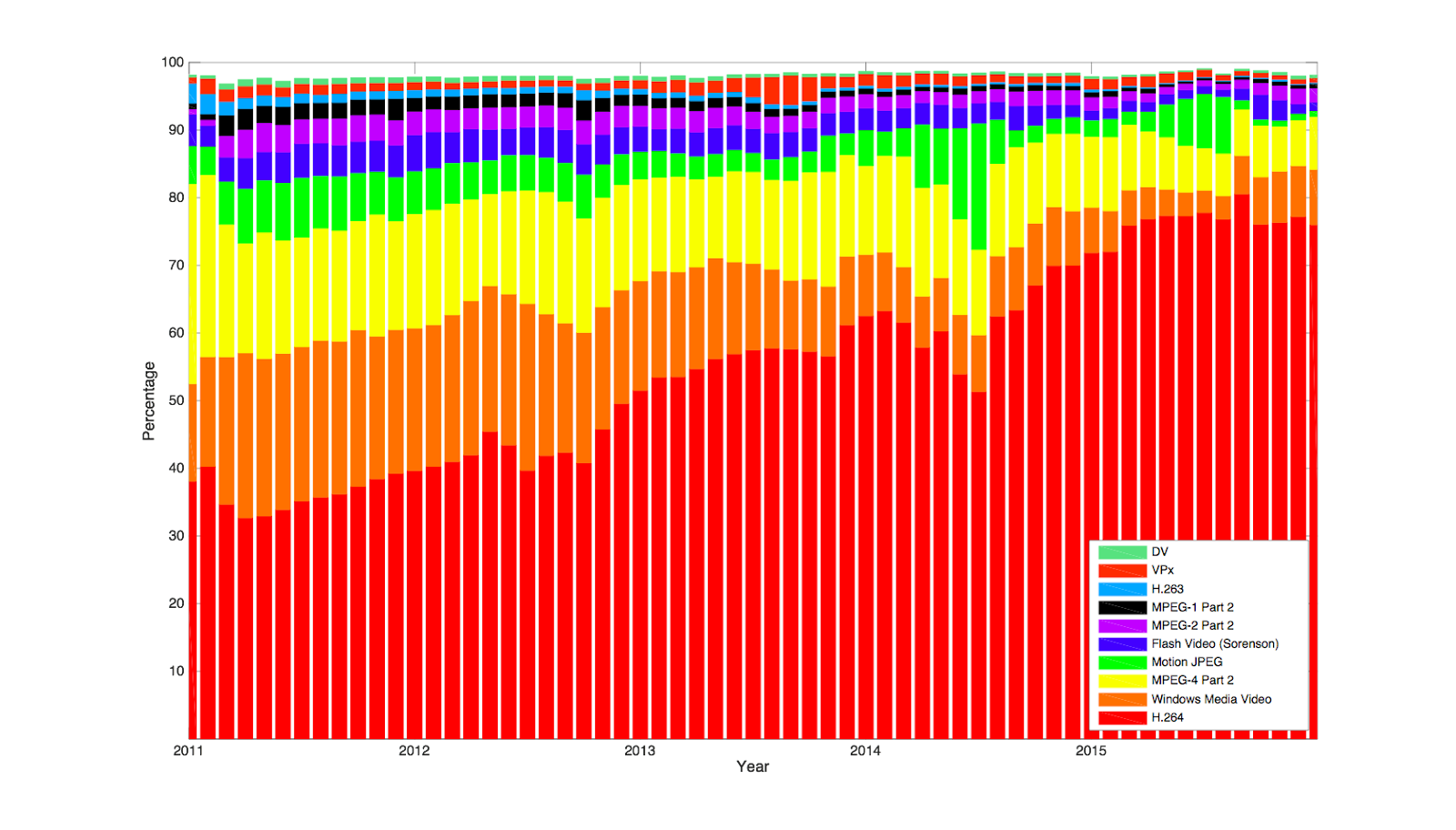
CodecsThe history of ingested codec types reflects the speed with which new codecs are adopted by hardware manufacturers and the makers of software editing and conforming systems. The chart below looks at the top ten video codecs back in 2011 and reveals how they have fared since then in our ingest profile. The VP range of codecs (VP6 - VP8) do still figure in our ingest today and in fact compared to 2011, VP8 ranks seventh in our top ten in 2015. Clearly H.264 is the dominant codec we see in use for upload to YouTube now, but MPEG4 and Windows Media bitstreams are still significant. This is very different from the situation in 2011 when almost every codec had a significant share of our ingest profile. This reflects how heterogeneous the video compression landscape was five years ago, with no dominant compression technology. The chart shows how rapidly the ecosystem moves to adopt a compression technology as soon as it proves itself: just five years. Uploads from mobile devices have also driven this trend as efficient codec technology enables more uploads from low power devices with low bandwidth availability. In that time we have seen the almost complete erosion of Flash Video (FLV) and MPEG1/2 video for upload to YouTube, which all appear to have reached some kind of low volume steady state behavior in our ingest.
