One of the design goals and core strengths of TensorFlow is its flexibility. TensorFlow was designed to be a flexible and extensible system for defining arbitrary data flow graphs and executing them efficiently in a distributed manner using heterogenous computing devices (such as CPUs and GPUs).
But flexibility is often at odds with performance. While TensorFlow aims to let you define any kind of data flow graph, it’s challenging to make all graphs execute efficiently because TensorFlow optimizes each op separately. When an op with an efficient implementation exists or when each op is a relatively heavyweight operation, all is well; otherwise, the user can still compose this op out of lower-level ops, but this composition is not guaranteed to run in the most efficient way.
This is why we’ve developed XLA (Accelerated Linear Algebra), a compiler for TensorFlow. XLA uses JIT compilation techniques to analyze the TensorFlow graph created by the user at runtime, specialize it for the actual runtime dimensions and types, fuse multiple ops together and emit efficient native machine code for them - for devices like CPUs, GPUs and custom accelerators (e.g. Google’s TPU).
Fusing composable ops for increased performance
Consider the tf.nn.softmax op, for example. It computes the softmax activations of its parameter as follows:
Softmax can be implemented as a composition of primitive TensorFlow ops (exponent, reduction, elementwise division, etc.):
softmax = exp(logits) / reduce_sum(exp(logits), dim)
This could potentially be slow, due to the extra data movement and materialization of temporary results that aren’t needed outside the op. Moreover, on co-processors like GPUs such a decomposed implementation could result in multiple “kernel launches” that make it even slower.
XLA is the secret compiler sauce that helps TensorFlow optimize compositions of primitive ops automatically. Tensorflow, augmented with XLA, retains flexibility without sacrificing runtime performance, by analyzing the graph at runtime, fusing ops together and producing efficient machine code for the fused subgraphs.
For example, a decomposed implementation of softmax as shown above would be optimized by XLA to be as fast as the hand-optimized compound op.
More generally, XLA can take whole subgraphs of TensorFlow operations and fuse them into efficient loops that require a minimal number of kernel launches. For example:
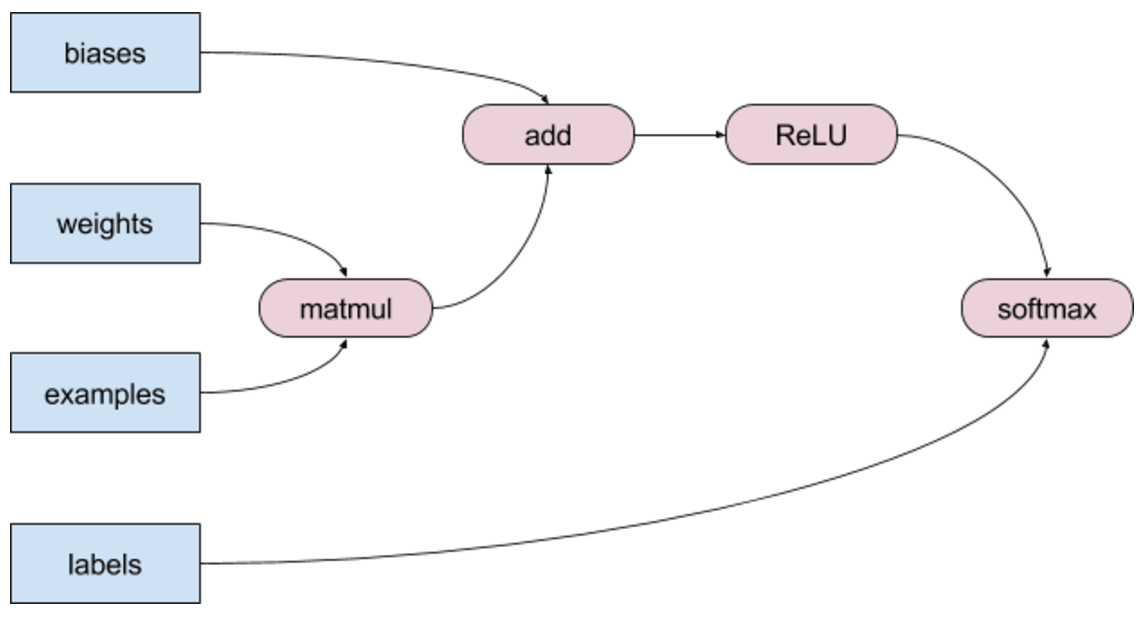
Many of the operations in this graph can be fused into a single element-wise loop. Consider a single element of the bias vector being added to a single element from the matmul result, for example. The result of this addition is a single element that can be compared with 0 (for ReLU). The result of the comparison can be exponentiated and divided by the sum of exponents of all inputs, resulting in the output of softmax. We don’t really need to create the intermediate arrays for matmul, add, and ReLU in memory.
s[j] = softmax[j](ReLU(bias[j] + matmul_result[j]))
A fused implementation can compute the end result within a single element-wise loop, without allocating needless memory. In more advanced scenarios, these operations can even be fused into the matrix multiplication.
XLA helps TensorFlow retain its flexibility while eliminating performance concerns.
On internal benchmarks, XLA shows up to 50% speedups over TensorFlow without XLA on Nvidia GPUs. The biggest speedups come, as expected, in models with long sequences of elementwise operations that can be fused to efficient loops. However, XLA should still be considered experimental, and some benchmarks may experience slowdowns.
In this talk from TensorFlow Developer Summit, Chris Leary and Todd Wang describe how TensorFlow can make use of XLA, JIT, AOT, and other compilation techniques to minimize execution time and maximize computing resources.
Extreme specialization for executable size reduction
In addition to improved performance, TensorFlow models can benefit from XLA for restricted-memory environments (such as mobile devices) due to the executable size reduction it provides. tfcompile is a tool that leverages XLA for ahead-of-time compilation (AOT) - a whole graph is compiled to XLA, which then emits tight machine code that implements the ops in the graph. Coupled with a minimal runtime this scheme provides considerable size reductions.
For example, given a 3-deep, 60-wide stacked LSTM model on android-arm, the original TF model size is 2.6 MB (1 MB runtime + 1.6 MB graph); when compiled with XLA, the size goes down to 600 KB.
 |
Support for alternative backends and devices
To execute TensorFlow graphs on a new kind of computing device today, one has to re-implement all the TensorFlow ops (kernels) for the new device. Depending on the device, this can be a very significant amount of work.
By design, XLA makes supporting new devices much easier by adding custom backends. Since TensorFlow can target XLA, one can add a new device backend to XLA and thus enable it to run TensorFlow graphs. XLA provides a significantly smaller implementation surface for new devices, since XLA operations are just the primitives (recall that XLA handles the decomposition of complex ops on its own). We’ve documented the process for adding a custom backend to XLA on this page. Google uses this mechanism to target TPUs from XLA.
Conclusion and looking forward
XLA is still in early stages of development. It is showing very promising results for some use cases, and it is clear that TensorFlow can benefit even more from this technology in the future. We decided to release XLA to TensorFlow Github early to solicit contributions from the community and to provide a convenient surface for optimizing TensorFlow for various computing devices, as well as retargeting the TensorFlow runtime and models to run on new kinds of hardware.