(Crossposted on the Google Open Source Blog)
Last year, we announced Google Neural Machine Translation (GNMT), a sequence-to-sequence (“seq2seq”) model which is now used in Google Translate production systems. While GNMT achieved huge improvements in translation quality, its impact was limited by the fact that the framework for training these models was unavailable to external researchers.
Today, we are excited to introduce tf-seq2seq, an open source seq2seq framework in TensorFlow that makes it easy to experiment with seq2seq models and achieve state-of-the-art results. To that end, we made the tf-seq2seq codebase clean and modular, maintaining full test coverage and documenting all of its functionality.
Our framework supports various configurations of the standard seq2seq model, such as depth of the encoder/decoder, attention mechanism, RNN cell type, or beam size. This versatility allowed us to discover optimal hyperparameters and outperform other frameworks, as described in our paper, “Massive Exploration of Neural Machine Translation Architectures.”
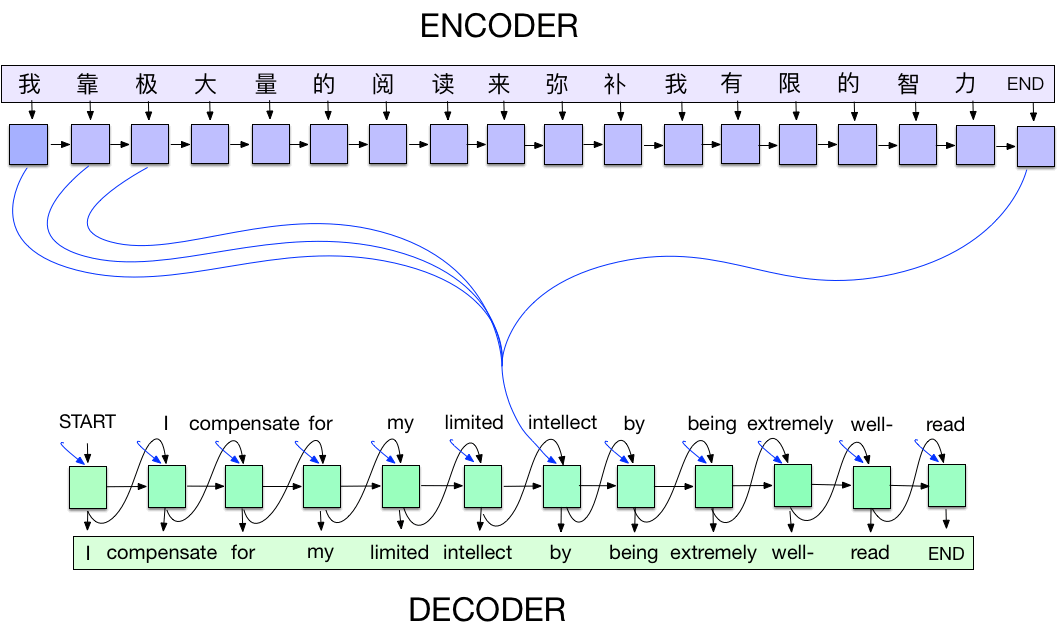 |
| A seq2seq model translating from Mandarin to English. At each time step, the encoder takes in one Chinese character and its own previous state (black arrow), and produces an output vector (blue arrow). The decoder then generates an English translation word-by-word, at each time step taking in the last word, the previous state, and a weighted combination of all the outputs of the encoder (aka attention [3], depicted in blue) and then producing the next English word. Please note that in our implementation we use wordpieces [4] to handle rare words. |
We hope that you will use tf-seq2seq to accelerate (or kick off) your own deep learning research. We also welcome your contributions to our GitHub repository, where we have a variety of open issues that we would love to have your help with!
Acknowledgments:
We’d like to thank Eugene Brevdo, Melody Guan, Lukasz Kaiser, Quoc V. Le, Thang Luong, and Chris Olah for all their help. For a deeper dive into how seq2seq models work, please see the resources below.
References:
[1] Massive Exploration of Neural Machine Translation Architectures, Denny Britz, Anna Goldie, Minh-Thang Luong, Quoc Le
[2] Sequence to Sequence Learning with Neural Networks, Ilya Sutskever, Oriol Vinyals, Quoc V. Le. NIPS, 2014
[3] Neural Machine Translation by Jointly Learning to Align and Translate, Dzmitry Bahdanau, Kyunghyun Cho, Yoshua Bengio. ICLR, 2015
[4] Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation, Yonghui Wu, Mike Schuster, Zhifeng Chen, Quoc V. Le, Mohammad Norouzi, Wolfgang Macherey, Maxim Krikun, Yuan Cao, Qin Gao, Klaus Macherey, Jeff Klingner, Apurva Shah, Melvin Johnson, Xiaobing Liu, Łukasz Kaiser, Stephan Gouws, Yoshikiyo Kato, Taku Kudo, Hideto Kazawa, Keith Stevens, George Kurian, Nishant Patil, Wei Wang, Cliff Young, Jason Smith, Jason Riesa, Alex Rudnick, Oriol Vinyals, Greg Corrado, Macduff Hughes, Jeffrey Dean. Technical Report, 2016
[5] Attention and Augmented Recurrent Neural Networks, Chris Olah, Shan Carter. Distill, 2016
[6] Neural Machine Translation and Sequence-to-sequence Models: A Tutorial, Graham Neubig
[7] Sequence-to-Sequence Models, TensorFlow.org
