By Phil Norman
Code at Scale
At Google, tens of thousands of software engineers contribute to a multi-billion-line mono-repository. This repository, stored in a system called Piper, contains the source code of shared libraries, production services, experimental programs, diagnostic and debugging tools: basically anything that's code-related.
This open approach can be very powerful. For example, if an engineer is unsure how to use a library, they can find examples just by searching. It also allows kind-hearted individuals to perform important updates across the whole repository, be that migrating to newer APIs, or following language developments such as Python 3, or Go generics.
Code, however, doesn't come for free: it's expensive to produce, but also costs real engineering time to maintain. Such maintenance cannot easily be skipped, at least if one wants to avoid larger costs later on.
But what if there were less code to maintain? Are all those lines of code really necessary?
Deletion at Scale
Any large project accumulates dead code: there's always some module that is no longer needed, or a program that was used during early development but hasn't been run in years. Indeed, entire projects are created, function for a time, and then stop being useful. Sometimes they are cleaned up, but cleanups require time and effort, and it's not always easy to justify the investment.
However, while this dead code sits around undeleted, it's still incurring a cost: the automated testing system doesn't know it should stop running dead tests; people running large-scale cleanups aren't aware that there's no point migrating this code, as it is never run anyway.
So what if we could clean up dead code automatically? That was exactly what people started thinking several years ago, during the Zürich Engineering Productivity team's annual hackathon. The Sensenmann project, named after the German word for the embodiment of Death, has been highly successful. It submits over 1000 deletion changelists per week, and has so far deleted nearly 5% of all C++ at Google.
Its goal is simple (at least, in principle): automatically identify dead code, and send code review requests ('changelists') to delete it.
What to Delete?
Google's build system, Blaze (the internal version of Bazel) helps us determine this: by representing dependencies between binary targets, libraries, tests, source files and more, in a consistent and accessible way, we're able to construct a dependency graph. This allows us to find libraries that are not linked into any binary, and propose their deletion.
That's only a small part of the problem, though: what about all those binaries? All the one-shot data migration programs, and diagnostic tools for deprecated systems? If they don't get removed, all the libraries they depend on will be kept around too.
The only real way to know if programs are useful is to check whether they're being run, so for internal binaries (programs run in Google's data centres, or on employee workstations), a log entry is written when a program runs, recording the time and which specific binary it is. By aggregating this, we get a liveness signal for every binary used in Google. If a program hasn't been used for a long time, we try sending a deletion changelist.
What Not to Delete?
There are, of course, exceptions: some program code is there simply to serve as an example of how to use an API; some programs run only in places we can't get a log signal from. There are many other exceptions too, where removing the code would be deleterious. For this reason, it's important to have a blocklisting system so that exceptions can be marked, and we can avoid bothering people with spurious changelists.
The Devel's in the Details
Consider a simple case. We have two binaries, each depending on its own library, and also on a third, shared library. Drawing this (ignoring the source files and other dependencies), we find this kind of structure:

If we see that main1 is in active use, but main2 was last used over a year ago, we can propagate the liveness signal through the build tree, marking main1 as alive along with everything it depends upon. What is left can be removed; as main2 depends on lib2, we want to delete these two targets in the same change:

So far so good, but real production code has unit tests, whose build targets depend upon the libraries they test. This immediately makes the graph traversal a lot more complicated:
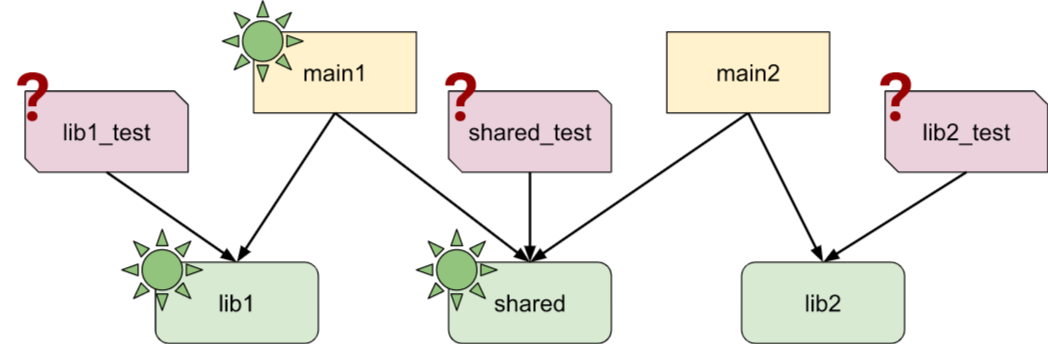
The testing infrastructure is going to run all those tests, including lib2_test, despite lib2 never being executed 'for real'. This means we cannot use test runs as a 'liveness' signal: if we did, we'd consider lib2_test to be alive, which would keep lib2 around forever. We would only be able to clean up untested code, which would severely hamper our efforts.
What we really want is for each test to share the fate of the library it is testing. We can do this by making the library and its test interdependent, thus creating loops in the graph:

