Machine learning (ML) models are becoming increasingly valuable for improved performance across a variety of consumer products, from recommendations to automatic image classification. However, despite aggregating large amounts of data, in theory it is possible for models to encode characteristics of individual entries from the training set. For example, experiments in controlled settings have shown that language models trained using email datasets may sometimes encode sensitive information included in the training data and may have the potential to reveal the presence of a particular user’s data in the training set. As such, it is important to prevent the encoding of such characteristics from individual training entries. To these ends, researchers are increasingly employing federated learning approaches.
Differential privacy (DP) provides a rigorous mathematical framework that allows researchers to quantify and understand the privacy guarantees of a system or an algorithm. Within the DP framework, privacy guarantees of a system are usually characterized by a positive parameter ε, called the privacy loss bound, with smaller ε corresponding to better privacy. One usually trains a model with DP guarantees using DP-SGD, a specialized training algorithm that provides DP guarantees for the trained model.
However training with DP-SGD typically has two major drawbacks. First, most existing implementations of DP-SGD are inefficient and slow, which makes it hard to use on large datasets. Second, DP-SGD training often significantly impacts utility (such as model accuracy) to the point that models trained with DP-SGD may become unusable in practice. As a result most DP research papers evaluate DP algorithms on very small datasets (MNIST, CIFAR-10, or UCI) and don’t even try to perform evaluation of larger datasets, such as ImageNet.
In “Toward Training at ImageNet Scale with Differential Privacy”, we share initial results from our ongoing effort to train a large image classification model on ImageNet using DP while maintaining high accuracy and minimizing computational cost. We show that the combination of various training techniques, such as careful choice of the model and hyperparameters, large batch training, and transfer learning from other datasets, can significantly boost accuracy of an ImageNet model trained with DP. To substantiate these discoveries and encourage follow-up research, we are also releasing the associated source code.
Testing Differential Privacy on ImageNet
We choose ImageNet classification as a demonstration of the practicality and efficacy of DP because: (1) it is an ambitious task for DP, for which no prior work shows sufficient progress; and (2) it is a public dataset on which other researchers can operate, so it represents an opportunity to collectively improve the utility of real-life DP training. Classification on ImageNet is challenging for DP because it requires large networks with many parameters. This translates into a significant amount of noise added into the computation, because the noise added scales with the size of the model.
Scaling Differential Privacy with JAX
Exploring multiple architectures and training configurations to research what works for DP can be debilitatingly slow. To streamline our efforts, we used JAX, a high-performance computational library based on XLA that can do efficient auto-vectorization and just-in-time compilation of the mathematical computations. Using these JAX features was previously recommended as a good way to speed up DP-SGD in the context of smaller datasets such as CIFAR-10.
We created our own implementation of DP-SGD on JAX and benchmarked it against the large ImageNet dataset (the code is included in our release). The implementation in JAX was relatively simple and resulted in noticeable performance gains simply because of using the XLA compiler. Compared to other implementations of DP-SGD, such as that in Tensorflow Privacy, the JAX implementation is consistently several times faster. It is typically even faster compared to the custom-built and optimized PyTorch Opacus.
Each step of our DP-SGD implementation takes approximately two forward-backward passes through the network. While this is slower than non-private training, which requires only a single forward-backward pass, it is still the most efficient known approach to train with the per-example gradients necessary for DP-SGD. The graph below shows training runtimes for two models on ImageNet with DP-SGD vs. non-private SGD, each on JAX. Overall, we find DP-SGD on JAX sufficiently fast to run large experiments just by slightly reducing the number of training runs used to find optimal hyperparameters compared to non-private training. This is significantly better than alternatives, such as Tensorflow Privacy, which we found to be ~5x–10x slower on our CIFAR10 and MNIST benchmarks.
