Posted by Alexander Dupuy, Software EngineerOnce upon a time, we
launched Google Public DNS, which you might know by its iconic IP address, 8.8.8.8. (Sunday, August 12th, 2018, at 00:30 UTC marks eight years, eight months, eight days and eight hours since the announcement.) Though not as well-known as Google Search or Gmail, the four eights have had quite a journey—and some pretty amazing growth! Whether it’s
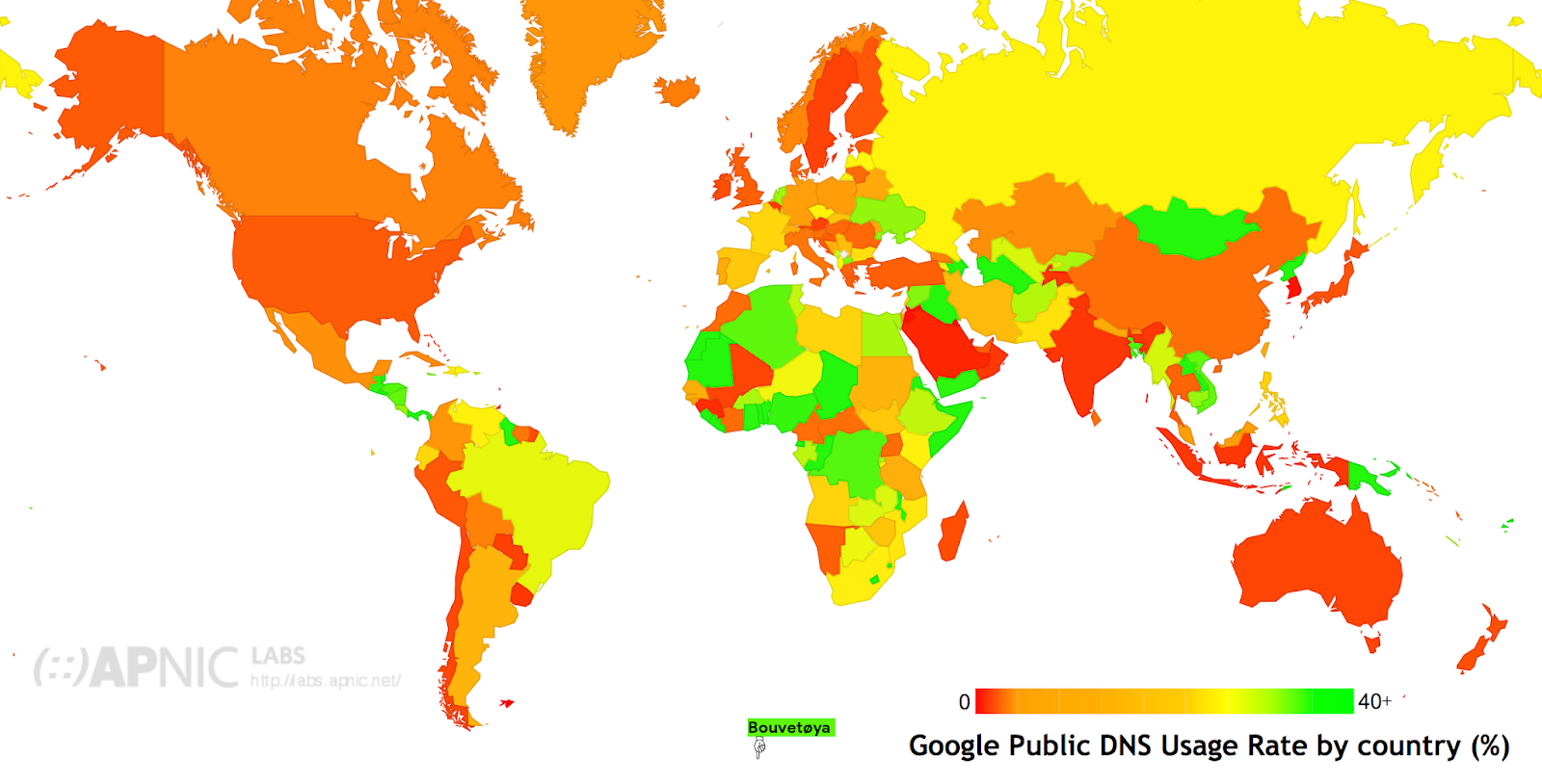
travelers in India’s train stations or
researchers on the remote Antarctic island Bouvetøya, hundreds of millions of people the world over rely on our free DNS service to turn domain names like wikipedia.org into IP addresses like 208.80.154.224.
 |
| Google Public DNS query growth and major feature launches |
Today, it’s estimated that about
10% of internet users rely on 8.8.8.8, and it serves well over a trillion queries per day. But while we’re really proud of that growth, what really matters is whether it’s a valuable service for our users. Namely, has Google Public DNS made the internet faster for users? Does it safeguard their privacy? And does it help them get to internet sites more reliably and securely?
In other words, has 8.8.8.8 made DNS and the internet better as a whole? Here at Google, we think it has. On this numerological anniversary, let’s take a look at how Google Public DNS has realized those goals and what lies ahead.
Making the internet fasterFrom the start, a key goal of Google Public DNS was to
make the internet faster. When we began the project in 2007, Google had already made it faster to search the web, but it could take a while to get to your destination. Back then, most DNS lookups used your ISP’s resolvers, and with small caches, they often had to make multiple DNS queries before they could return an address.