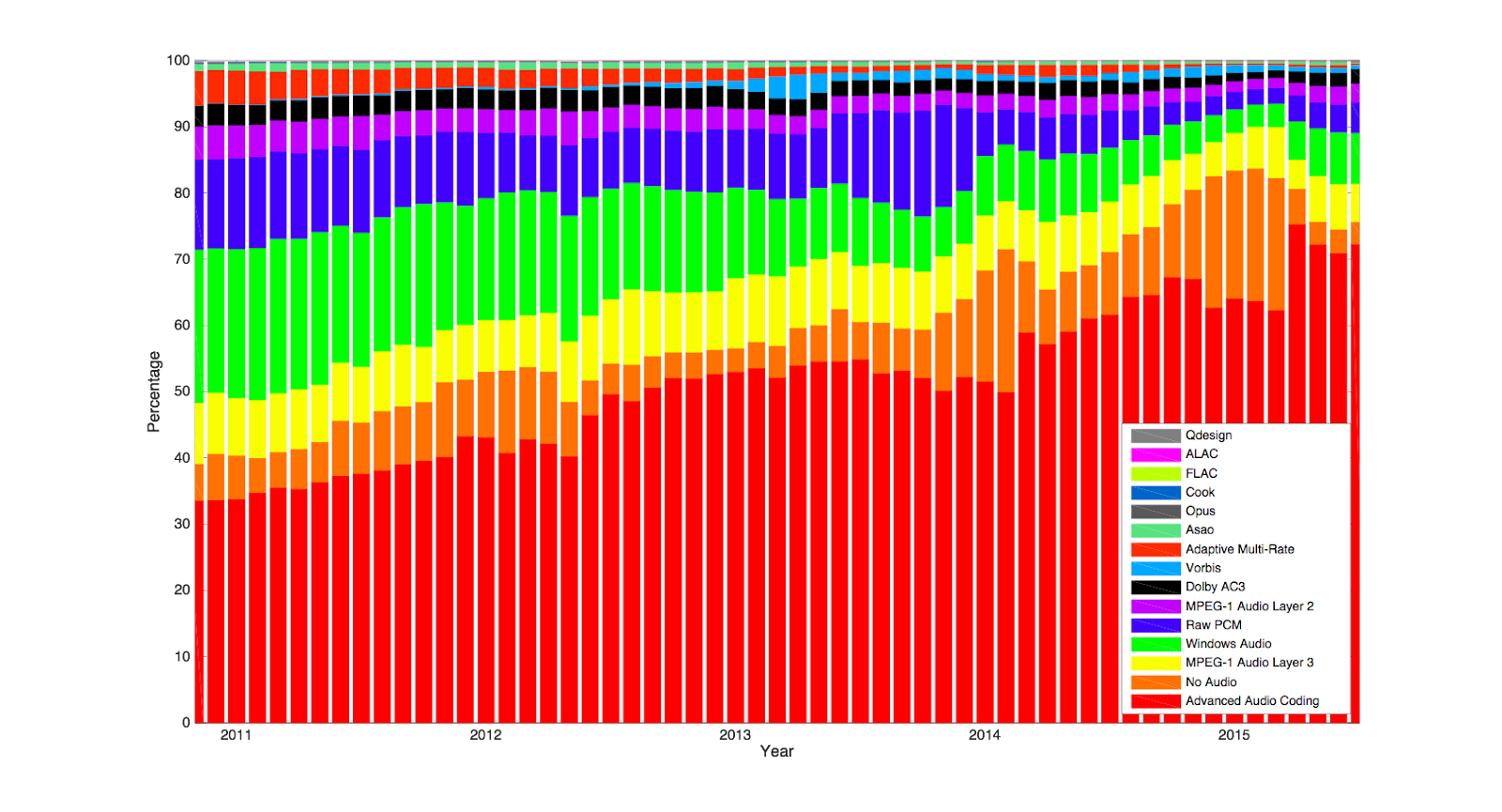
The situation with audio codecs follows similar trends. The chart below shows the top 15 codecs we see on ingest, measured over 2015. Five years ago we saw a very heterogeneous landscape with Raw audio data (PCM), Windows Media (WMA), MPEG and Advanced Audio (AAC) all contributing significant proportions. Over the intervening time the AAC codec has grown to dominate the profile of audio codecs, but PCM, WMA and MP3 are still significant. It's interesting that we see a pretty steady rate of media with no audio at all (shown as “No Audio”), although the total proportion is of course small. The use of the VORBIS open source audio codec got a boost in 2012 when the new version was released. Although it is hard to see from the chart, OPUS follows a similar pattern with uploads starting to kick off in late 2012 once the reference software was available and then a boost in uploads in 2013 coinciding with the next API release.
