Today, Google announced Allo — our new mobile messaging app. From day one of the Allo development effort, we set out to build a truly special product that is powered by Google’s strengths in machine intelligence to make messaging easier, more efficient, and more expressive. Photo Reply is a unique feature of Allo that just does that! We use machine learning to understand what a shared photo depicts and to suggest rich natural language replies that the user can tap to send. This makes it easier for users to sustain meaningful conversations while using small mobile keyboards.
Here is an example of the responses that Allo suggests when a friend shares a photo of his child.
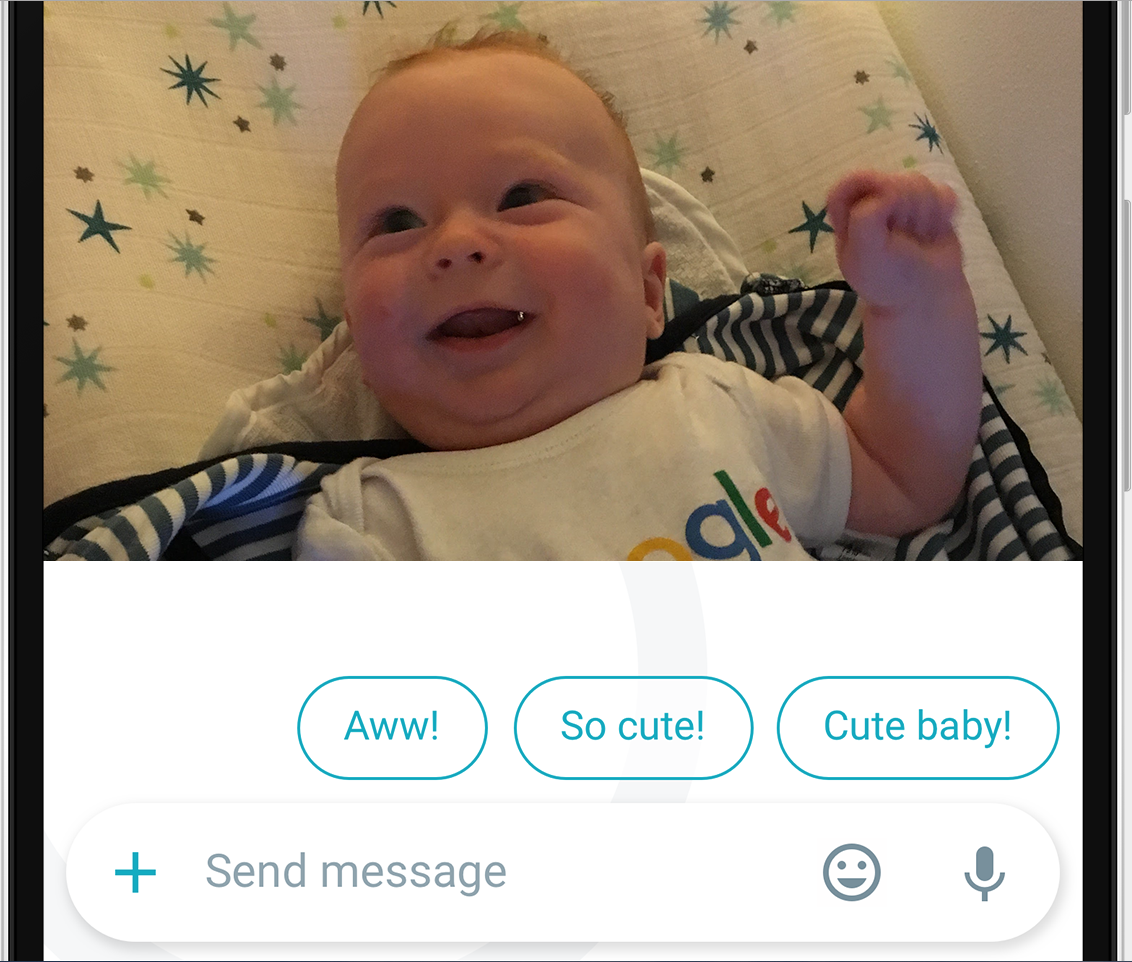
During the winter, our product managers, Patrick McGregor and Ryan Cassidy, challenged us to develop new approaches to simplify media sharing in messaging while simultaneously delighting users with Google insights. With my colleagues Vivek Ramavajjala, Sergey Nazarov, and Sujith Ravi, we set out to build Photo Reply.
We utilize Google's image recognition technology, developed by our Machine Perception team, to associate images with semantic entities — people, animals, cars, etc. We then apply a machine learned model that maps those recognized entities to actual natural language responses. Our system produces replies for thousands of entity types that are drawn from a taxonomy that is a subset of Google's Knowledge Graph and may be at different granularity levels. For example, when you receive a photo of a dog, the system may detect that the dog is actually a labrador and suggest "Love that lab!". Or given a photo of a pasta dish, it may detect the type of pasta ("Yum linguine!") and even the cuisine ("I love Italian food!").
 |
| Examples of response suggestions reflecting fine-grained object classes |
 |
| Response suggestions reflecting abstract concepts |
At runtime, Photo Reply recognizes entities in the shared photo and triggers responses for the entities. The model that maps entities to natural language responses is learned offline using Expander, which is a large-scale graph-based semi-supervised learning platform at Google. We built a massive a graph where nodes correspond to photos, semantic entities, and textual responses. Edges in the graph indicate when an entity was recognized for a photo, when a specific response was given for a photo, and visual similarities between photos. Some of the nodes are "labeled" and we learn associations for the unlabeled nodes by propagating label information across the graph.
To illustrate this, consider the graph below. There are two labels: the red label corresponds to the response "yummy" and the blue label corresponds to "delicious". The nodes for "spaghetti" and "linguine" are unlabeled, but from the fact that they are close to the red and blue nodes, the algorithm can learn that they should be associated to the "yummy" and "delicious" responses. Notice that in this way, we are associating the entity "linguine" to the response "yummy" even though none of the linguine photos in the graph are directly connected to this answer. Expander can perform this kind of learning at very large scale, for graphs containing billions of nodes and hundred of billions of edges.
 |
| Graph of entities, photos, and responses |
