At some point in your life, you can probably recall a movie that you and your friends all wanted to see, and that you and your friends all regretted watching afterwards. Or maybe you remember that time your team thought they’d found the next "killer feature" for their product, only to see that feature bomb after it was released.
Good ideas often fail in practice, and in the world of testing, one pervasive good idea that often fails in practice is a testing strategy built around end-to-end tests.
Testers can invest their time in writing many types of automated tests, including unit tests, integration tests, and end-to-end tests, but this strategy invests mostly in end-to-end tests that verify the product or service as a whole. Typically, these tests simulate real user scenarios.
End-to-End Tests in Theory
While relying primarily on end-to-end tests is a bad idea, one could certainly convince a reasonable person that the idea makes sense in theory.To start, number one on Google's list of ten things we know to be true is: "Focus on the user and all else will follow." Thus, end-to-end tests that focus on real user scenarios sound like a great idea. Additionally, this strategy broadly appeals to many constituencies:
- Developers like it because it offloads most, if not all, of the testing to others.
- Managers and decision-makers like it because tests that simulate real user scenarios can help them easily determine how a failing test would impact the user.
- Testers like it because they often worry about missing a bug or writing a test that does not verify real-world behavior; writing tests from the user's perspective often avoids both problems and gives the tester a greater sense of accomplishment.
End-to-End Tests in Practice
So if this testing strategy sounds so good in theory, then where does it go wrong in practice? To demonstrate, I present the following composite sketch based on a collection of real experiences familiar to both myself and other testers. In this sketch, a team is building a service for editing documents online (e.g., Google Docs).Let's assume the team already has some fantastic test infrastructure in place. Every night:
- The latest version of the service is built.
- This version is then deployed to the team's testing environment.
- All end-to-end tests then run against this testing environment.
- An email report summarizing the test results is sent to the team.
The deadline is approaching fast as our team codes new features for their next release. To maintain a high bar for product quality, they also require that at least 90% of their end-to-end tests pass before features are considered complete. Currently, that deadline is one day away:
| Days Left | Pass % | Notes |
| 1 | 5% | Everything is broken! Signing in to the service is broken. Almost all tests sign in a user, so almost all tests failed. |
| 0 | 4% | A partner team we rely on deployed a bad build to their testing environment yesterday. |
| -1 | 54% | A dev broke the save scenario yesterday (or the day before?). Half the tests save a document at some point in time. Devs spent most of the day determining if it's a frontend bug or a backend bug. |
| -2 | 54% | It's a frontend bug, devs spent half of today figuring out where. |
| -3 | 54% | A bad fix was checked in yesterday. The mistake was pretty easy to spot, though, and a correct fix was checked in today. |
| -4 | 1% | Hardware failures occurred in the lab for our testing environment. |
| -5 | 84% | Many small bugs hiding behind the big bugs (e.g., sign-in broken, save broken). Still working on the small bugs. |
| -6 | 87% | We should be above 90%, but are not for some reason. |
| -7 | 89.54% | (Rounds up to 90%, close enough.) No fixes were checked in yesterday, so the tests must have been flaky yesterday. |
Analysis
Despite numerous problems, the tests ultimately did catch real bugs.What Went Well
- Customer-impacting bugs were identified and fixed before they reached the customer.
What Went Wrong
- The team completed their coding milestone a week late (and worked a lot of overtime).
- Finding the root cause for a failing end-to-end test is painful and can take a long time.
- Partner failures and lab failures ruined the test results on multiple days.
- Many smaller bugs were hidden behind bigger bugs.
- End-to-end tests were flaky at times.
- Developers had to wait until the following day to know if a fix worked or not.
So now that we know what went wrong with the end-to-end strategy, we need to change our approach to testing to avoid many of these problems. But what is the right approach?
The True Value of Tests
Typically, a tester's job ends once they have a failing test. A bug is filed, and then it's the developer's job to fix the bug. To identify where the end-to-end strategy breaks down, however, we need to think outside this box and approach the problem from first principles. If we "focus on the user (and all else will follow)," we have to ask ourselves how a failing test benefits the user. Here is the answer:A failing test does not directly benefit the user.
While this statement seems shocking at first, it is true. If a product works, it works, whether a test says it works or not. If a product is broken, it is broken, whether a test says it is broken or not. So, if failing tests do not benefit the user, then what does benefit the user?
A bug fix directly benefits the user.
