Today, we’re excited to announce the public beta for Cloud Spanner, a globally distributed relational database service that lets customers have their cake and eat it too: ACID transactions and SQL semantics, without giving up horizontal scaling and high availability.
When building cloud applications, database administrators and developers have been forced to choose between traditional databases that guarantee transactional consistency, or NoSQL databases that offer simple, horizontal scaling and data distribution. Cloud Spanner breaks that dichotomy, offering both of these critical capabilities in a single, fully managed service.
“Cloud Spanner presents tremendous value for our customers who are retailers, manufacturers and wholesale distributors around the world. With its ease of provisioning and scalability, it will accelerate our ability to bring cloud-based omni-channel supply chain solutions to our users around the world,” — John Sarvari, Group Vice President of Technology, JDAJDA, a retail and supply chain software leader, has used Google Cloud Platform (GCP) as the basis of its new application development and delivery since 2015 and was an early user of Cloud Spanner. The company saw its potential to handle the explosion of data coming from new information sources such as IoT, while providing the consistency and high availability needed when using this data.
Cloud Spanner rounds out our portfolio of database services on GCP, alongside Cloud SQL, Cloud Datastore and Cloud Bigtable.
As a managed service, Cloud Spanner provides key benefits to DBAs:
- Focus on your application logic instead of spending valuable time managing hardware and software
- Scale out your RDBMS solutions without complex sharding or clustering
- Gain horizontal scaling without migration from relational to NoSQL databases
- Maintain high availability and protect against disaster without needing to engineer a complex replication and failover infrastructure
- Gain integrated security with data-layer encryption, identity and access management and audit logging
With Cloud Spanner, your database scales up and down as needed, and you'll only pay for what you use. It features a simple pricing model that charges for compute node-hours, actual storage consumption (no pre-provisioning) and external network access.
Cloud Spanner keeps application development simple by supporting standard tools and languages in a familiar relational database environment. It’s ideal for operational workloads supported by traditional relational databases, including inventory management, financial transactions and control systems, that are outgrowing those systems. It supports distributed transactions, schemas and DDL statements, SQL queries and JDBC drivers and offers client libraries for the most popular languages, including Java, Go, Python and Node.js.
More Cloud Spanner customers share feedback
Quizlet, an online learning tool that supports more than 20 million students and teachers each month, uses MySQL as its primary database; database performance and stability are critical to the business. But with users growing at roughly 50% a year, Quizlet has been forced to scale its database many times to handle this load. By splitting tables into their own databases (vertical sharding), and moving query load to replicas, it’s been able to increase query capacity — but this technique is reaching its limits quickly, as the tables themselves are outgrowing what a single MySQL shard can support. In its search for a more scalable architecture, Quizlet discovered Cloud Spanner, which will allow it to easily scale its relational database and simplify its application:“Based on our experience and performance testing, Cloud Spanner is the most compelling option we’ve seen to power a high-scale relational query workload. It has the performance and scalability of a NoSQL database, but can execute SQL so it’s a viable alternative to sharded MySQL. It’s an impressive technology and could dramatically simplify how we manage our databases.” — Peter Bakkum, Platform Lead, Quizlet
The history of Spanner
For decades, developers have relied on traditional databases with a relational data model and SQL semantics to build applications that meet business needs. Meanwhile, NoSQL solutions emerged that were great for scale and fast, efficient data-processing, but they didn’t meet the need for strong consistency. Faced with these two sub-optimal choices that customers grapple with today, in 2007, a team of systems researchers and engineers at Google set out to develop a globally-distributed database that could bridge this gap. In 2012, we published the Spanner research paper that described many of these innovations. The result was a database that offers the best of both worlds: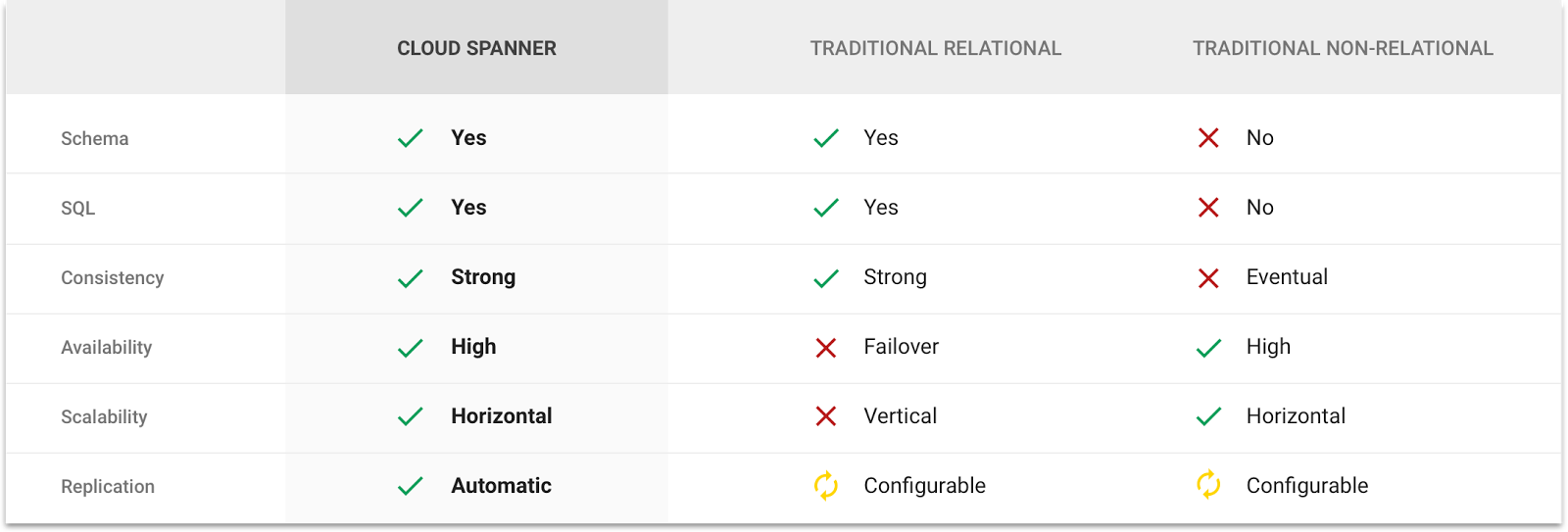 |
| (click to enlarge) |
Remarkably, Cloud Spanner achieves this combination of features without violating the CAP Theorem. To understand how, read this post by the author of the CAP Theorem and Google Vice President of Infrastructure, Eric Brewer.
Over the years, we’ve battle-tested Spanner internally with hundreds of different applications and petabytes of data across data centers around the world. At Google, Spanner supports tens of millions of queries per second and runs some of our most critical services, including AdWords and Google Play.
If you have a MySQL or PostgreSQL system that's bursting at the seams, or are struggling with hand-rolled transactions on top of an eventually-consistent database, Cloud Spanner could be the solution you're looking for. Visit the Cloud Spanner page to learn more and get started building applications on our next-generation database service.