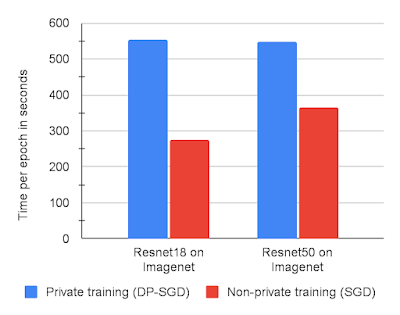 |
| Time in seconds per training epoch on ImageNet using a Resnet18 or Resnet50 architecture with 8 V100 GPUs. |
Combining Techniques for Improved Accuracy
It is possible that future training algorithms may improve DP’s privacy-utility tradeoff. However, with current algorithms, such as DP-SGD, our experience points to an engineering “bag-of-tricks” approach to make DP more practical on challenging tasks like ImageNet.
Because we can train models faster with JAX, we can iterate quickly and explore multiple configurations to find what works well for DP. We report the following combination of techniques as useful to achieve non-trivial accuracy and privacy on ImageNet:
- Full-batch training
Theoretically, it is known that larger minibatch sizes improve the utility of DP-SGD, with full-batch training (i.e., where a full dataset is one batch) giving the best utility [1, 2], and empirical results are emerging to support this theory. Indeed, our experiments demonstrate that increasing the batch size along with the number of training epochs leads to a decrease in ε while still maintaining accuracy. However, training with extremely large batches is non-trivial as the batch cannot fit into GPU/TPU memory. So, we employed virtual large-batch training by accumulating gradients for multiple steps before updating the weights instead of applying gradient updates on each training step.
Batch size 1024 4 × 1024 16 × 1024 64 × 1024 Number of epochs 10 40 160 640 Accuracy 56% 57.5% 57.9% 57.2% Privacy loss bound ε 9.8 × 108 6.1 × 107 3.5 × 106 6.7 × 104
- Transfer learning from public data
Pre-training on public data followed by DP fine-tuning on private data has previously been shown to improve accuracy on other benchmarks [3, 4]. A question that remains is what public data to use for a given task to optimize transfer learning. In this work we simulate a private/public data split by using ImageNet as "private" data and using Places365, another image classification dataset, as a proxy for “public" data. We pre-trained our models on Places365 before fine-tuning them with DP-SGD on ImageNet. Places365 only has images of landscapes and buildings, not of animals as ImageNet, so it is quite different, making it a good candidate to demonstrate the ability of the model to transfer to a different but related domain.
We found that transfer learning from Places365 gave us 47.5% accuracy on ImageNet with a reasonable level of privacy (ε = 10). This is low compared to the 70% accuracy of a similar non-private model, but compared to naïve DP training on ImageNet, which yields either very low accuracy (2 - 5%) or no privacy (ε=109), this is quite good.
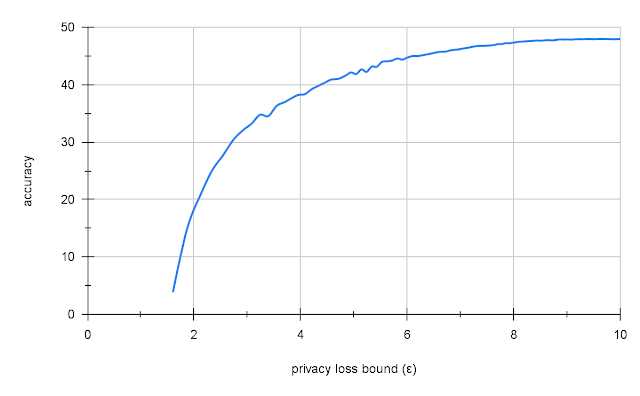 |
| Privacy-accuracy tradeoff for Resnet-18 on ImageNet using large-batch training with transfer learning from Places365. |
Next Steps
We hope these early results and source code provide an impetus for other researchers to work on improving DP for ambitious tasks such as ImageNet as a proxy for challenging production-scale tasks. With the much faster DP-SGD on JAX, we urge DP and ML researchers to explore diverse training regimes, model architectures, and algorithms to make DP more practical. To continue advancing the state of the field, we recommend researchers start with a baseline that incorporates full-batch training plus transfer learning.
Acknowledgments
This work was carried out with the support of the Google Visiting Researcher Program while Prof. Geambasu, an Associate Professor with Columbia University, was on sabbatical with Google Research. This work received substantial contributions from Steve Chien, Shuang Song, Andreas Terzis and Abhradeep Guha Thakurta.
