Being able to recognize “who said what,” or speaker diarization, is a critical step in understanding audio of human dialog through automated means. For instance, in a medical conversation between doctors and patients, “Yes” uttered by a patient in response to “Have you been taking your heart medications regularly?” has a substantially different implication than a rhetorical “Yes?” from a physician.
Conventional speaker diarization (SD) systems use two stages, the first of which detects changes in the acoustic spectrum to determine when the speakers in a conversation change, and the second of which identifies individual speakers across the conversation. This basic multi-stage approach is almost two decades old, and during that time only the speaker change detection component has improved.
With the recent development of a novel neural network model—the recurrent neural network transducer (RNN-T)—we now have a suitable architecture to improve the performance of speaker diarization addressing some of the limitations of the previous diarization system we presented recently. As reported in our recent paper, “Joint Speech Recognition and Speaker Diarization via Sequence Transduction,” to be presented at Interspeech 2019, we have developed an RNN-T based speaker diarization system and have demonstrated a breakthrough in performance from about 20% to 2% in word diarization error rate—a factor of 10 improvement.
Conventional Speaker Diarization Systems
Conventional speaker diarization systems rely on differences in how people sound acoustically to distinguish the speakers in the conversations. While male and female speakers can be identified relatively easily from their pitch using simple acoustic models (e.g., Gaussian mixture models) in a single stage, speaker diarization systems use a multi-stage approach to distinguish between speakers having potentially similar pitch. First, a change detection algorithm breaks up the conversation into homogeneous segments, hopefully containing only a single speaker, based upon detected vocal characteristics. Then, deep learning models are employed to map segments from each speaker to an embedding vector. Finally, in a clustering stage, these embeddings are grouped together to keep track of the same speaker across the conversation.
In practice, the speaker diarization system runs in parallel to the automatic speech recognition (ASR) system and the outputs of the two systems are combined to attribute speaker labels to the recognized words.
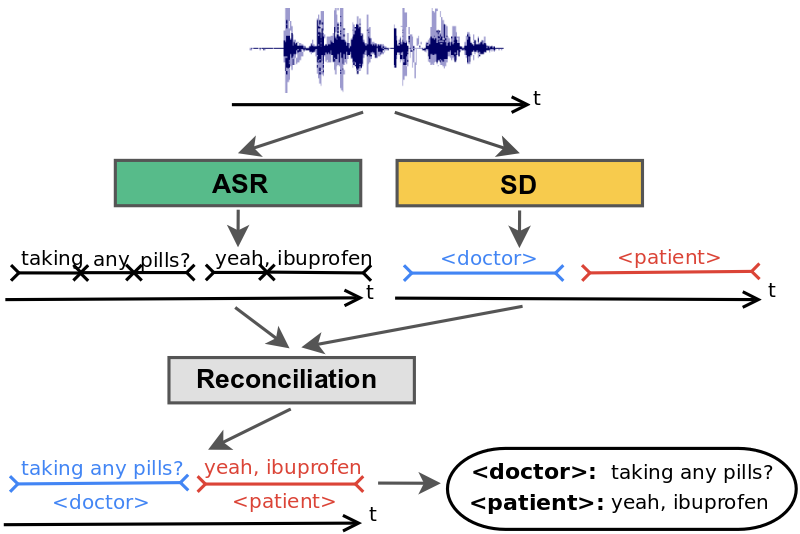 |
| Conventional speaker diarization system infers speaker labels in the acoustic domain and then overlays the speaker labels on the words generated by a separate ASR system. |
There are a few exceptions to the conventional speaker diarization system, but one such exception was reported in our recent blog post. In that work, the hidden states of the recurrent neural network (RNN) tracked the speakers, circumventing the weakness of the clustering stage. Our approach takes a different approach and incorporates linguistic cues, as well.
An Integrated Speech Recognition and Speaker Diarization System
We developed a novel and simple model that not only combines acoustic and linguistic cues seamlessly, but also combines speaker diarization and speech recognition into one system. The integrated model does not degrade the speech recognition performance significantly compared to an equivalent recognition only system.
The key insight in our work was to recognize that the RNN-T architecture is well-suited to integrate acoustic and linguistic cues. The RNN-T model consists of three different networks: (1) a transcription network (or encoder) that maps the acoustic frames to a latent representation, (2) a prediction network that predicts the next target label given the previous target labels, and (3) a joint network that combines the output of the previous two networks and generates a probability distribution over the set of output labels at that time step. Note, there is a feedback loop in the architecture (diagram below) where previously recognized words are fed back as input, and this allows the RNN-T model to incorporate linguistic cues, such as the end of a question.
