

Infrastructure fragmentation in Machine Learning (ML) across frameworks, compilers, and runtimes makes developing new hardware and toolchains challenging. This inhibits the industry’s ability to quickly productionize ML-driven advancements. To simplify the growing complexity of ML workload execution across hardware and frameworks, we are excited to introduce PJRT and open source it as part of the recently available OpenXLA Project.
PJRT (used in conjunction with OpenXLA’s StableHLO) provides a hardware- and framework-independent interface for compilers and runtimes. It simplifies the integration of hardware with frameworks, accelerating framework coverage for the hardware, and thus hardware targetability for workload execution.
PJRT is the primary interface for TensorFlow and JAX and fully supported for PyTorch, and is well integrated with the OpenXLA ecosystem to execute workloads on TPU, GPU, and CPU. It is also the default runtime execution path for most of Google’s internal production workloads. The toolchain-independent architecture of PJRT allows it to be leveraged by any hardware, framework, or compiler, with extensibility for unique features. With this open-source release, we're excited to allow anyone to begin leveraging PJRT for their own devices.
Vision: Simplifying ML Hardware and Framework Integration
We are entering a world of ambient experiences where intelligent apps and devices surround us, from edge to the cloud, in a range of environments and scales. ML workload execution currently supports a combinatorial matrix of hardware, frameworks, and workflows, mostly through tight vertical integrations. Examples of such vertical integrations include specific kernels for TPU versus GPU, specific toolchains to train and serve in TensorFlow versus PyTorch. These bespoke 1:1 integrations are perfectly valid solutions but promote lock-in, inhibit innovation, and are expensive to maintain. This problem of a fragmented software stack is compounded over time as different computing hardware needs to be supported.
Portability: Seamless Execution
The workflow to enable this vision with PJRT is as follows (shown in Figure 1):
- The hardware-specific compiler and runtime provider implement the PJRT API, package it as a plugin containing the compiler and runtime hooks, and register it with the frameworks. The implementation can be opaque to the frameworks.
- The frameworks discover and load one or multiple PJRT plugins as dynamic libraries targeting the hardware on which to execute the workload.
- That’s it! Execute the workload from the framework onto the target hardware.
The PJRT API will be backward compatible. The plugin would not need to change often and would be able to do version-checking for features.
 |
| Figure 1: To target specific hardware, provide an implementation of the PJRT API to package a compiler and runtime plugin that can be called by the framework. |
Cohesive Ecosystem
As a foundational pillar of the OpenXLA Project, PJRT is well-integrated with projects within the OpenXLA Project including StableHLO and the OpenXLA compilers (XLA, IREE). It is the primary interface for TensorFlow and JAX and fully supported for PyTorch through PyTorch/XLA. It provides the hardware interface layer in solving the combinatorial framework x hardware ML infrastructure fragmentation (see Figure 2).
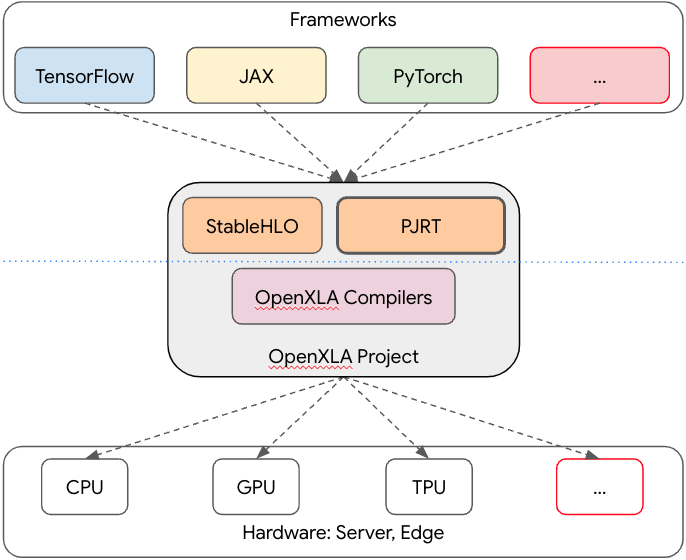 |
| Figure 2: PJRT provides the hardware interface layer in solving the combinatorial framework x hardware ML infrastructure fragmentation, well-integrated with OpenXLA. |
Toolchain Independent
Driving Impact with Collaboration
Industry partners such as Intel and others have already adopted PJRT.
Intel
Intel is leveraging PJRT in Intel® Extension for TensorFlow to provide the Intel GPU backend for TensorFlow and JAX. This implementation is based on the PJRT plugin mechanism (see RFC). Check out how this greatly simplifies the framework and hardware integration with this example of executing a JAX program on Intel GPU.
"At Intel, we share Google's vision of modular interfaces to make integration easier and enable faster, framework-independent development. Similar in design to the PluggableDevice mechanism, PJRT is a pluggable interface that allows us to easily compile and execute XLA's High Level Operations on Intel devices. Its simple design allowed us to quickly integrate it into our systems and start running JAX workloads on Intel® GPUs within just a few months. PJRT enables us to more efficiently deliver hardware acceleration and oneAPI-powered AI software optimizations to developers using a wide range of AI Frameworks." - Wei Li, VP and GM, Artificial Intelligence and Analytics, Intel.
Technology Leader
Get Involved
Acknowledgements
Allen Hutchison, Andrew Leaver, Chuanhao Zhuge, Jack Cao, Jacques Pienaar, Jieying Luo, Penporn Koanantakool, Peter Hawkins, Robert Hundt, Russell Power, Sagarika Chalasani, Skye Wanderman-Milne, Stella Laurenzo, Will Cromar, Xiao Yu.
By Aman Verma, Product Manager, Machine Learning Infrastructure