PropertiesBut what about the nature of video and audio media itself? Is there evidence to show that capture is increasing in resolution and color fidelity? This section reinforces the law that “in the internet everything gets bigger with time.”
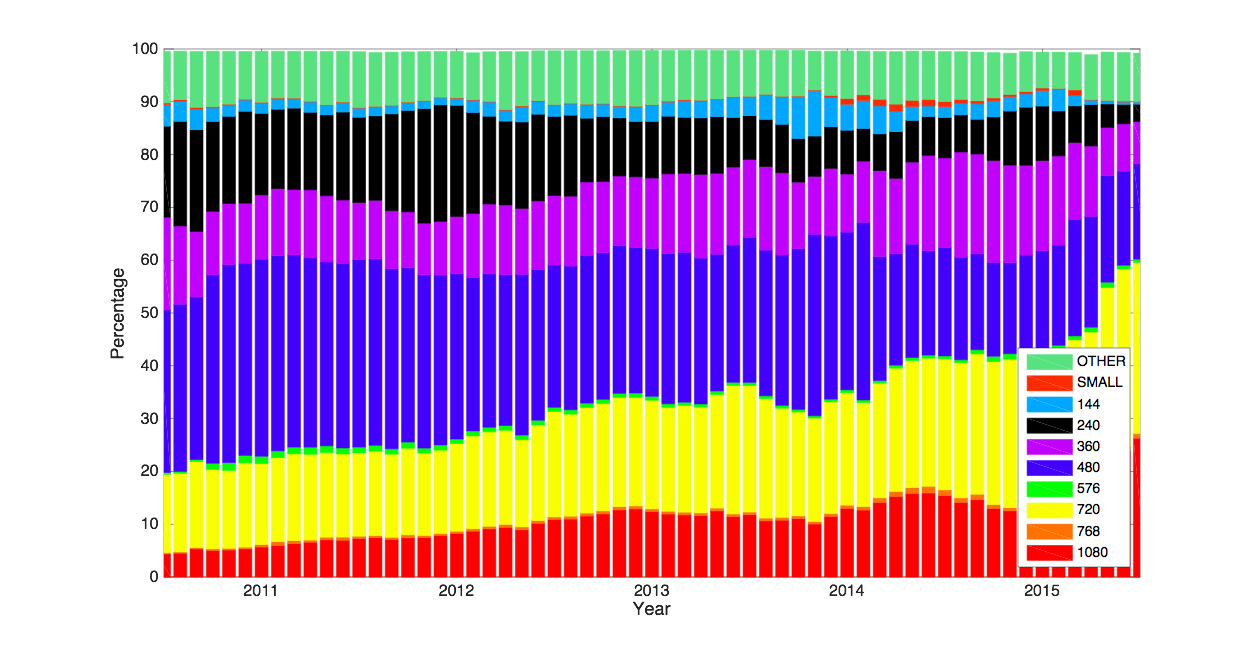
Picture sizeThe chart below stacks the proportions of each resolution in our ingest against month. The legend shows the top ten resolutions by proportion of ingest as measured over the last year, with the topmost label being the largest proportion. There is always some disparity between “standard” picture sizes and the actual uploaded sizes. Those which do not fall into the labels used here are allocated to “OTHER.” Although the vast majority of our ingest shows standard picture sizes, that “OTHER” category has been persistently steady, showing that there will always be about 10 percent of our uploaders who upload non-standard sizes. The trend is clearly toward bigger pictures, with 480p dominating five years ago and HD (720p and 1080p) dominating now. It is interesting that we do not see step changes in behavior but rather a gradual acceleration to higher pixel densities. The 480p resolution does appear to be in a permanent decline however. 720p seems set to replace “vanilla” 480p in about a year.