The user will only be happy when that unintended behavior - the bug - goes away. Obviously, to fix a bug, you must know the bug exists. To know the bug exists, ideally you have a test that catches the bug (because the user will find the bug if the test does not). But in that entire process, from failing test to bug fix, value is only added at the very last step.
| Stage | Failing Test | Bug Opened | Bug Fixed |
| Value Added | No | No | Yes |
Thus, to evaluate any testing strategy, you cannot just evaluate how it finds bugs. You also must evaluate how it enables developers to fix (and even prevent) bugs.
Building the Right Feedback Loop
Tests create a feedback loop that informs the developer whether the product is working or not. The ideal feedback loop has several properties:- It's fast. No developer wants to wait hours or days to find out if their change works. Sometimes the change does not work - nobody is perfect - and the feedback loop needs to run multiple times. A faster feedback loop leads to faster fixes. If the loop is fast enough, developers may even run tests before checking in a change.
- It's reliable. No developer wants to spend hours debugging a test, only to find out it was a flaky test. Flaky tests reduce the developer's trust in the test, and as a result flaky tests are often ignored, even when they find real product issues.
- It isolates failures. To fix a bug, developers need to find the specific lines of code causing the bug. When a product contains millions of lines of codes, and the bug could be anywhere, it's like trying to find a needle in a haystack.
Think Smaller, Not Larger
So how do we create that ideal feedback loop? By thinking smaller, not larger.Unit Tests
Unit tests take a small piece of the product and test that piece in isolation. They tend to create that ideal feedback loop:- Unit tests are fast. We only need to build a small unit to test it, and the tests also tend to be rather small. In fact, one tenth of a second is considered slow for unit tests.
- Unit tests are reliable. Simple systems and small units in general tend to suffer much less from flakiness. Furthermore, best practices for unit testing - in particular practices related to hermetic tests - will remove flakiness entirely.
- Unit tests isolate failures. Even if a product contains millions of lines of code, if a unit test fails, you only need to search that small unit under test to find the bug.
Writing effective unit tests requires skills in areas such as dependency management, mocking, and hermetic testing. I won't cover these skills here, but as a start, the typical example offered to new Googlers (or Nooglers) is how Google builds and tests a stopwatch.
Unit Tests vs. End-to-End Tests
With end-to-end tests, you have to wait: first for the entire product to be built, then for it to be deployed, and finally for all end-to-end tests to run. When the tests do run, flaky tests tend to be a fact of life. And even if a test finds a bug, that bug could be anywhere in the product.Although end-to-end tests do a better job of simulating real user scenarios, this advantage quickly becomes outweighed by all the disadvantages of the end-to-end feedback loop:
| Unit | End-toEnd | |
| Fast |  |  |
| Reliable | | |
| Isolates Failures | | |
| Simulates a Real User | | |
Integration Tests
Unit tests do have one major disadvantage: even if the units work well in isolation, you do not know if they work well together. But even then, you do not necessarily need end-to-end tests. For that, you can use an integration test. An integration test takes a small group of units, often two units, and tests their behavior as a whole, verifying that they coherently work together.If two units do not integrate properly, why write an end-to-end test when you can write a much smaller, more focused integration test that will detect the same bug? While you do need to think larger, you only need to think a little larger to verify that units work together.
Testing Pyramid
Even with both unit tests and integration tests, you probably still will want a small number of end-to-end tests to verify the system as a whole. To find the right balance between all three test types, the best visual aid to use is the testing pyramid. Here is a simplified version of the testing pyramid from the opening keynote of the 2014 Google Test Automation Conference: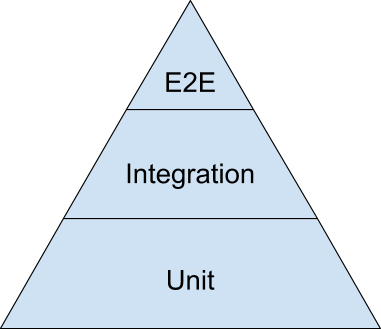
The bulk of your tests are unit tests at the bottom of the pyramid. As you move up the pyramid, your tests gets larger, but at the same time the number of tests (the width of your pyramid) gets smaller.
As a good first guess, Google often suggests a 70/20/10 split: 70% unit tests, 20% integration tests, and 10% end-to-end tests. The exact mix will be different for each team, but in general, it should retain that pyramid shape. Try to avoid these anti-patterns:
- Inverted pyramid/ice cream cone. The team relies primarily on end-to-end tests, using few integration tests and even fewer unit tests.
- Hourglass. The team starts with a lot of unit tests, then uses end-to-end tests where integration tests should be used. The hourglass has many unit tests at the bottom and many end-to-end tests at the top, but few integration tests in the middle.

