Today, we are introducing regional replication for Google Cloud Bigtable, our low latency, massively scalable NoSQL database for analytical and operational workloads. You can now easily replicate your Cloud Bigtable data set asynchronously across zones within a Google Cloud Platform (GCP) region, for additional read throughput, higher durability, and resilience in the face of zonal failures.
Cloud Bigtable is a great database service when you need low latency, random data access and scalability. Cloud Bigtable separates compute from storage, allowing its clusters to seamlessly scale and increase read/write throughput as needed. Common use cases for Cloud Bigtable with replication include storing data for ad-tech, monitoring, IoT, time series, user analytics, and recommendation workloads.
MessageBird is a communications platform company that connects enterprises to their global customers via SMS, Voice and Chat APIs. MessageBird uses Cloud Bigtable to store and retrieve text messages to support its SMS functionality, and is an early adopter of Cloud Bigtable replication:
“Cloud Bigtable replication helps us simplify replication setup where we don't have to do the dirty work ourselves. Most importantly, it saves us development time and gives us peace of mind that our data is safely and correctly replicated.”
— Aleksandar Aleksandrov, Data Engineer, MessageBird
Getting started
To get started with replication, create a Cloud Bigtable instance with two clusters. First, make sure the first cluster is in a region that offers Cloud Bigtable in at least two zones. In this example, we've chosen us-west1-b: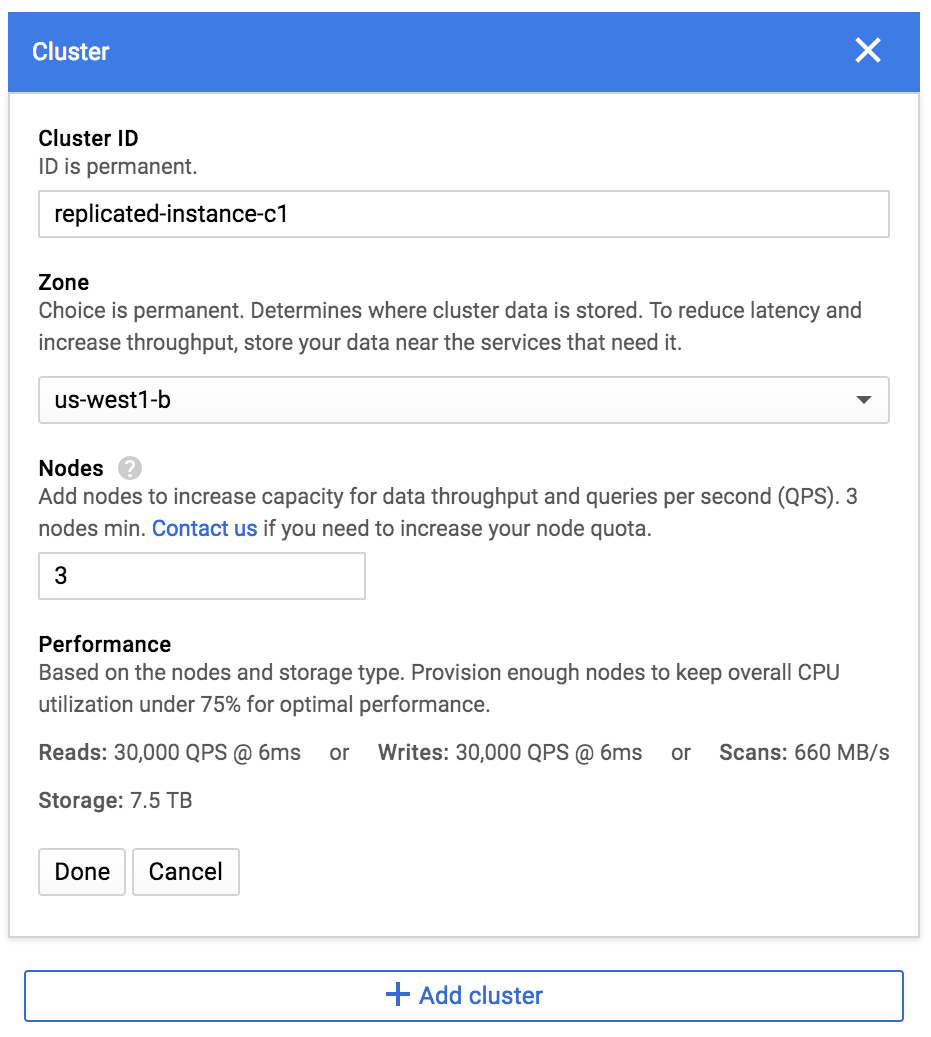
Next, click Add cluster and set up your second cluster. We'll put this one in us-west1-c:
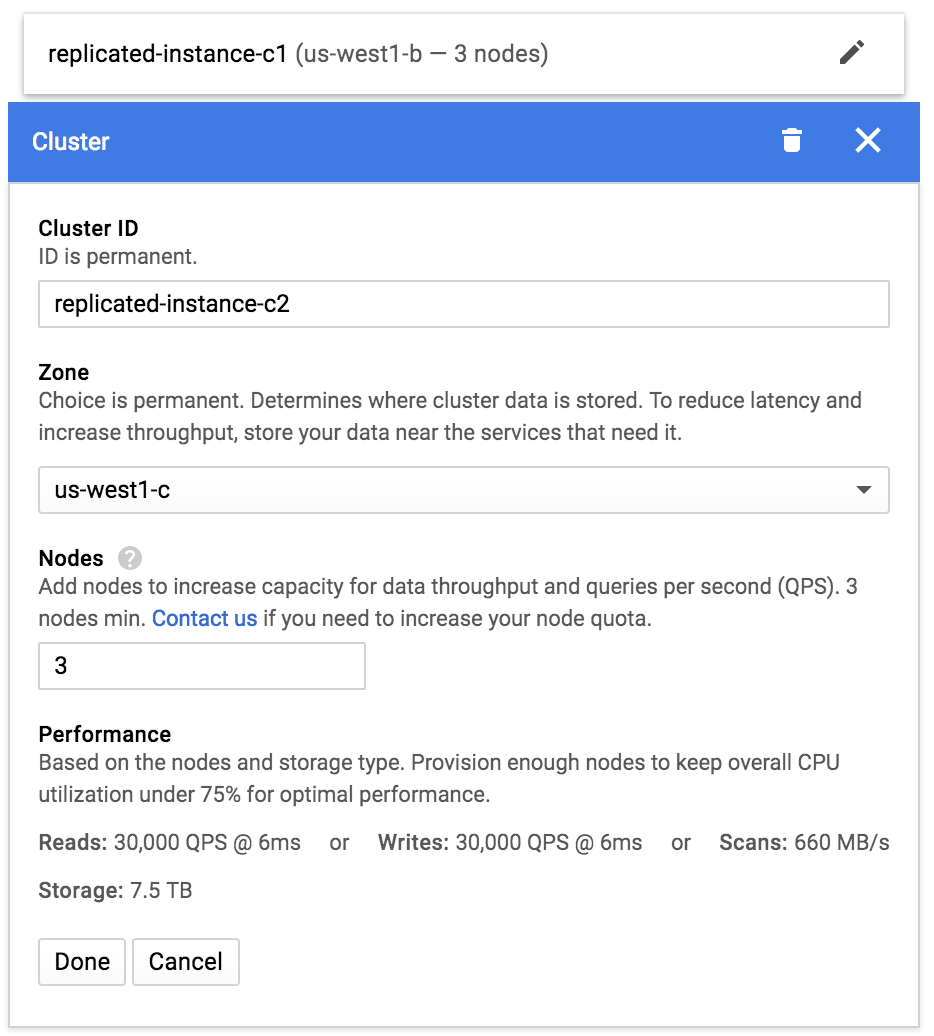
After you set up your clusters, click Create. Cloud Bigtable creates your instance and automatically enables bidirectional asynchronous replication between the two clusters.