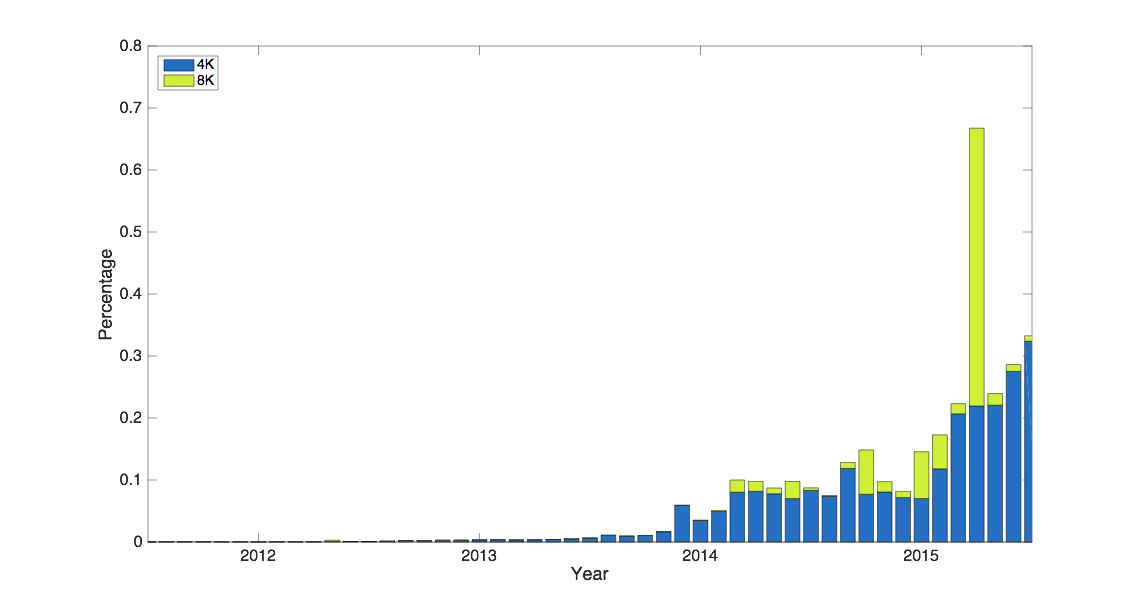
With the 4K and 8K formats we see rapid take-up reflected in our ingest. The chart below breaks out just these two resolutions. Although understandably small as a proportion of the whole YouTube ingest profile, these formats are still significant and we notice that the take-up accelerated/spiked once announcements were made in 2013 (4K) and 2015 (8K). What is even more interesting is that the upload of 4K content started well before “official” announcement of the support. Our creators are always pushing the limits of our ingest and this is good evidence.
Audio channelsWe observe that an increasing percentage of our media, which contain audio, contain stereo audio tracks as shown below in red. We also show here the relative amount of files having no audio (about 5 percent in 2015), and the trend is similar here as in the audio codec chart shown previously. A growing proportion of tracks contain 5.1 material but that is swamped by the amount of mono and stereo sound files. Making a linear prediction of the curves below would seem to imply that mono audio will decline to less than 5 percent of ingest in just over a year’s time.
