Earlier this week, we announced the latest release of the TF-Slim library for TensorFlow, a lightweight package for defining, training and evaluating models, as well as checkpoints and model definitions for several competitive networks in the field of image classification.
In order to spur even further progress in the field, today we are happy to announce the release of Inception-ResNet-v2, a convolutional neural network (CNN) that achieves a new state of the art in terms of accuracy on the ILSVRC image classification benchmark. Inception-ResNet-v2 is a variation of our earlier Inception V3 model which borrows some ideas from Microsoft's ResNet papers [1][2]. The full details of the model are in our arXiv preprint Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning.
Residual connections allow shortcuts in the model and have allowed researchers to successfully train even deeper neural networks, which have lead to even better performance. This has also enabled significant simplification of the Inception blocks. Just compare the model architectures in the figures below:
 |
| Schematic diagram of Inception V3 |
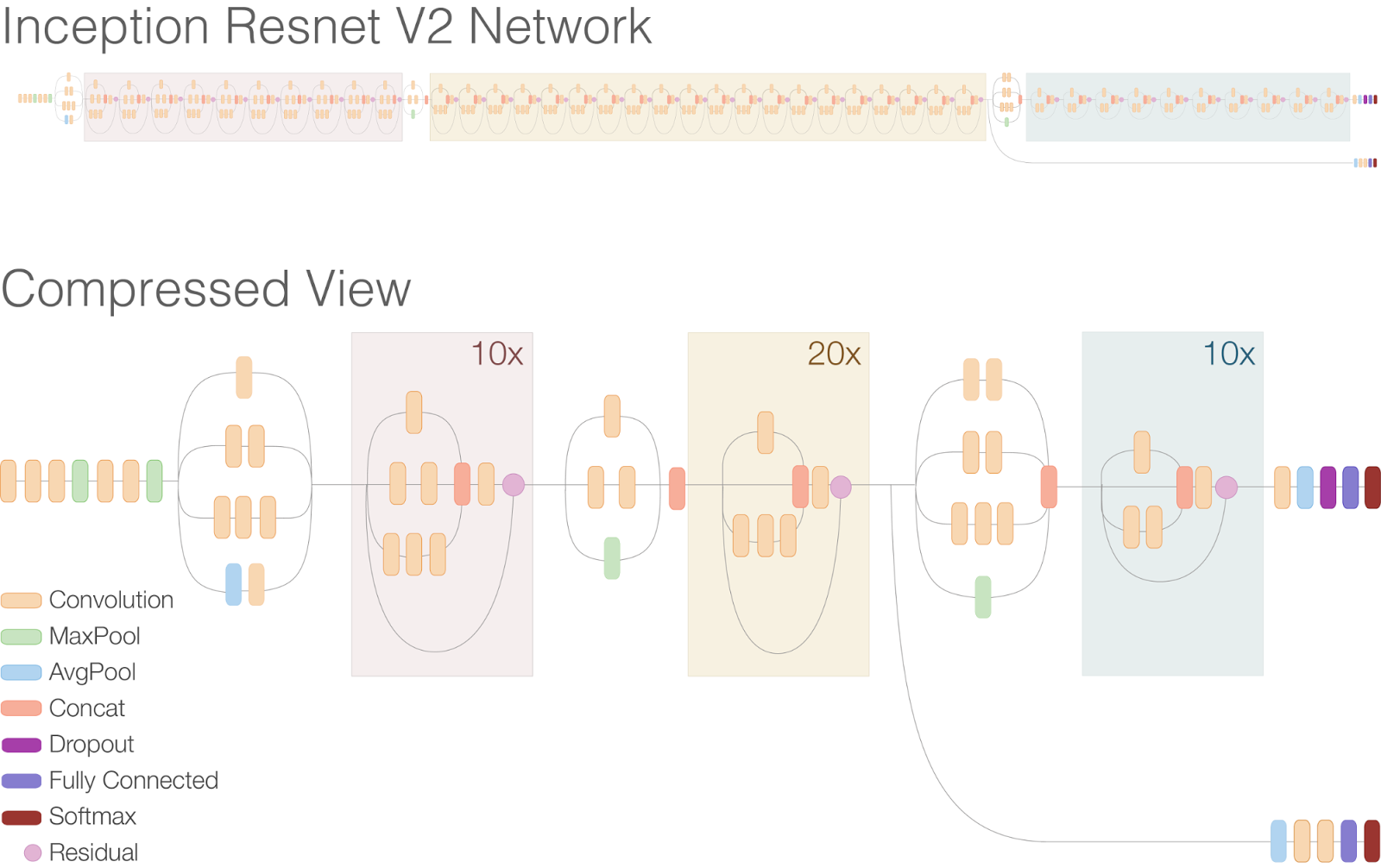 |
| Schematic diagram of Inception-ResNet-v2 |
The Inception-ResNet-v2 architecture is more accurate than previous state of the art models, as shown in the table below, which reports the Top-1 and Top-5 validation accuracies on the ILSVRC 2012 image classification benchmark based on a single crop of the image. Furthermore, this new model only requires roughly twice the memory and computation compared to Inception V3.
Architecture | ||||
TBA |
(*): Results quoted in ResNet paper.
As an example, while both Inception V3 and Inception-ResNet-v2 models excel at identifying individual dog breeds, the new model does noticeably better. For instance, whereas the old model mistakenly reported Alaskan Malamute for the picture on the right, the new Inception-ResNet-v2 model correctly identifies the dog breeds in both images.
 |
| An Alaskan Malamute (left) and a Siberian Husky (right). Images from Wikipedia |
{kind=link}
{kind=link}
We are excited to see what the community does with this improved model, following along as people adapt it and compare its performance on various tasks. Want to get started? See the accompanying instructions on how to train, evaluate or fine-tune a network.
As always, releasing the code was a team effort. Specific thanks are due to:
- Model Architecture - Christian Szegedy, Sergey Ioffe, Vincent Vanhoucke, Alex Alemi
- Systems Infrastructure - Jon Shlens, Benoit Steiner, Mark Sandler, and David Andersen
- TensorFlow-Slim - Sergio Guadarrama and Nathan Silberman
- Model Visualization - Fernanda Viégas and James Wexler
