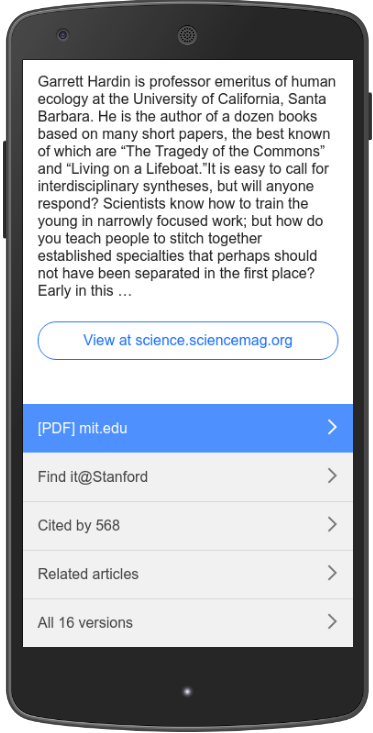
Scholar Button, released in 2015, provides easy access to Google Scholar from any webpage. You can use it to find fulltext on the web or in your university library, format references in widely used citation styles, repeat a web search in Scholar, or simply look up a reference to a paper.
We're releasing an update with several new features. The window that opens when you click Scholar Button used to look like this:
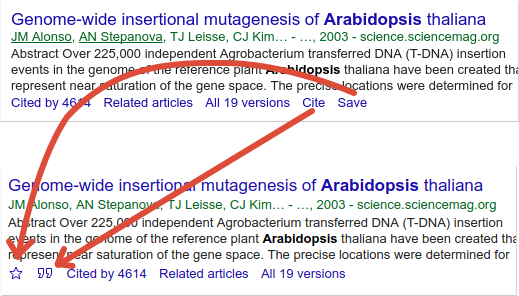
We added a "Save" star and moved the "Cite" button next to it, and added history navigation buttons to the bottom toolbar:
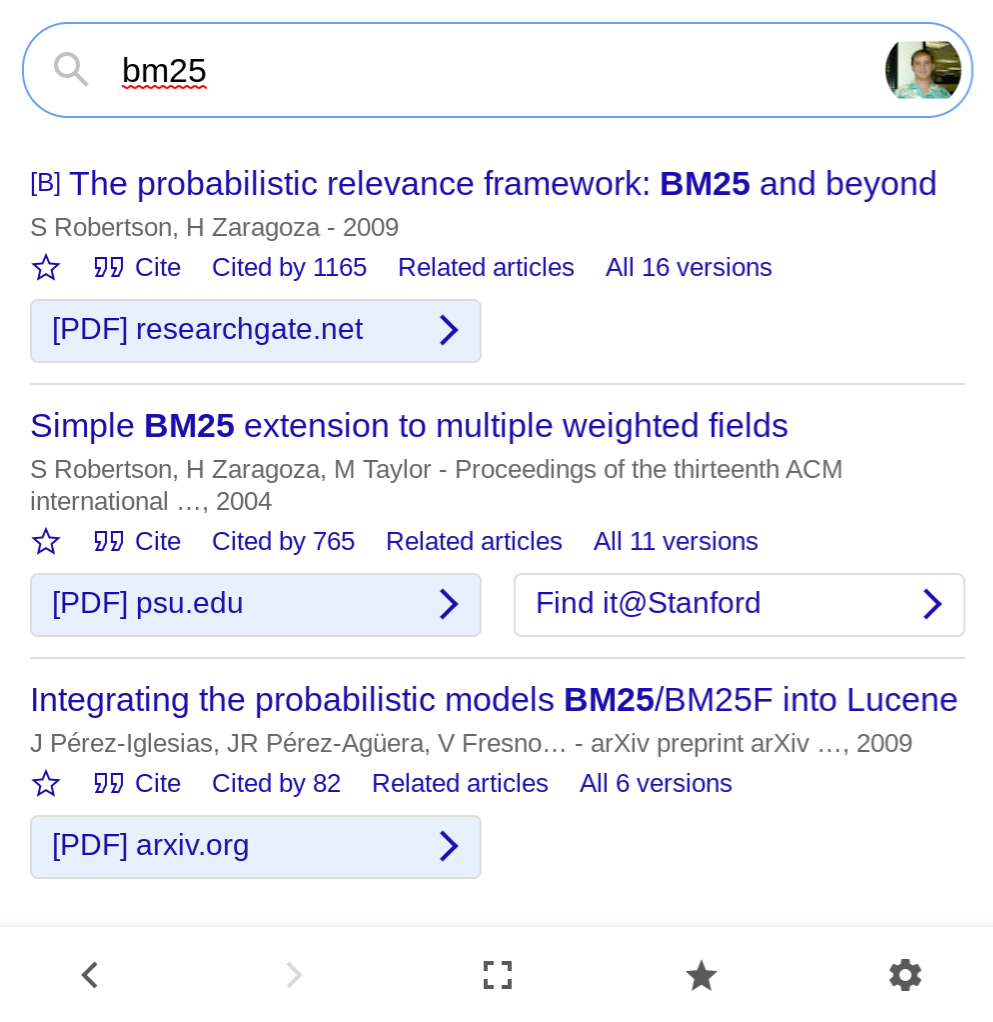
You can now save the article to read later - click the small blue star under the article to save it, or the big gray star at the bottom to see all saved articles in your Scholar library. The article is saved in your most recently accessed Scholar account; to use a different one, click the account photo in the upper right.
We've also added a back button! You can now easily undo query refinements that didn't work out, and even recover the window after you close it - just open it again and click back. Your Scholar Button history is stored locally in your browser for an hour; click the account photo in the upper right to clear it right away.
Finally, we have improved how Scholar Button identifies the webpage you're reading. Clicking the button while reading a PDF article should now find the article in Scholar, so you can cite it, save it, or explore related articles. If Scholar Button doesn't find the right article, please select its title on the webpage.
Scholar Button is currently available for Chrome and Firefox.
Posted by Belinda Shi, Kyu Jin Hwang, and Alex Verstak.