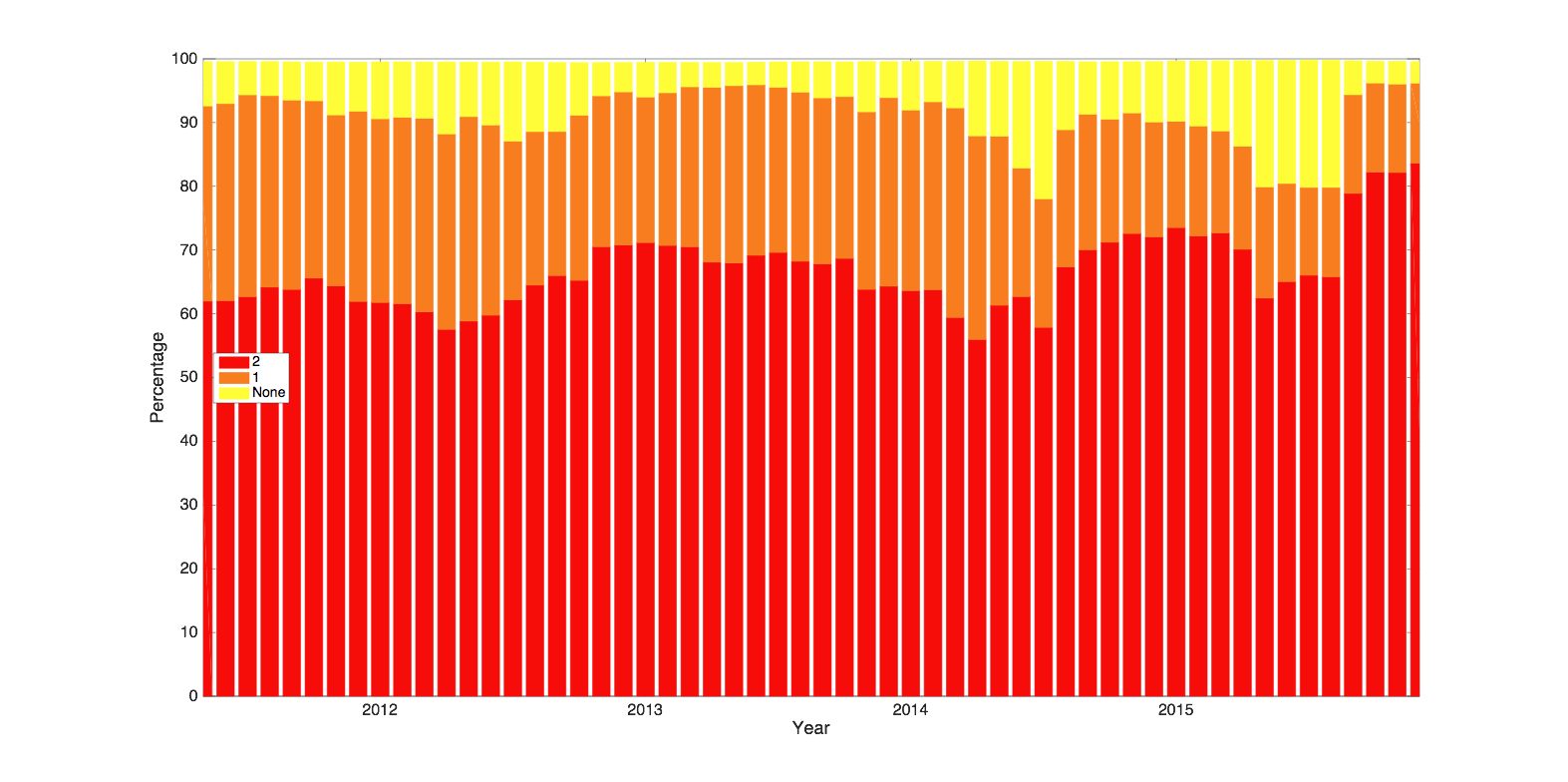
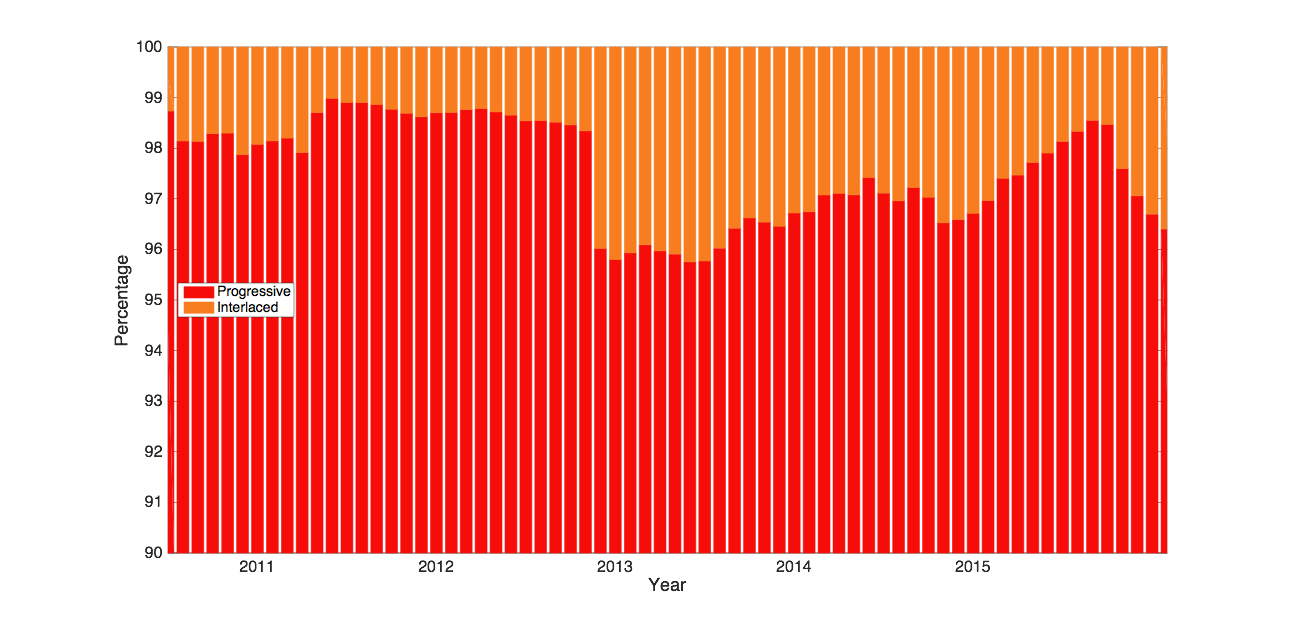
InterlacingInterlacing is still with us. This is the legacy TV broadcast practice of constructing a video frame from two half height images that record the odd and even lines of the final frame, but at slightly different times. The fraction of our content that is interlaced on upload appears to be roughly 2-3 percent averaged over the last five years and there is no sign of that actually dwindling. This is perhaps because of the small but significant made-for-TV content that is uploaded. The reasons for the observed rapid changes in some months are intriguing. One suggestion is correlation with unusually large volume TV coverage e.g. 2012 Olympics and the U.S. election.
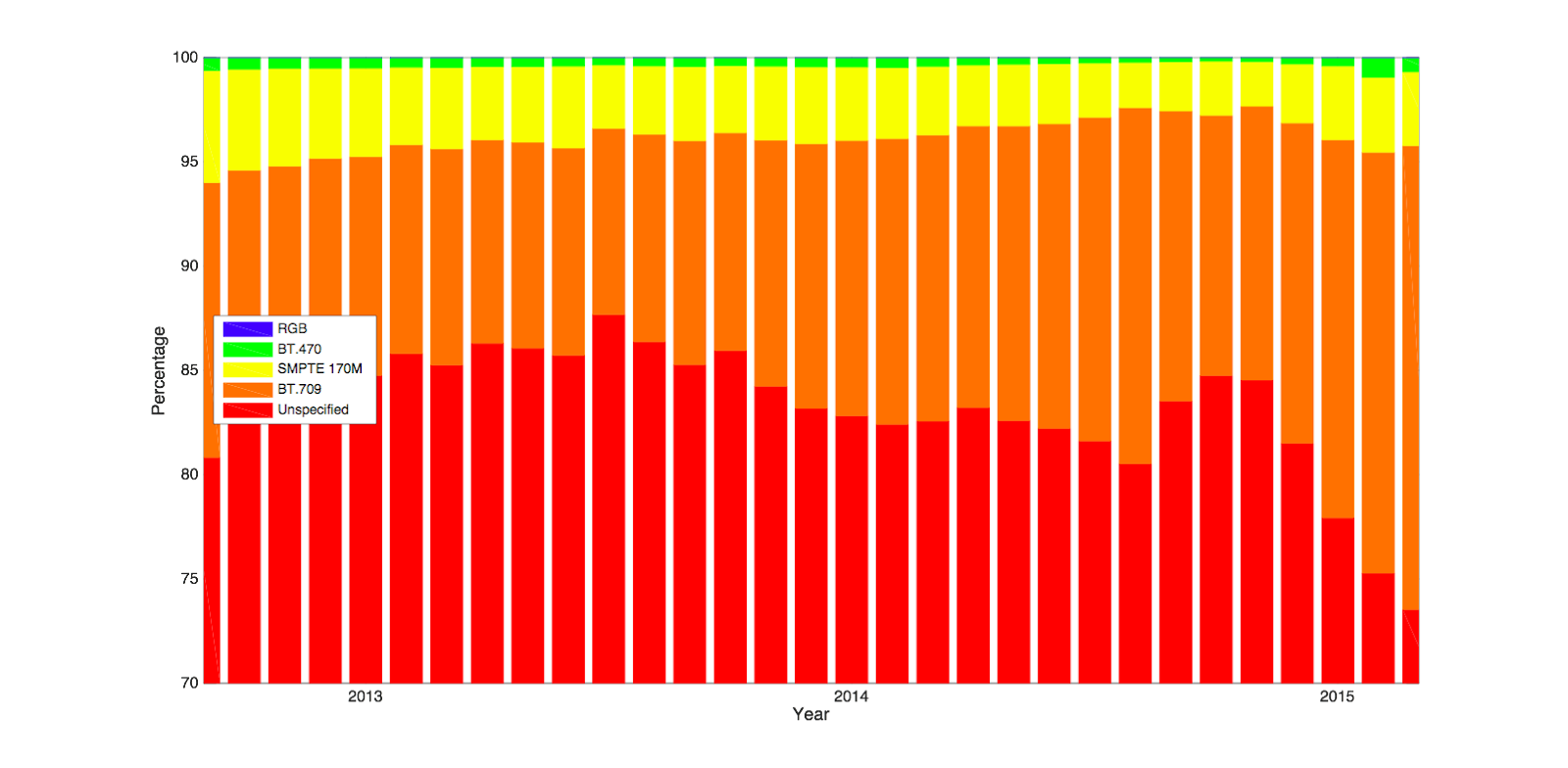
Color spacesWe are continually working on our ability to reproduce color faithfully between ingest and display. This is a notoriously challenging task across the consumer display industry for TV’s, monitors and mobile devices. The first step to color nirvana is the correct specification of the color space in the associated video file. Although color space specifications have been in place for some time, it has taken a long while for file-based content to properly represent this data across a wide range of consumer devices. The chart below reflects our observations of