This turns each library and its test into a strongly connected component. We can use the same technique as before, marking the 'live' nodes and then hunting for collections of 'dead' nodes to be deleted, but this time using Tarjan's strongly connected components algorithm to deal with the loops.
Simple, right? Well, yes, if it's easy to identify the relationships between tests and the libraries they're testing. Sadly, that is not always the case. In the examples above, there's a simple naming convention which allows us to match tests to libraries, but we can't rely on that heuristic in general.
Consider the following two cases:

On the left, we have an implementation of the LZW compression algorithm, as separate compressor and decompressor libraries. The test is actually testing both of them, to ensure data isn't corrupted after being compressed and then decompressed. On the right, we have a web_test that is testing our web server library; it uses a URL encoder library for support, but isn't actually testing the URL encoder itself. On the left, we want to consider the LZW test and both LZW libraries as one connected component, but on the right, we'd want to exclude the URL encoder and consider web_test and web_lib as the connected component.
Despite requiring different treatment, these two cases have identical structures. In practice, we can encourage engineers to mark libraries like url_encoder_lib as being 'test only' (ie. only for use to support unit testing), which can help in the web-test case; otherwise our current approach is to use the edit distance between test and library names to pick the most likely library to match to a given test. Being able to identify cases like the LZW example, with one test and two libraries, is likely to involve processing test coverage data, and has not yet been explored.
Focus on the User...
While the ultimate beneficiaries of dead code deletion are the software engineers themselves, many of whom appreciate the help in keeping their projects tidy, not everyone is happy to receive automated changelists trying to delete code they wrote. This is where the social engineering side of the project comes in, which is every bit as important as the software engineering.
Automatic code deletion is an alien concept to many engineers, and just as with the introduction of unit testing 20 years ago, many are resistent to it. It takes time and effort to change people's minds, along with a good deal of careful communication.
There are three main parts to Sensenmann's communication strategy. Of primary importance are the change descriptions, as they are the first thing a reviewer will see. They must be concise, but must provide enough background for all reviewers to be able to make a judgement. This is a difficult balance to achieve: too short, and many people will fail to find the information they need; too long, and one ends up with a wall of text no one will bother to read. Well-labelled links to supporting documentation and FAQs can really help here.
The second part is the supporting documentation. Concise and clear wording is vital here, too, as is a good navigable structure. Different people will need different information: some need reassurance that in a source control system, deletions can be rolled back; some will need guidance in how best to deal with a bad change, for example by fixing a misuse of the build system. Through careful thought, and iterations of user feedback, the supporting documentation can become a useful resource.
The third part is dealing with user feedback. This can be the hardest part at times: feedback is more frequently negative than positive, and can require a cool head and a good deal of diplomacy at times. However, accepting such feedback is the best way to improve the system in general, make users happier, and thus avoid negative feedback in the future.
Onwards and Upwards
Automatically deleting code may sound like a strange idea: code is expensive to write, and is generally considered to be an asset. However, unused code costs time and effort, whether in maintaining it, or cleaning it up. Once a code base reaches a certain size, it starts to make real sense to invest engineering time in automating the clean-up process. At Google's scale, it is estimated that automatic code deletion has paid for itself tens of times over, in saved maintenance costs.
The implementation requires solutions to problems both technical and social in nature. While a lot of progress has been made in both these areas, they are not entirely solved yet. As improvements are made, though, the rate of acceptance of the deletions increases and automatic deletion becomes more and more impactful. This kind of investment will not make sense everywhere, but if you have a huge mono-repository, maybe it'd make sense for you too. At least at Google, reducing the C++ maintenance burden by 5% is a huge win.