Machine learning is being deployed in more and more real-world applications, including medicine, chemistry and agriculture. When it comes to deploying machine learning in safety-critical contexts, significant challenges remain. In particular, all known machine learning algorithms are vulnerable to adversarial examples — inputs that an attacker has intentionally designed to cause the model to make a mistake. While previous research on adversarial examples has mostly focused on investigating mistakes caused by small modifications in order to develop improved models, real-world adversarial agents are often not subject to the “small modification” constraint. Furthermore, machine learning algorithms can often make confident errors when faced with an adversary, which makes the development of classifiers that don’t make any confident mistakes, even in the presence of an adversary which can submit arbitrary inputs to try to fool the system, an important open problem.
Today we're announcing the Unrestricted Adversarial Examples Challenge, a community-based challenge to incentivize and measure progress towards the goal of zero confident classification errors in machine learning models. While previous research has focused on adversarial examples that are restricted to small changes to pre-labeled data points (allowing researchers to assume the image should have the same label after a small perturbation), this challenge allows unrestricted inputs, allowing participants to submit arbitrary images from the target classes to develop and test models on a wider variety of adversarial examples.
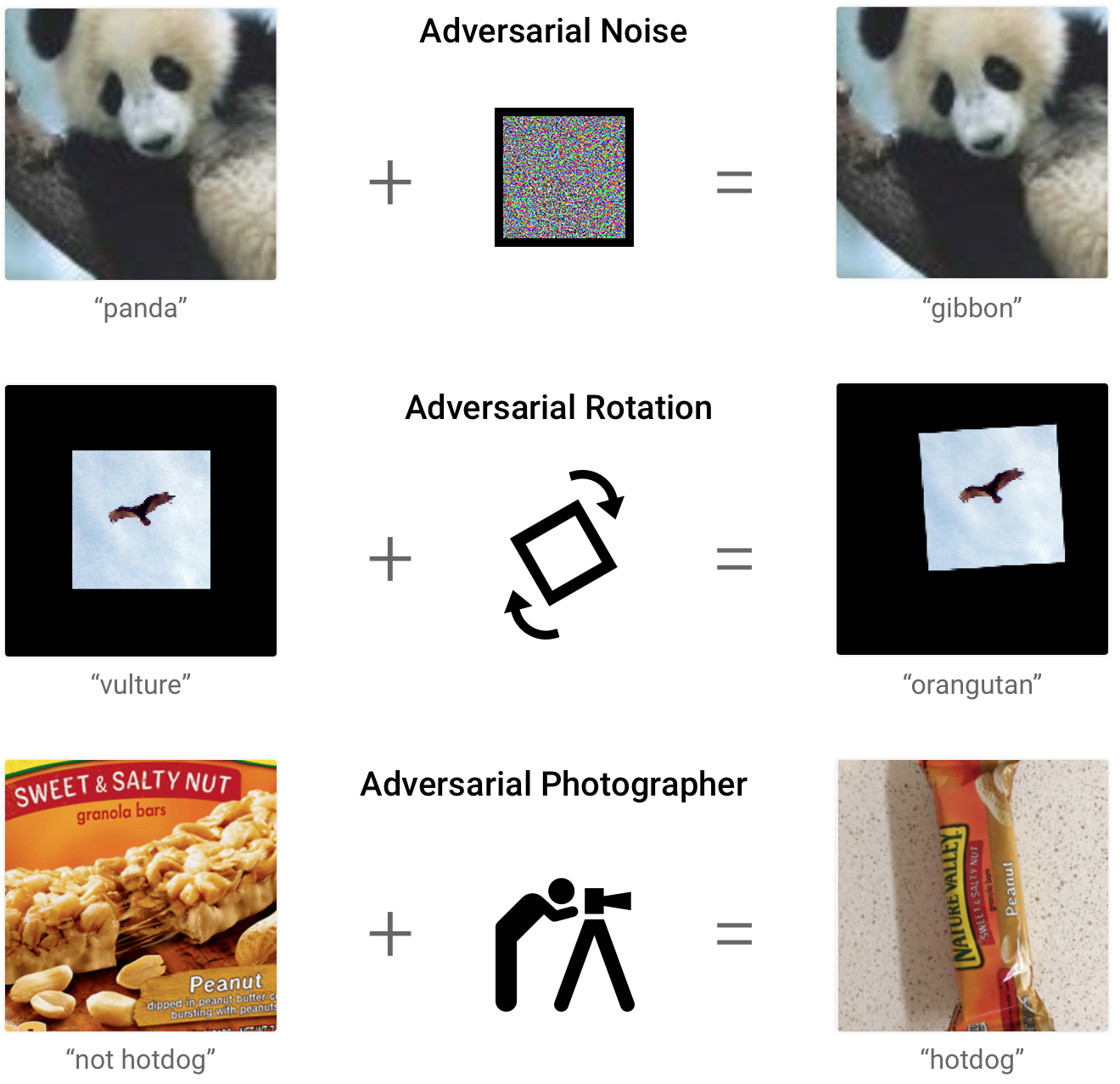 |
| Adversarial examples can be generated through a variety of means, including by making small modifications to the input pixels, but also using spatial transformations, or simple guess-and-check to find misclassified inputs. |
Participants can submit entries one of two roles: as a defender, by submitting a classifier which has been designed to be difficult to fool, or as an attacker, by submitting arbitrary inputs to try to fool the defenders' models. In a “warm-up” period before the challenge, we will present a set of fixed attacks for participants to design networks to defend against. After the community can conclusively beat those fixed attacks, we will launch the full two-sided challenge with prizes for both attacks and defenses.

For the purposes of this challenge, we have created a simple “bird-or-bicycle” classification task, where a classifier must answer the following: “Is this an unambiguous picture of a bird, a bicycle, or is it ambiguous / not obvious?” We selected this task because telling birds and bicycles apart is very easy for humans, but all known machine learning techniques struggle at the task when in the presence of an adversary.
The defender's goal is to correctly label a clean test set of birds and bicycles with high accuracy, while also making no confident errors on any attacker-provided bird or bicycle image. The attacker's goal is to find an image of a bird that the defending classifier confidently labels as a bicycle (or vice versa). We want to make the challenge as easy as possible for the defenders, so we discard all images that are ambiguous (such as a bird riding a bicycle) or not obvious (such as an aerial view of a park, or random noise).
 |
| Examples of ambiguous and unambiguous images. Defenders must make no confident mistakes on unambiguous bird or bicycle images. We discard all images that humans find ambiguous or not obvious. All images under CC licenses 1, 2, 3, 4. |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
In order to validate new attacker-provided images, we ask an ensemble of humans to label the image. This procedure lets us allow attackers to submit arbitrary images, not just test set images modified in small ways. If the defending classifier confidently classifies as "bird" any attacker-provided image which the human labelers unanimously labeled as a bicycle, the defending model has been broken. You can learn more details about the structure of the challenge in our paper.
How to Participate
If you’re interested in participating, guidelines for getting started can be found on the project on github. We’ve already released our dataset, the evaluation pipeline, and baseline attacks for the warm-up, and we’ll be keeping an up-to-date leaderboard with the best defenses from the community. We look forward to your entries!
Acknowledgements
The team behind the Unrestricted Adversarial Examples Challenge includes Tom Brown, Catherine Olsson, Nicholas Carlini, Chiyuan Zhang, and Ian Goodfellow from Google, and Paul Christiano from OpenAI.