the top five spaces we see. We started collecting information in 2012 and compared to the stability in codecs and containers, the specification of color spaces in video data is clearly still evolving. It is only in the last three years that we have started to observe more consistent color labeling of video data, and as the chart shows below, BT709 (the default color space for HD resolution) has emerged as the dominant color space definition. At the end of 2015 there was still an alarmingly large proportion of video files without any color information, more than 70 percent. Note that the vertical axis on the chart below starts from 70 percent. The trend in that proportion is downwards and if we extend our curve of the decline in unspecified color spaces it would appear that it will be about a year before we can expect to see the majority of files having some color specification, and two years for almost all files to contain that metadata. We have just started to observe files expressing the recent BT2020 color space, being ingested at the end of 2015. These of course account for a tiny proportion of ingest (< .005 percent). It does herald the start of the HDR technology rollout though (as BT2020 is a color space associated with that format) and reflects various announcements about HDR capable devices made at CES 2016.
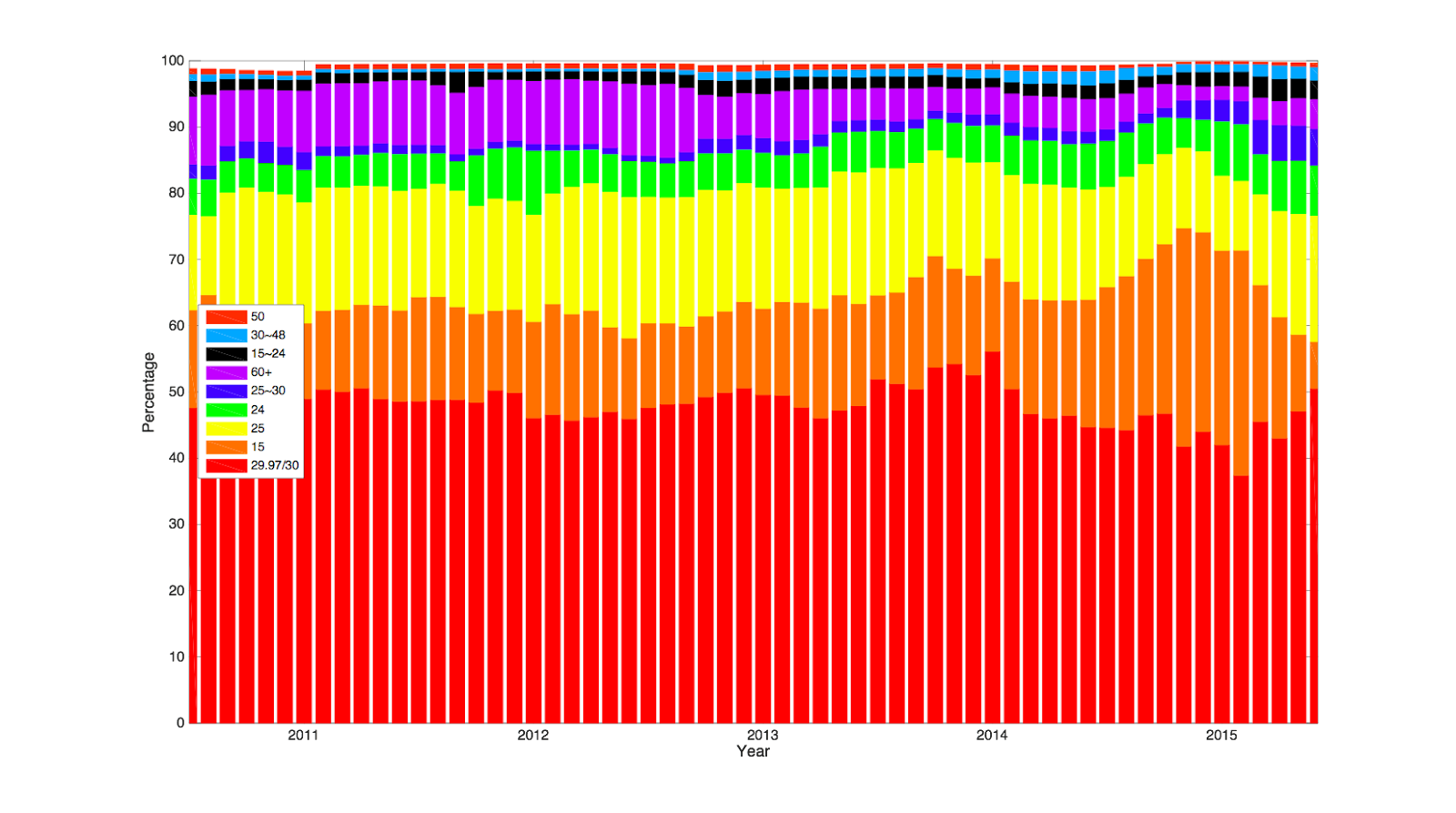
