Most people spend a significant amount of time each day using mobile-device keyboards: composing emails, texting, engaging in social media, and more. Yet, mobile keyboards are still cumbersome to handle. The average user is roughly 35% slower typing on a mobile device than on a physical keyboard. To change that, we recently provided many exciting improvements to Gboard for Android, working towards our vision of creating an intelligent mechanism that enables faster input while offering suggestions and correcting mistakes, in any language you choose.
With the realization that the way a mobile keyboard translates touch inputs into text is similar to how a speech recognition system translates voice inputs into text, we leveraged our experience in Speech Recognition to pursue our vision. First, we created robust spatial models that map fuzzy sequences of raw touch points to keys on the keyboard, just like acoustic models map sequences of sound bites to phonetic units. Second, we built a powerful core decoding engine based on finite state transducers (FST) to determine the likeliest word sequence given an input touch sequence. With its mathematical formalism and broad success in speech applications, we knew that an FST decoder would offer the flexibility needed to support a variety of complex keyboard input behaviors as well as language features. In this post, we will detail what went into the development of both of these systems.
Neural Spatial Models
Mobile keyboard input is subject to errors that are generally attributed to “fat finger typing” (or tracing spatially similar words in glide typing, as illustrated below) along with cognitive and motor errors (manifesting in misspellings, character insertions, deletions or swaps, etc). An intelligent keyboard needs to be able to account for these errors and predict the intended words rapidly and accurately. As such, we built a spatial model for Gboard that addresses these errors at the character level, mapping the touch points on the screen to actual keys.
 |
| Average glide trails for two spatially-similar words: “Vampire” and “Value”. |
However, training this model turned out to be a lot more complicated than we had anticipated. While acoustic models are trained from human-transcribed audio data, one cannot easily transcribe millions of touch point sequences and glide traces. So the team exploited user-interaction signals, e.g. reverted auto-corrections and suggestion picks as negative and positive semi-supervised learning signals, to form rich training and test sets.
 |
| Raw data points corresponding to the word “could” (left), and normalized sampled trajectory with per-sample variances (right). |
Finite-State Transducers
While the NSM uses spatial information to help determine what was tapped or swiped, there are additional constraints — lexical and grammatical — that can be brought to bear. A lexicon tells us what words occur in a language and a probabilistic grammar tells us what words are likely to follow other words. To encode this information we use finite-state transducers. FSTs have long been a key component of Google’s speech recognition and synthesis systems. They provide a principled way to represent various probabilistic models (lexicons, grammars, normalizers, etc) used in natural language processing together with the mathematical framework needed to manipulate, optimize, combine and search the models*.
In Gboard, a key-to-word transducer compactly represents the keyboard lexicon as shown in the figure below. It encodes the mapping from key sequences to words, allowing for alternative key sequences and optional spaces.
 |
| This transducer encodes “I”, “I’ve”, “If” along paths from the start state (the bold circle 1) to final states (the double circle states 0 and 1). Each arc is labeled with an input key (before the “:”) and a corresponding output word (after the “:”) where ε encodes the empty symbol. The apostrophe in “I’ve” can be omitted. The user may skip the space bar sometimes. To account for that, the space key transition between words in the transducer is optional. The ε and space back arcs allow accepting more than one word. |
Generic FST principles, such as streaming, support for dynamic models, etc took us a long way towards building a new keyboard decoder, but several new functionalities also had to be added. When you speak, you don’t need the decoder to complete your words or guess what you will say next to save you a few syllables; but when you type, you appreciate the help of word completions and predictions. Also, we wanted the keyboard to provide seamless multilingual support, as shown below.