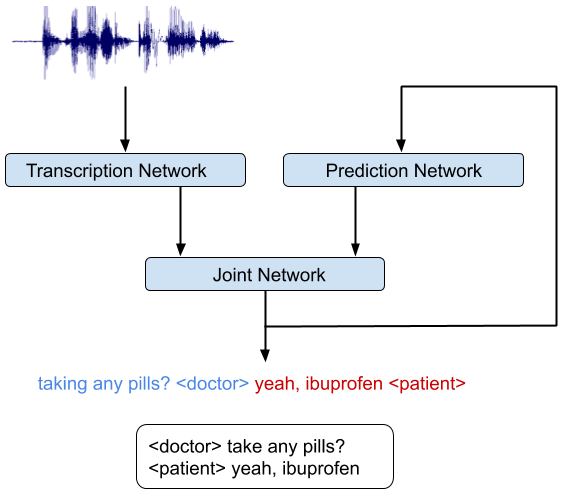 |
| An integrated speech recognition and speaker diarization system where the system jointly infers who spoke when and what. |
The integrated model can be trained just like a speech recognition system. The reference transcripts for training contain words spoken by a speaker followed by a tag that defines the role of the speaker. For example, “When is the homework due?” ≺student≻, “I expect you to turn them in tomorrow before class,” ≺teacher≻. Once the model is trained with examples of audio and corresponding reference transcripts, a user can feed in the recording of the conversation and expect to see an output in a similar form. Our analyses show that improvements from the RNN-T system impact all categories of errors, including short speaker turns, splitting at the word boundaries, incorrect speaker assignment in the presence of overlapping speech, and poor audio quality. Moreover, the RNN-T system exhibited consistent performance across conversation with substantially lower variance in average error rate per conversation compared to the conventional system.
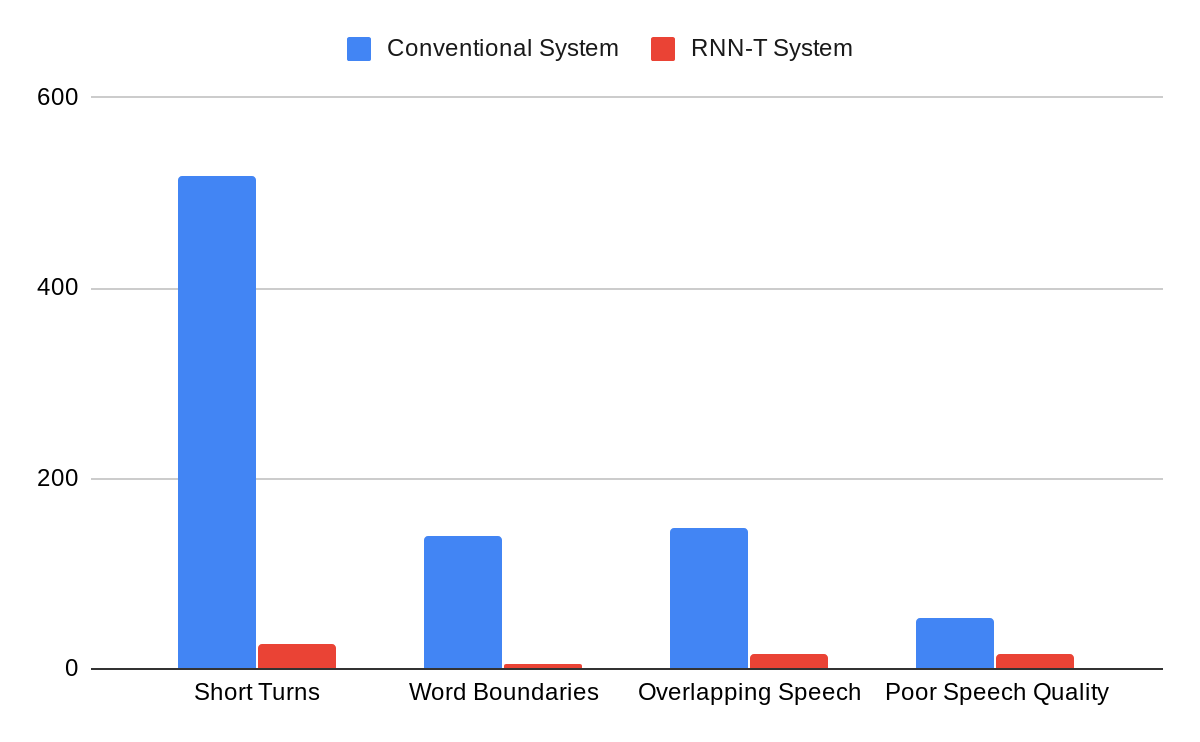 |
| A comparison of errors committed by the conventional system vs. the RNN-T system, as categorized by human annotators. |
This model has now become a standard component in our project on understanding medical conversations and is also being adopted more widely in our non-medical speech services.
Acknowledgements
We would like to thank Hagen Soltau without whose contributions this work would not have been possible. This work was performed in collaboration with Google Brain and Speech teams.