The chart below shows how the use of a range of frame rates has actually not changed that much over time. As expected the U.S. and EU standards of 30 and 25Hz respectively, dominate the distribution. Less expected is that low frame rates of 15fps and lower also significantly impact our ingest. This is because of the relatively large proportion of educational material including slide shows, as well as music slide decks that are uploaded to YouTube. That sort of material tends to be captured at low frame rates. High frame rate (HFR) material (e.g. from 48Hz and upwards) is a steady flow especially since the announcement of HFR support in the YouTube player in 2014. Before 2014, the ceiling of our output target video was 30fps but since then we have raised the ceiling to 60fps. However the trend is not increasing as much as is say 1080p ingest itself. This possibly reflects bandwidth constraints on upload as well as the fact that most capture today especially on mobile devices still defaults to 25 or 30fps.
We continuously analyze both a wide angle and close up view of the video file activity worldwide. That has given us a unique perspective on the evolution of video technology. In a sense the data is a reflection of the consensus of device manufacturers and creators in the area of media capture and creation. So we can see the growing agreement around video codecs, frame rates and stereo audio. Color space specification is still very poor however, and some expected consensus have not emerged. For example in the area of HFR content creation, 60+ fps is not quite yet on a growth curve as HD resolution has been over the last year.
The data presented here show that even in the last five years the variability in data types and formats is reducing. However, as with many broadcasters and streaming sites we see enough variability in our ingested file profiles that we remain keen on standardization activities. We look forward to continuing engagement of the YouTube and Google engineering community in SMPTE, MPEG and AOM activities.
Even with the dominance of certain technologies like H.264/AAC codecs and the MOV type containers, there will always be a small but significant portion of audio video data that falls outside the “consensus.” These small proportions are important to us however, because we want you to be confident that we’re going to do our darndest to help you broadcast yourself no matter what device you use to make your clip.
Anil Kokaram, Tech Lead/Engineering Manager, AV Algorithms Team, recently watched "Carlos Brathwaite's 4 sixes," Thierry Foucu, Tech Lead Transcoder Team, recently watched "Sale of the Century," and Yang Hu, Software Engineer, recently watched "MINECRAFT: How to build wooden mansion."