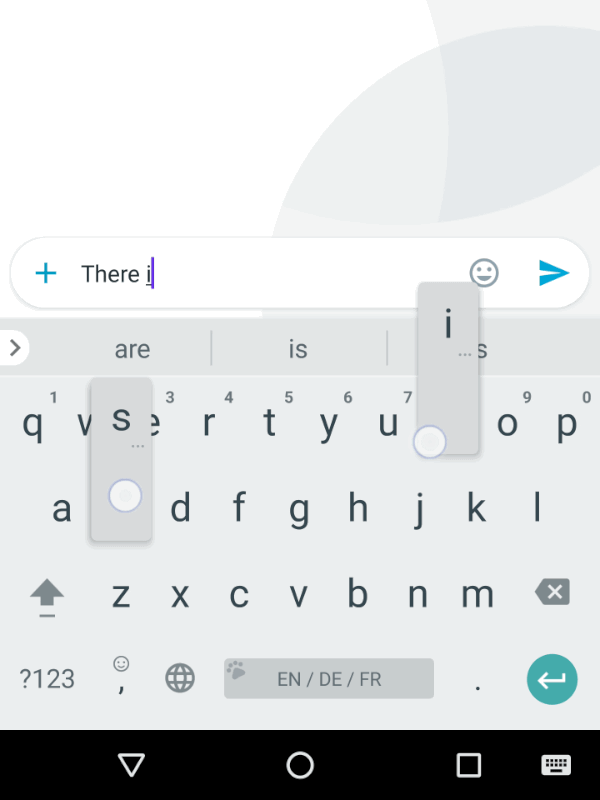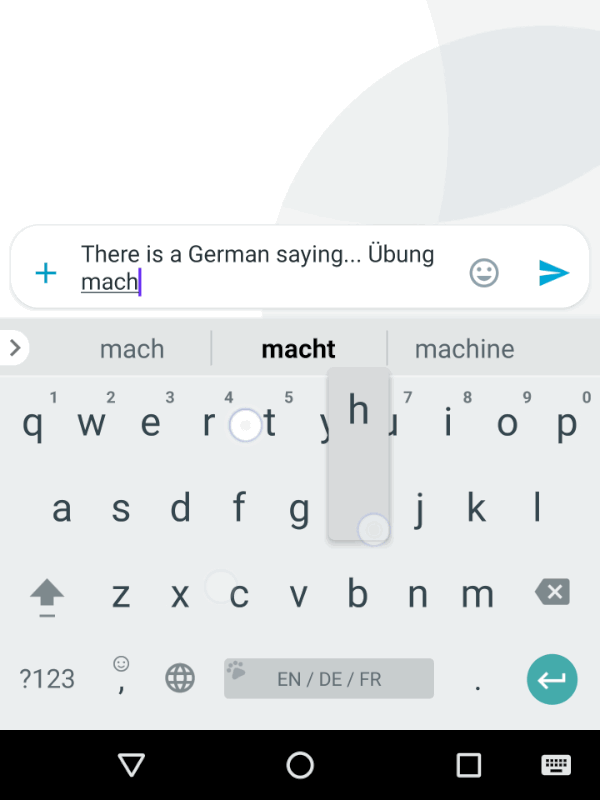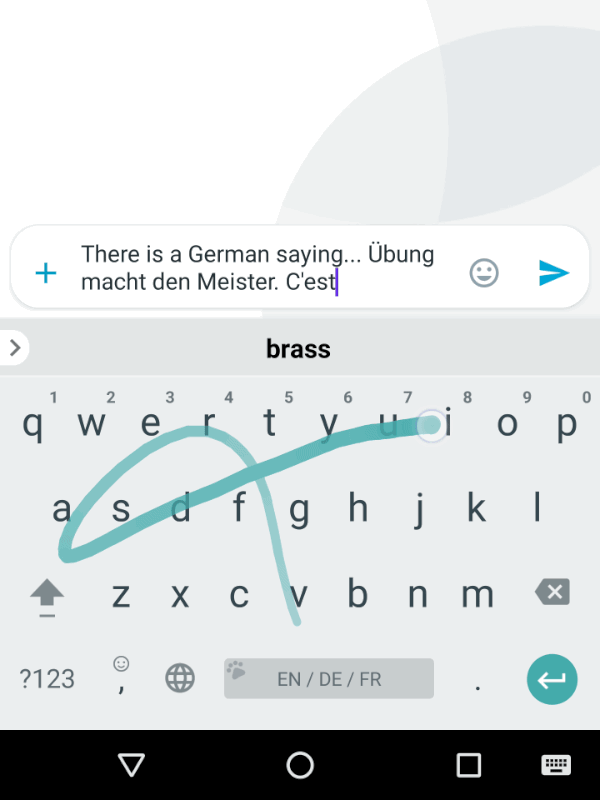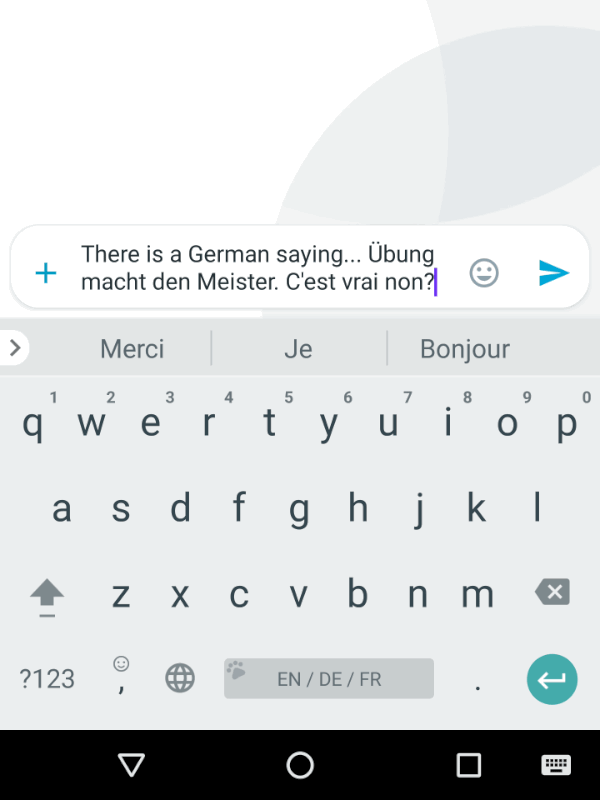 |
| Trilingual input typing in Gboard. |
Transliteration Models
In many languages with complex scripts, romanization systems have been developed to map characters into the Latin alphabet, often according to their phonetic pronunciations. For example, the Pinyin “xièxiè” corresponds to the Chinese characters “谢谢” (“thank you”). A Pinyin keyboard allows users to conveniently type words on a QWERTY layout and have them automatically “translated” into the target script. Likewise, a transliterated Hindi keyboard allows users to type “daanth” for “दांत” (teeth). Whereas Pinyin is an agreed-upon romanization system, Hindi transliterations are more fuzzy; for example “daant” would be a valid alternative for “दांत”.
 |
| Transliterated glide input for Hindi. |
The general nature of the FST decoder let us leverage all the work we had done to support completions, predictions, glide typing and many UI features with no extra effort, allowing us to offer a rich experience to our Indian users right from the start.
A More Intelligent Keyboard
All in all, our recent work cut the decoding latency by 50%, reduced the fraction of words users have to manually correct by more than 10%, allowed us to launch transliteration support for the 22 official languages of India, and enabled many new features you may have noticed.
While we hope that these recent changes improve your typing experience, we recognize that on-device typing is by no means solved. Gboard can still make suggestions that seem nonintuitive or of low utility and gestures can still be decoded to words a human would never pick. However, our shift towards powerful machine intelligence algorithms has opened new spaces that we’re actively exploring to make more useful tools and products for our users worldwide.
Acknowledgments
This work was done by Cyril Allauzen, Ouais Alsharif, Lars Hellsten, Tom Ouyang, Brian Roark and David Rybach, with help from Speech Data Operation team. Special thanks go to Johan Schalkwyk and Corinna Cortes for their support.
* The toolbox of relevant algorithms is available in the OpenFst open-source library.↩