You can also add replication to an existing instance, as long as it's in a region that offers Cloud Bigtable in at least two zones. Start by opening your list of instances and clicking the instance you want to update, then clicking Edit instance. You'll see your existing cluster, with an Add cluster button underneath:
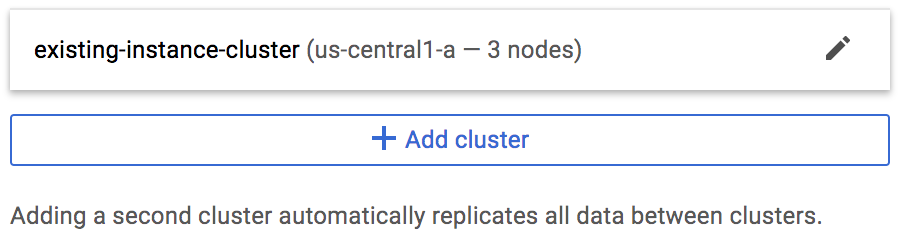
Click Add cluster and configure your second cluster, then click Save. Cloud Bigtable adds the cluster and immediately starts bidirectional replication between the two clusters.
If you've already stored a lot of data in Cloud Bigtable, it may take a little while to replicate all of your data to the new cluster. You can keep track of the status of the initial bulk copy by opening your list of instances and clicking the instance you're interested in, then looking at the "Tables available" metric in the Overview tab:

Once all of your tables are available in both clusters, you can keep track of the ongoing replication latency by clicking the Monitoring tab to view graphs for the instance:

Then, in the View metrics for drop-down list, select Replication to see the current replication latency:

Next steps
Now that you've gotten started with replication, you'll probably want to make some configuration changes to make sure you're using it effectively. We've provided detailed instructions to show you the right settings to use for common use cases, such as increasing availability and separating different kinds of traffic.Here are a few other documentation links that might be useful:
- Overview of Replication walks through the core concepts behind replication for Cloud Bigtable
- Application Profiles explains what app profiles are, what they do, and how they work
- Creating an Instance provides detailed instructions for creating an instance with the GCP Console or from the command line
- Adding a Cluster describes how to enable replication by adding a second cluster to an existing instance
If you’re building applications that need to support high availability, you know how important it is to be able to replicate data between zones, and we’re thrilled to bring that capability to Cloud Bigtable customers.
