Posted by Craig McLuckie, Co-founder of Kubernetes and Senior Product Manager at Google
"So let me get this straight. You want to build an external version of the Borg task scheduler. One of our most important competitive advantages. The one we don’t even talk about externally. And, on top of that, you want to open source it?"
The story of how Kubernetes came to be starts here. It was Summer 2013, and we were in a room with Urs Holzle, head of technical infrastructure and chief architect of many of Google’s most important network innovations. We were pitching him our idea to build an open source container management system. But it wasn’t going well. Or so we thought.
To really understand how we ended up in that meeting, you have to back up a bit. For years, Google had been quietly building some of the best network infrastructure to power intensive online services like Google Search, Gmail and YouTube. We built everything from scratch because we had to, and in the early days, we were on a tight budget. In order to wring every possible ounce of performance out of our servers, we had started experimenting with containers over a decade ago. We built a cluster management system called
Borg, which runs hundreds of thousands of jobs and makes computing much more efficient — allowing us to run our data centers at high utilization.
Later, we used this same infrastructure to deliver
Google Cloud Platform, so anyone could use it for their computing needs. However, with the launch of our Infrastructure-as-a-Service platform
Google Compute Engine, we noticed an interesting problem: customers were paying for a lot of CPUs, but their utilization rates were extremely low because they were running VMs. We knew we had an internal solution for this. And what’s more, we knew that containers were the future of computing — they’re scalable, portable and more efficient. The container system Docker was already up and running, and we thought it was great. But the trick, which we knew through years of trial and error within Google, was a great container management system. That’s what we wanted to build.
Even though we had been rejected before, we didn’t give up. Good ideas usually win out at Google, and we were convinced this was a good idea. We met with anyone who would listen to us to pitch the idea. A turning point was a fateful shuttle ride where I found myself sitting next to Eric Brewer, VP of Cloud, and one of Urs’s key strategists. I had an uninterrupted chunk of time to explain the idea to Eric, and he was convinced. Soon after, we got the green light from Urs.
In keeping with the Borg theme, we named it Project
Seven of Nine. (Side note: in an homage to the original name, this is also why the
Kubernetes logo has seven sides.) We wanted to build something that incorporated everything we had learned about container management at Google through the design and deployment of
Borg and its successor, Omega — all combined with an elegant, simple and easy-to-use UI. In three months, we had a prototype that was ready to share.
We always believed that open-sourcing Kubernetes was the right way to go, bringing many benefits to the project. For one, feedback loops were essentially instantaneous — if there was a problem or something didn’t work quite right, we knew about it immediately. But most importantly, we were able to work with lots of great engineers, many of whom really understood the needs of businesses who would benefit from deploying containers (have a look at the
Kubernetes blog for perspectives from some of the early contributors). It was a virtuous cycle: the work of talented engineers led to more interest in the project, which further increased the rate of improvement and usage.
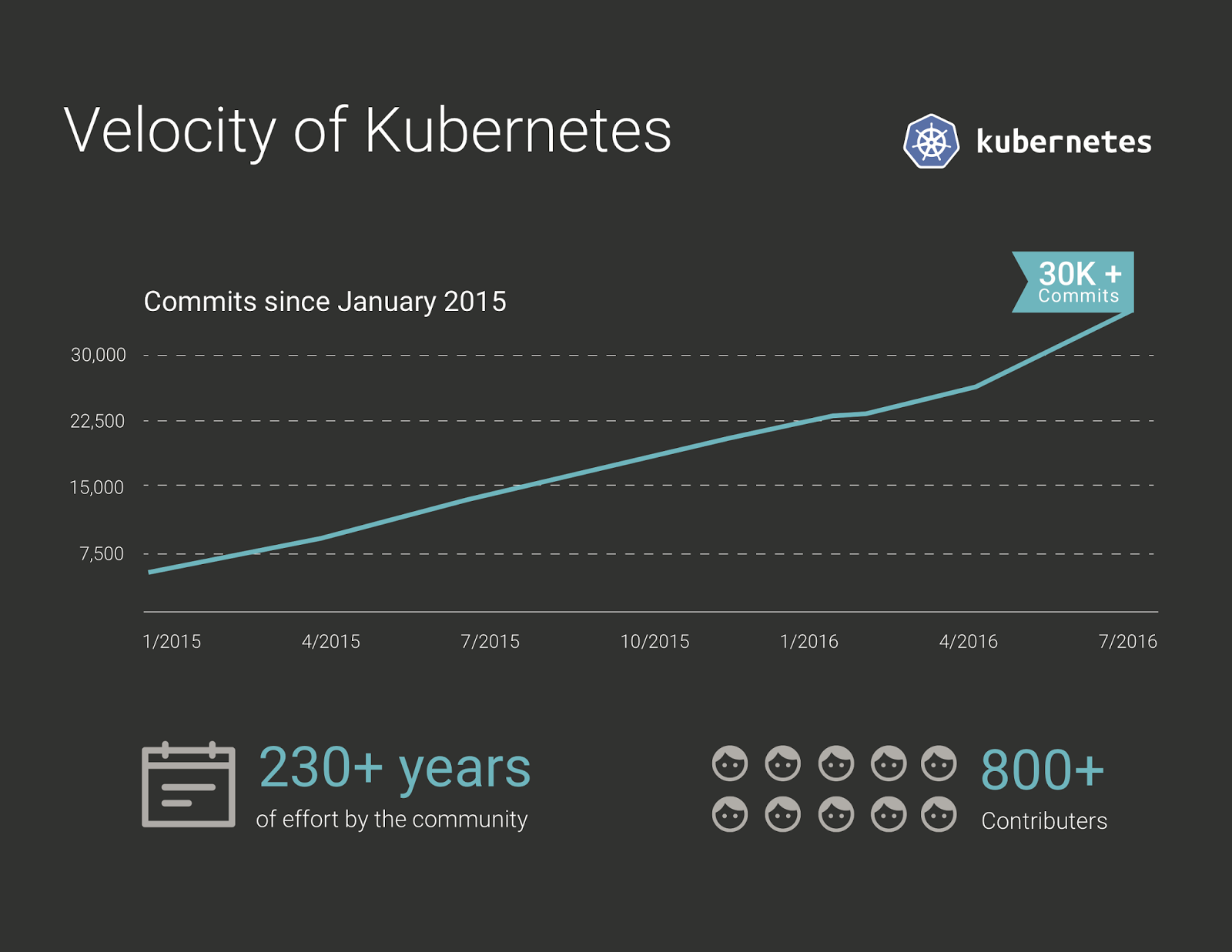
What started as an internal summer conversation has evolved into a global movement. Kubernetes is now deployed in thousands of organizations (e.g.,
Box), supported by over 830 contributors that have collectively put in 237 person years of coding effort to date. Velocity that even our wildest goals didn’t anticipate. To our contributing peers and community advocates, a sincere thank you for making Kubernetes so welcoming and transparent. And to you Kubernetes, a very
happy birthday to you!
If you haven’t tried Kubernetes, it’s easy to get started using
Google Container Engine; begin your 60-day
free trial here. And to learn more about the Kubernetes story,
check out the Kubernetes Origins podcast on Software Engineering Daily.