Google Public DNS resolvers’ DNS caches hold tens of billions of entries worldwide. And because hundreds of millions of clients use them every day, they usually return the address for your domain queries without extra lookups, connecting you to the internet that much faster.
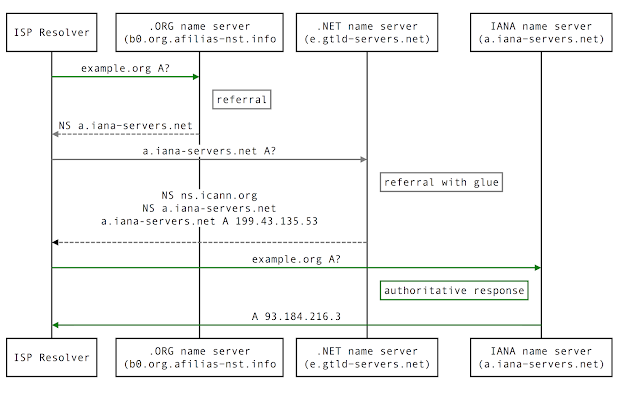 |
| DNS resolution process for example.org |
Speeding up DNS responses is just one part of making the web faster—getting web content from servers closer to you can have an even bigger impact. Content Delivery Networks (CDNs) distribute large, delay-sensitive content like streaming videos to users around the world. CDNs use DNS to direct users to the nearest servers, and rely on
GeoIP maps to determine the best location.
Everything’s good if your DNS query comes from an ISP resolver that is close to you, but what happens if the resolver is far away, as it is for researchers on Bouvetøya? In that case, the CDN directs you to a server near the DNS resolver—but not the one closest to you. In 2010, along with other DNS and CDN services, we
proposed a solution that lets DNS resolvers send part of your IP address in their DNS queries, so CDN name servers can get your best possible GeoIP location (short of sending your entire IP address). By sending only the first three parts of users’ IP addresses (e.g. 192.0.2.x) in the EDNS Client Subnet (ECS) extension, CDNs can return the closest content while maintaining user privacy.
We continue to enhance ECS, (now published as
RFC 7871), for example, by adding
automatic detection of name server ECS support. And today, we’re happy to report, support for ECS is widespread among CDNs.
Safeguarding user privacy
From day one of our service, we’ve always been serious about user privacy. Like all Google services, we honor the general Google
Privacy Policy, and are guided by Google’s
Privacy Principles. In addition, Google Public DNS published a
privacy practice statement about the information we collect and how it is used—and how it’s not used. These protect the privacy of your DNS queries once they arrive at Google, but they can still be seen (and potentially modified) en route to 8.8.8.8.
To address this weakness, we
launched a public beta of
DNS-over-HTTPS on April 1, 2016, embedding your DNS queries in the secure and private HTTPS protocol. Despite the launch date, this was not an April Fool’s joke, and in the following two years, it has grown dramatically, with millions of users and support by another major public DNS service. Today, we are working in the IETF and with other DNS operators and clients on the
Internet Draft for DNS Queries over HTTPS specification, which we also support.
Securing the Domain Name SystemWe’ve always been very concerned with the integrity and security of the responses that Google Public DNS provides. From the start, we
rejected the practice of
hijacking nonexistent domain (NXDOMAIN) responses, working to provide users with accurate and honest DNS responses, even when attackers tried to corrupt them.
In 2008, Dan Kaminsky publicized a major security weakness in the DNS protocol that left most DNS resolvers vulnerable to spoofing that poisoned their DNS caches. When we launched 8.8.8.8 the following year, we not only used industry best practices to mitigate this vulnerability, but also developed an
extensive set of additional protections.
While those protected our DNS service from most attackers, they can’t help in cases where an attacker can see our queries. Starting in 2010, the internet started to use
DNSSEC security in earnest, making it possible to protect cryptographically signed domains against such
man-in-the-middle and
man-on-the-side attacks. In 2013, Google Public DNS became the first major public DNS resolver to
implement DNSSEC validation for all its DNS queries,
doubling the percentage of end users protected by DNSSEC from 3.3% to 8.1%.
In addition to protecting the integrity of DNS responses, Google Public DNS also works to block DNS denial of service attacks by
rate limiting both our queries to name servers and
reflection or amplification attacks that try to flood victims’ network connections.
Internet access for all
A big part of Google Public DNS’s tremendous growth comes from free public internet services. We make the internet faster for hundreds of these services, from free WiFi in San Francisco’s parks to LinkNYC internet kiosk hotspots and the
Railtel partnership in India‘s train stations. In places like Africa and Southeast Asia, many ISPs also use 8.8.8.8 to resolve their users’ DNS queries. Providing free DNS resolution to anyone in the world, even to other companies, supports internet access worldwide as a part of Google’s
Next Billion Users initiative.
Looking ahead
Today, Google Public DNS is the largest public DNS resolver. There are now about a dozen such services providing value-added features like content and malware filtering, and recent entrants Quad9 and Cloudflare also provide privacy for DNS queries over TLS or HTTPS.
But recent incidents that used BGP hijacking to attack DNS are concerning. Increasing the adoption and use of DNSSEC is an effective way to protect against such attacks and as the largest DNSSEC validating resolver, we hope we can influence things in that direction. We are also exploring how to improve the security of the path from resolvers to authoritative name servers—issues not currently addressed by other DNS standards.
In short, we continue to improve Google Public DNS both behind the scenes and in ways visible to users, adding features that users want from their DNS service. Stay tuned for some exciting Google Public DNS announcements in the near future!