Memory safety in Chrome is an ever-ongoing effort to protect our users. We are constantly experimenting with different technologies to stay ahead of malicious actors. In this spirit, this post is about our journey of using heap scanning technologies to improve memory safety of C++.
Let’s start at the beginning though. Throughout the lifetime of an application its state is generally represented in memory. Temporal memory safety refers to the problem of guaranteeing that memory is always accessed with the most up to date information of its structure, its type. C++ unfortunately does not provide such guarantees. While there is appetite for different languages than C++ with stronger memory safety guarantees, large codebases such as Chromium will use C++ for the foreseeable future.
In the example above, foo is used after its memory has been returned to the underlying system. The out-of-date pointer is called a dangling pointer and any access through it results in a use-after-free (UAF) access. In the best case such errors result in well-defined crashes, in the worst case they cause subtle breakage that can be exploited by malicious actors.
UAFs are often hard to spot in larger codebases where ownership of objects is transferred between various components. The general problem is so widespread that to this date both industry and academia regularly come up with mitigation strategies. The examples are endless: C++ smart pointers of all kinds are used to better define and manage ownership on application level; static analysis in compilers is used to avoid compiling problematic code in the first place; where static analysis fails, dynamic tools such as C++ sanitizers can intercept accesses and catch problems on specific executions.
Chrome’s use of C++ is sadly no different here and the majority of high-severity security bugs are UAF issues. In order to catch issues before they reach production, all of the aforementioned techniques are used. In addition to regular tests, fuzzers ensure that there’s always new input to work with for dynamic tools. Chrome even goes further and employs a C++ garbage collector called Oilpan which deviates from regular C++ semantics but provides temporal memory safety where used. Where such deviation is unreasonable, a new kind of smart pointer called MiraclePtr was introduced recently to deterministically crash on accesses to dangling pointers when used. Oilpan, MiraclePtr, and smart-pointer-based solutions require significant adoptions of the application code.
Over the last years, another approach has seen some success: memory quarantine. The basic idea is to put explicitly freed memory into quarantine and only make it available when a certain safety condition is reached. In the Linux kernel a probabilistic approach was used where memory was eventually just recycled. A more elaborate approach uses heap scanning to avoid reusing memory that is still reachable from the application. This is similar to a garbage collected system in that it provides temporal memory safety by prohibiting reuse of memory that is still reachable. The rest of this article summarizes our journey of experimenting with quarantines and heap scanning in Chrome.
(At this point, one may ask where pointer authentication fits into this picture – keep on reading!)
Quarantining and Heap Scanning, the Basics
The main idea behind assuring temporal safety with quarantining and heap scanning is to avoid reusing memory until it has been proven that there are no more (dangling) pointers referring to it. To avoid changing C++ user code or its semantics, the memory allocator providing new and delete is intercepted.

Upon invoking delete, the memory is actually put in a quarantine, where it is unavailable for being reused for subsequent new calls by the application. At some point a heap scan is triggered which scans the whole heap, much like a garbage collector, to find references to quarantined memory blocks. Blocks that have no incoming references from the regular application memory are transferred back to the allocator where they can be reused for subsequent allocations.
There are various hardening options which come with a performance cost:
Overwrite the quarantined memory with special values (e.g. zero);
Stop all application threads when the scan is running or scan the heap concurrently;
Intercept memory writes (e.g. by page protection) to catch pointer updates;
Scan memory word by word for possible pointers (conservative handling) or provide descriptors for objects (precise handling);
Segregation of application memory in safe and unsafe partitions to opt-out certain objects which are either performance sensitive or can be statically proven as being safe to skip;
Scan the execution stack in addition to just scanning heap memory;
We call the collection of different versions of these algorithms StarScan [stɑː skæn], or *Scan for short.
Reality Check
We apply *Scan to the unmanaged parts of the renderer process and use Speedometer2 to evaluate the performance impact.
We have experimented with different versions of *Scan. To minimize performance overhead as much as possible though, we evaluate a configuration that uses a separate thread to scan the heap and avoids clearing of quarantined memory eagerly on delete but rather clears quarantined memory when running *Scan. We opt in all memory allocated with new and don’t discriminate between allocation sites and types for simplicity in the first implementation.

Note that the proposed version of *Scan is not complete. Concretely, a malicious actor may exploit a race condition with the scanning thread by moving a dangling pointer from an unscanned to an already scanned memory region. Fixing this race condition requires keeping track of writes into blocks of already scanned memory, by e.g. using memory protection mechanisms to intercept those accesses, or stopping all application threads in safepoints from mutating the object graph altogether. Either way, solving this issue comes at a performance cost and exhibits an interesting performance and security trade-off. Note that this kind of attack is not generic and does not work for all UAF. Problems such as depicted in the introduction would not be prone to such attacks as the dangling pointer is not copied around.
Since the security benefits really depend on the granularity of such safepoints and we want to experiment with the fastest possible version, we disabled safepoints altogether.
Running our basic version on Speedometer2 regresses the total score by 8%. Bummer…
Where does all this overhead come from? Unsurprisingly, heap scanning is memory bound and quite expensive as the entire user memory must be walked and examined for references by the scanning thread.
To reduce the regression we implemented various optimizations that improve the raw scanning speed. Naturally, the fastest way to scan memory is to not scan it at all and so we partitioned the heap into two classes: memory that can contain pointers and memory that we can statically prove to not contain pointers, e.g. strings. We avoid scanning memory that cannot contain any pointers. Note that such memory is still part of the quarantine, it is just not scanned.
We extended this mechanism to also cover allocations that serve as backing memory for other allocators, e.g., zone memory that is managed by V8 for the optimizing JavaScript compiler. Such zones are always discarded at once (c.f. region-based memory management) and temporal safety is established through other means in V8.
On top, we applied several micro optimizations to speed up and eliminate computations: we use helper tables for pointer filtering; rely on SIMD for the memory-bound scanning loop; and minimize the number of fetches and lock-prefixed instructions.
We also improve upon the initial scheduling algorithm that just starts a heap scan when reaching a certain limit by adjusting how much time we spent in scanning compared to actually executing the application code (c.f. mutator utilization in garbage collection literature).
In the end, the algorithm is still memory bound and scanning remains a noticeably expensive procedure. The optimizations helped to reduce the Speedometer2 regression from 8% down to 2%.
While we improved raw scanning time, the fact that memory sits in a quarantine increases the overall working set of a process. To further quantify this overhead, we use a selected set of Chrome’s real-world browsing benchmarks to measure memory consumption. *Scan in the renderer process regresses memory consumption by about 12%. It’s this increase of the working set that leads to more memory being paged in which is noticeable on application fast paths.
Hardware Memory Tagging to the Rescue
MTE (Memory Tagging Extension) is a new extension on the ARM v8.5A architecture that helps with detecting errors in software memory use. These errors can be spatial errors (e.g. out-of-bounds accesses) or temporal errors (use-after-free). The extension works as follows. Every 16 bytes of memory are assigned a 4-bit tag. Pointers are also assigned a 4-bit tag. The allocator is responsible for returning a pointer with the same tag as the allocated memory. The load and store instructions verify that the pointer and memory tags match. In case the tags of the memory location and the pointer do not match a hardware exception is raised.
MTE doesn't offer a deterministic protection against use-after-free. Since the number of tag bits is finite there is a chance that the tag of the memory and the pointer match due to overflow. With 4 bits, only 16 reallocations are enough to have the tags match. A malicious actor may exploit the tag bit overflow to get a use-after-free by just waiting until the tag of a dangling pointer matches (again) the memory it is pointing to.
*Scan can be used to fix this problematic corner case. On each delete call the tag for the underlying memory block gets incremented by the MTE mechanism. Most of the time the block will be available for reallocation as the tag can be incremented within the 4-bit range. Stale pointers would refer to the old tag and thus reliably crash on dereference. Upon overflowing the tag, the object is then put into quarantine and processed by *Scan. Once the scan verifies that there are no more dangling pointers to this block of memory, it is returned back to the allocator. This reduces the number of scans and their accompanying cost by ~16x.
The following picture depicts this mechanism. The pointer to foo initially has a tag of 0x0E which allows it to be incremented once again for allocating bar. Upon invoking delete for bar the tag overflows and the memory is actually put into quarantine of *Scan.
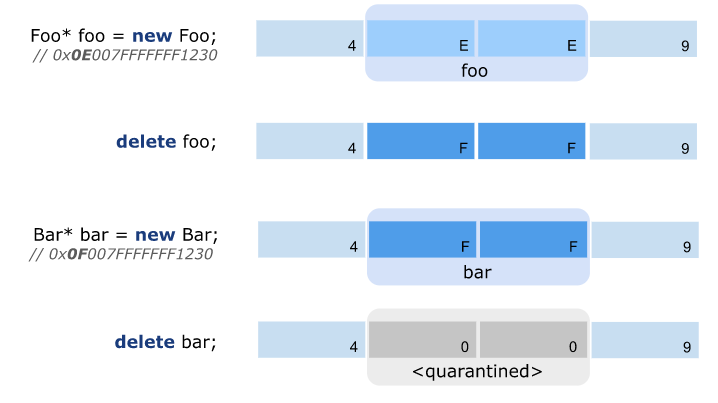
We got our hands on some actual hardware supporting MTE and redid the experiments in the renderer process. The results are promising as the regression on Speedometer was within noise and we only regressed memory footprint by around 1% on Chrome’s real-world browsing stories.
Is this some actual free lunch? Turns out that MTE comes with some cost which has already been paid for. Specifically, PartitionAlloc, which is Chrome’s underlying allocator, already performs the tag management operations for all MTE-enabled devices by default. Also, for security reasons, memory should really be zeroed eagerly. To quantify these costs, we ran experiments on an early hardware prototype that supports MTE in several configurations:
MTE disabled and without zeroing memory;
MTE disabled but with zeroing memory;
MTE enabled without *Scan;
MTE enabled with *Scan;
(We are also aware that there’s synchronous and asynchronous MTE which also affects determinism and performance. For the sake of this experiment we kept using the asynchronous mode.)

The results show that MTE and memory zeroing come with some cost which is around 2% on Speedometer2. Note that neither PartitionAlloc, nor hardware has been optimized for these scenarios yet. The experiment also shows that adding *Scan on top of MTE comes without measurable cost.
Conclusions
C++ allows for writing high-performance applications but this comes at a price, security. Hardware memory tagging may fix some security pitfalls of C++, while still allowing high performance. We are looking forward to see a more broad adoption of hardware memory tagging in the future and suggest using *Scan on top of hardware memory tagging to fix temporary memory safety for C++. Both the used MTE hardware and the implementation of *Scan are prototypes and we expect that there is still room for performance optimizations.